我用Python八年后学到的东西「Rosetta」
Python之禅示例、我的建议以及其他技巧和窍门!
- 原文链接: What I've learned after 8 years of Python - by Alex Razvant
- 日期: 2025年5月10日
- 作者:Alex Razvant
在这篇实用的文章中,我将阐述一套帮助我改进 Python 编程方式的最佳实践。
我并非从一开始就了解这些,但随着我职业生涯的进步,它们变得显而易见,我是通过编写代码、学习 Python 中的最佳软件原则和简洁代码概念间接学到的。
让我们从几个有趣的图表开始!
Python 的受欢迎程度
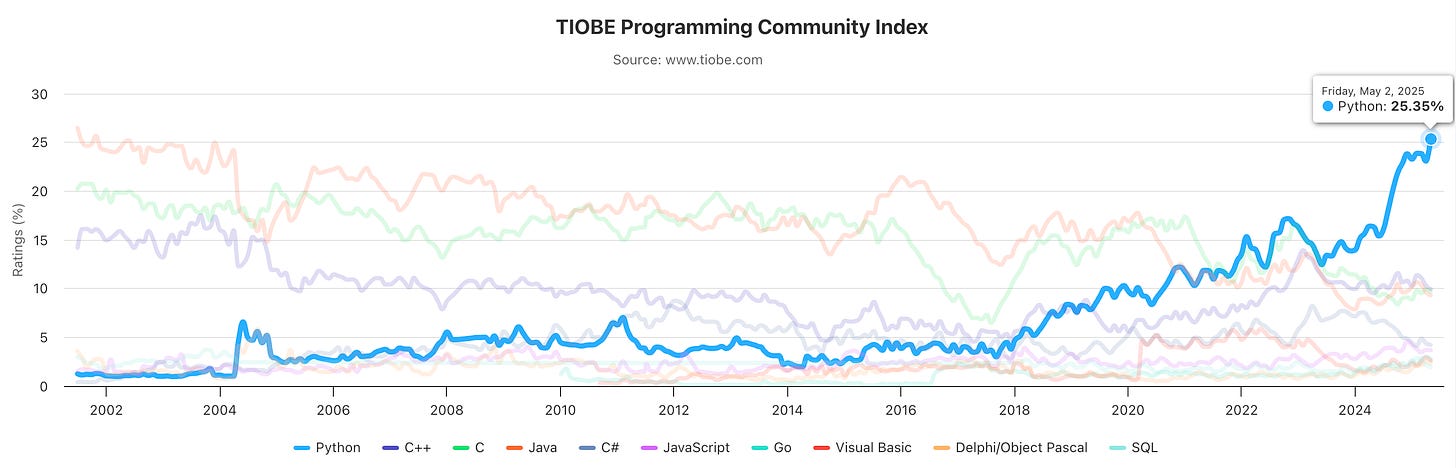
2025年 TIOBE 指数记录。(https://www.tiobe.com/tiobe-index/)
甚至在人工智能领域飞速发展之前,Python 就已经是开发者中广受欢迎的语言。它拥有清晰易懂的语法,使得各种经验水平的人都能快速学习并提高生产力。
由于 Python 解释器的存在,它具有可移植性,因此跨平台开发不会涉及编译器版本或其他障碍。
随着人工智能的兴起,Python 变得更加流行,谷歌的 Tensorflow 团队和 Meta 的 PyTorch 团队等大型团队都选择了 Python 优先的方法。一个快速发展的领域需要一种简化的方法,而 Python 正好适合。
此外,许多其他工具、开源框架和库也积极响应,并以 Python 优先的理念进行构建。让我们看几个例子:
- Pandas
- PyTorch (C++, Python)
- Tensorflow, Keras (C++, Python)
- Polars (后端 Rust, API Python)
- Bytewax (后端 Rust, API Python)
- HuggingFace Transformers
- OpenAI GPU Triton Lang
- Langchain, Langgraph, vLLM, SGLang, TRTLLM
- 等等,不胜枚举……
随着越来越多的公司使用人工智能进行构建,寻找在驱动人工智能的技术(包括精通 Python)方面经验丰富的开发人员,就变得理所当然了。这是来自 2024 年 StackOverflow 开发者调查的另一张图表,再次印证了上述观点。
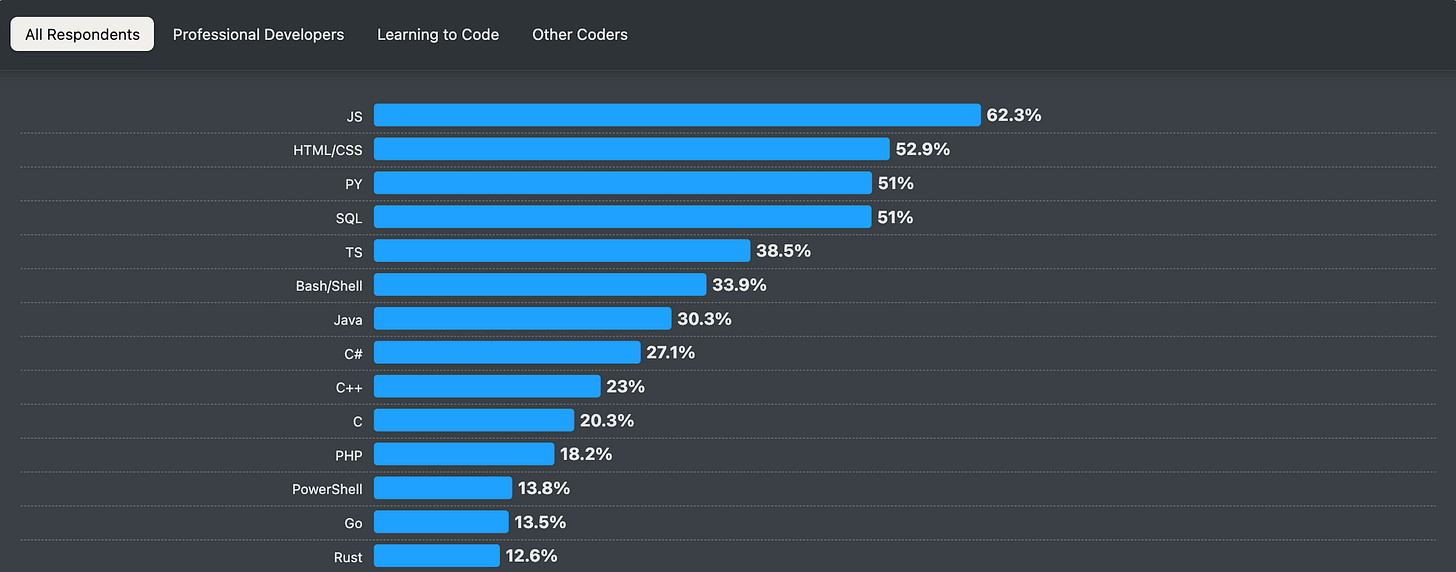
既然已经确定 Python 是目前最热门的语言之一,我想重申一些我在职业生涯中学到的、对我帮助很大的原则。
Python之禅
想要一个彩蛋吗? 在你的 Python 终端中,输入
import this,你就会看到 Tim Peters 写的 Python之禅。
Python之禅 是为编写计算机程序而设定的19条“指导原则”的集合,这些原则影响了Python 编程语言的设计。符合这些原则的 Python 代码通常被称为“Pythonic”(Python风格的)。

它是这样说的:
- 优美胜于丑陋。
- 明确胜于隐晦。
- 简单胜于复杂。
- 复杂胜于繁复。
- 扁平胜于嵌套。
- 稀疏胜于密集。
- 可读性很重要。
- 特殊情况不足以特殊到打破规则。
- 尽管实用性胜过纯粹性。
- 错误不应该悄无声息地忽略。
- 除非明确地使其保持沉默。
- 面对模棱两可,拒绝猜测的诱惑。
- 应该有一种——最好只有一种——显而易见的方法来做这件事。
- 尽管这种方法一开始可能并不那么显而易见,除非你是荷兰人。
- 现在胜于永不。
- 尽管永不常常胜过立即行动。
- 如果实现很难解释,那就是个坏主意。
- 如果实现很容易解释,那可能是个好主意。
- 命名空间是个绝妙的主意——我们应该多多使用它!
- 第20条本应由 Python 语言的创造者 Guido 撰写,但从未完成。
让我们一步步来解读它们。
优美且明确
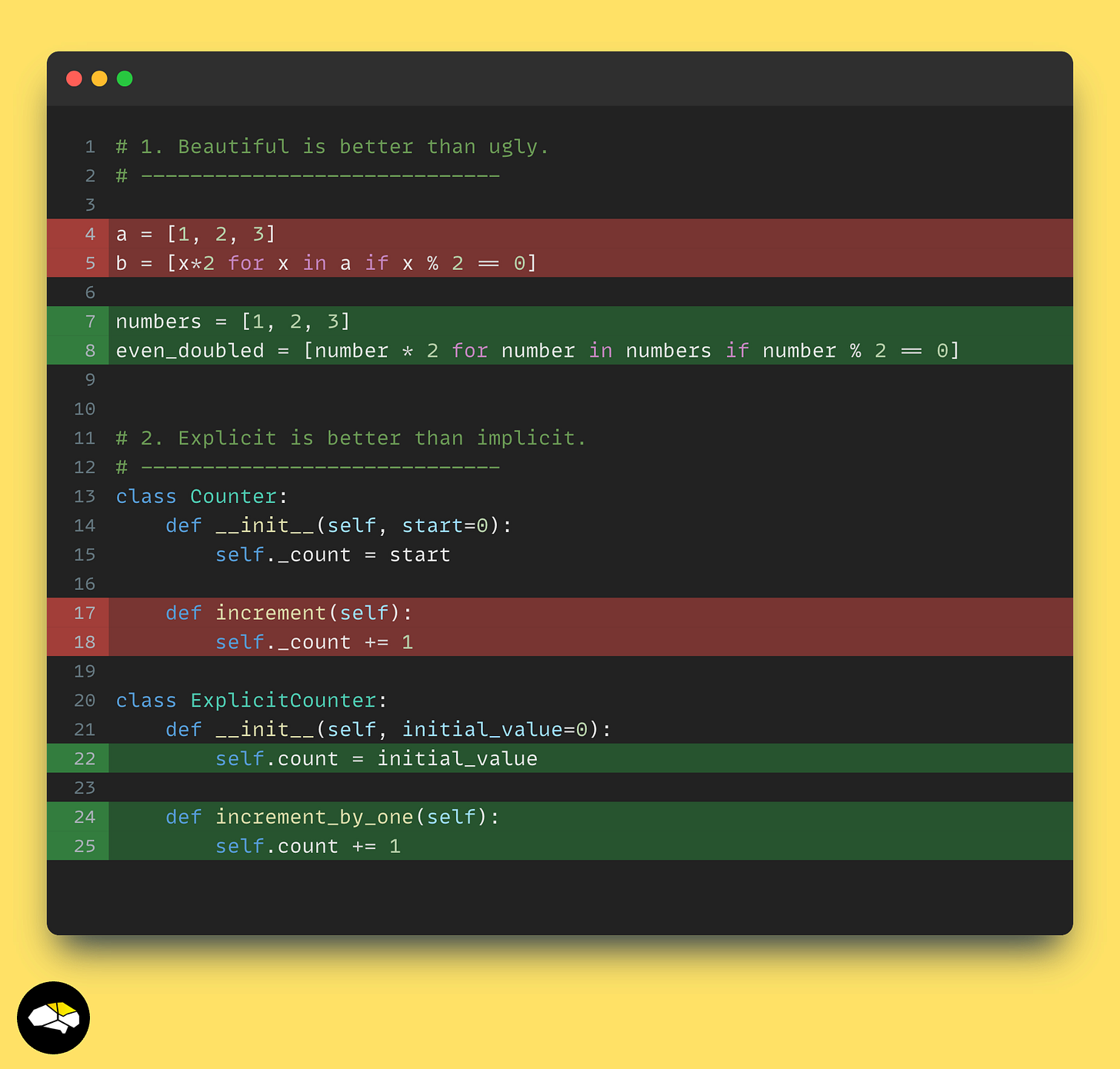
多个概念都融入了这一点。从你如何命名变量,如何划分代码块的逻辑,如何编写文档字符串,传递参数,将参数绑定到类型等等。
让你的代码明确。如果功能在一个类内部发生,要清楚地说明该方法做了什么以及更新了哪些变量。
简单胜于复杂,复杂胜于繁复

过度设计是所有开发人员都牢记于心的概念,而且我们都曾这样做过。编程是一门艺术,我们希望它看起来不错,但我们不应该忽略代码的目的是运行并解决问题。
当然,拥有继承、嵌套块和复杂的类看起来很棒,并且可能暗示“嘿,这设计太棒了”,但功能应该是健壮的,不需要在其之上堆砌大量层次。
保持简单,避免过度设计!
可读性,扁平优于嵌套

Python 是一种动态类型语言,可以让你快速完成工作。当你编写 Python 代码时,你应该致力于隔离每个方法和代码块的逻辑,使其首先具有可读性,即使这需要多行代码。诚然,某些功能可能可以用一行代码完成,但你写的行数越少,可能遇到的错误就越多。
此外,请记住,当你在团队中工作时,其他人会阅读你的代码,你肯定不希望你的 PR(合并请求)收到大量评论。其他人没有你对那段代码的上下文,所以他们应该能够简单快速地理解它。
错误不应该悄无声息地忽略!
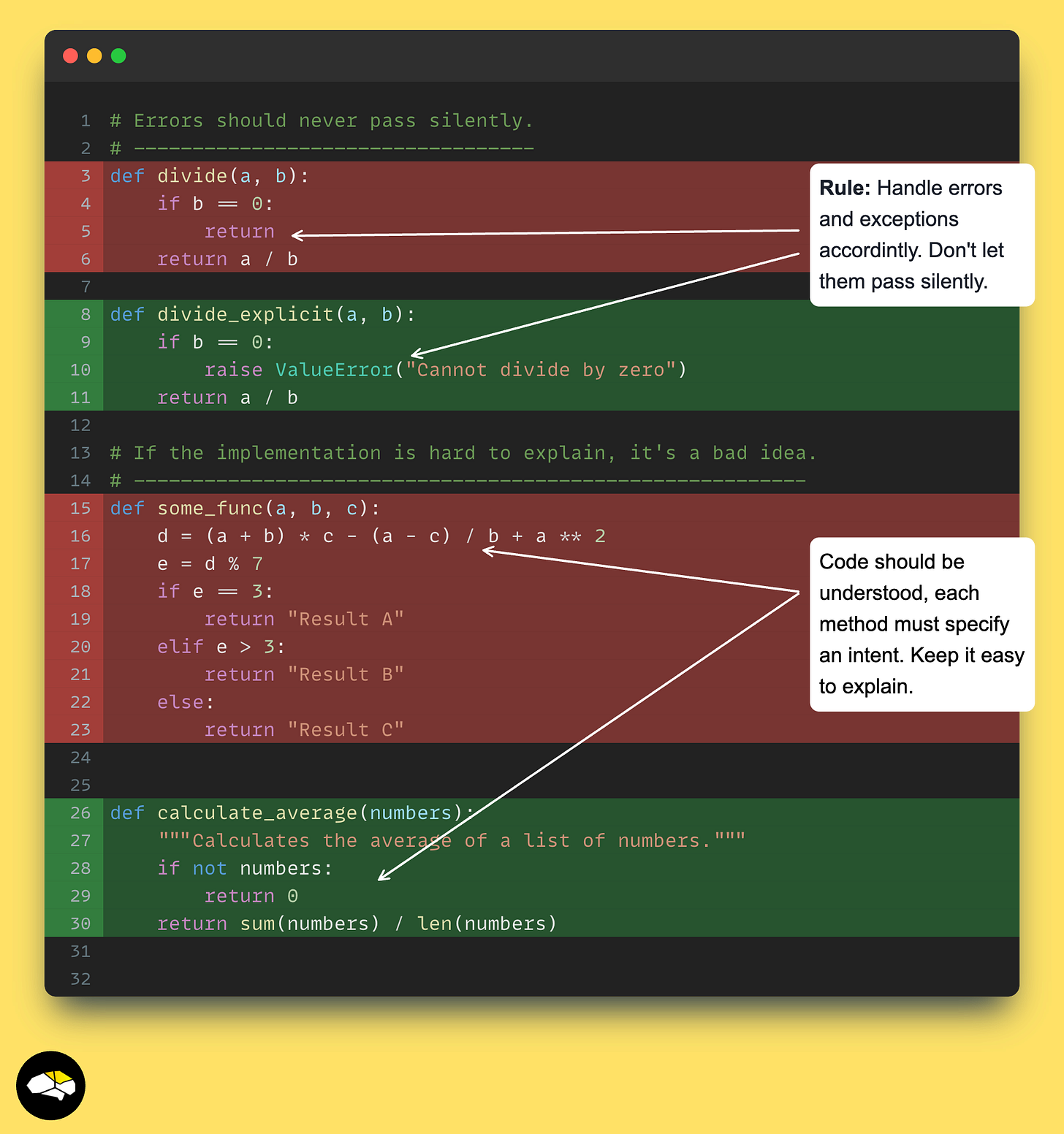
当你编写 Python 代码时,始终致力于使用内置异常来处理边缘情况并相应地处理异常。如果你正在从文件中读取,不要假设文件总是存在。添加一个 FileNotFoundException 来处理文件丢失的情况。
此外,如果你正在解析 JSON 或任何其他对象,请使用 ValueError 来处理缺失的键或错误的解析。这样的例子不胜枚举,但重要的是,你应该致力于捕获和处理你的代码可能遇到的异常。
如果你对任何异常没有特定的处理逻辑,请使用 logger.error 记录它,以便在你的命令行界面或 .log 文件中看到该消息。
使用命名空间!
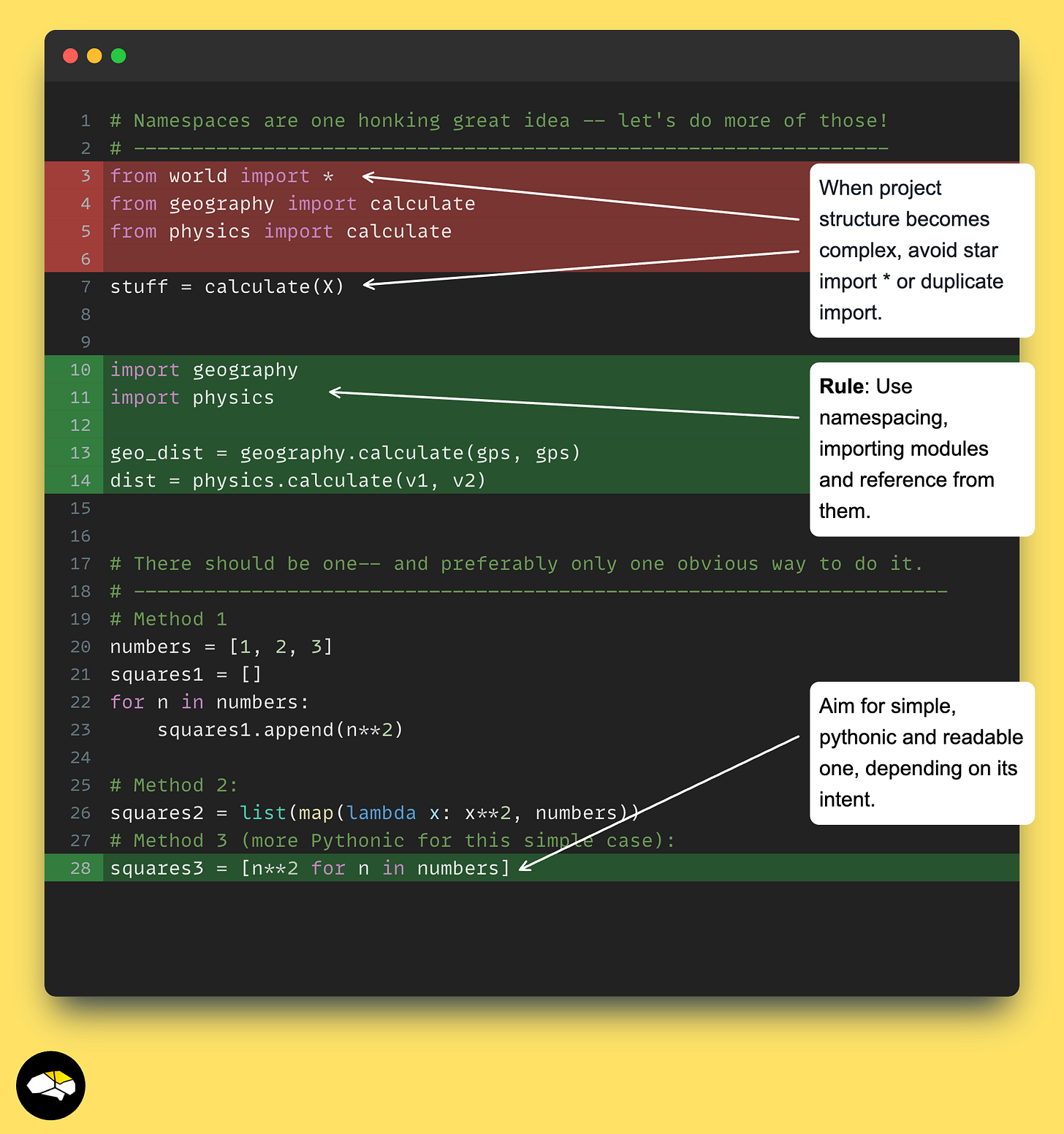
这是我在 GitHub 上的许多开源项目中看到的一个关键点。规则是避免星号导入(from X import *)或多模块导入,因为某些方法可能具有冲突的名称。请改用命名空间。
不要导入特定的方法,而是导入模块,并仅从该模块内部引用方法。这里有更多例子:
import utils
result = utils.my_func()
import tools
result = tools.my_func()
关于所有这些主题,我有一个很棒的书籍推荐:Fluent Python!
环境和包管理器
在 Python 开发中,高效管理项目依赖和 Python 版本是强制性的。虚拟环境为每个项目提供隔离的空间,防止不同项目需求之间的冲突。
为了在这些环境中安装、更新和删除库,我们会使用 Python 包管理器。在很长一段时间里,常用的方法有:
- Virtualenv 和 pip install requirements.txt
- Poetry 和 Pyproject.toml
- Conda
从我开始使用 Python 的第一年起,我就一直在使用所有这些方法或其变体。但是,目前,我已经转向了最新的工具——uv,并且再也没有回头。
uv 工具 是一个用于 Python 的高速包和项目管理器。它用 Rust 编写,可以完成上述所有解决方案所做的一切,但速度要快得多。它提供快速的依赖安装,并将各种功能集成到一个工具中。
你可以用以下命令安装它:curl -LsSf https://astral.sh/uv/install.sh | sh
UV 入门
开始时需要遵循3个步骤:
- 使用
uv init <name>创建一个新项目 - 使用
cd <name> && uv init初始化一个新的虚拟环境 - 使用
uv add <pkg_name>开始向你的环境添加包
就这样,现在你可以激活虚拟环境并使用特定的解释器工作了。
cd <name>
source .venv/bin/activate
uv sync
充分利用 UV
以下是 UV 提供的命令和功能列表,涵盖多种用例,从在 Dockerfile 内部使用,到为你的包构建可分发的 wheel (.whl) 文件,或在 [dev]、[prod] 或 test 中分离依赖组。

额外建议
对于一些额外的建议,我推荐使用静态类型、Python 内置标志以及用于模式验证的 Dataclasses 或 Pydantic 模型。
静态类型
不要这样做,如果 data 参数不是字典,这很容易出错:
def process_data(data):
for item in data:
name = item['name']
value = item['value'] * 2
print(f"{name}: {value}")
这样做,指定类型和预期的模式:
from typing import List, TypedDict
class DataItem(TypedDict):
name: str
value: int
def process_data(data: List[DataItem]) -> None:
for item in data:
name: str = item['name']
value: int = item['value'] * 2
print(f"{name}: {value}")
my_data = [
{'name': 'A', 'value': 5},
{'name': 'B', 'value': 10}
]
process_data(my_data)
更进一步,Pydantic 模式验证
上面的代码示例可以通过使用 Pydantic 模型作为验证模式再改进一步,因此,不要这样:
from typing import List, TypedDict
class DataItem(TypedDict):
name: str
value: int
def process_data(data: List[DataItem]) -> None:
for item in data:
name: str = item['name']
value: int = item['value'] * 2
print(f"{name}: {value}")
my_data = [{'name': 'A', 'value': 5}, {'name': 'B', 'value': 10}]
process_data(my_data)
这样做,我们根据 Pydantic 中的 BaseModel 验证 DataItem:
from typing import List
from pydantic import BaseModel, field_validator
class DataItem(BaseModel):
name: str
value: int
@field_validator("name")
def val_name(cls, v: str): # 注意:Pydantic v2 中验证器是类方法,第一个参数通常是 cls
if v in ["A", "B"]:
return v
else:
return "NONE"
def process_data(data: List[DataItem]) -> None:
for item in data:
name: str = item.name
value: int = item.value * 2
print(f"{name}: {value}")
my_data = [
DataItem(name="A", value=5),
DataItem(name="B", value=10)
]
process_data(my_data)
所以在这里,我们使用了一个带有 field_validator 的 BaseModel,它表示对于 "A" 和 "B",DataItem 是有效的,因为 name 字段的任何其他值都会将 name 字段转换为 "NONE"。
当然,这是一个基础示例,但它说明了重点,因为使用 Pydantic 模型,我们不仅强调类型,还可以添加验证、字段描述、默认值等等。
最后的想法
本文描述的列表只涉及了几个方面,因为关于如何编写简洁的 Python 代码,市面上有很多指南。
我想让它简短而实用,提供代码示例来说明每个主题。