「Sutton」奖励已足够
- 作者:David Silver ∗, Satinder Singh, Doina Precup, Richard S. Sutton
- 原文连接:Reward is Enough
摘要
在本文中,我们假设智能及其相关能力可以被理解为服务于奖励的最大化。因此,奖励足以驱动表现出自然和人工智能中研究的能力的行为,包括知识、学习、感知、社会智能、语言、泛化和模仿。这与这样一种观点形成对比:即每种能力都需要专门的问题公式,基于其他信号或目标。此外,我们建议通过试错经验学习以最大化奖励的智能体可以学习表现出大多数(如果不是全部)这些能力的行为,因此强大的强化学习智能体可以构成通用人工智能的解决方案。
2021 The Authors. Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/).
1. 介绍
动物和人类行为中智能的表现是如此丰富和多样,以至于存在一个相关能力的本体来命名和研究它们,例如社会智能、语言、感知、知识表示、规划、想象力、记忆和运动控制。是什么可以驱动智能体(自然的或人工的)以如此多种不同的方式表现得智能化?
一种可能的答案是,每种能力都来自于追求专门设计用于引发该能力的目标。例如,社会智能的能力通常被定义为多智能体系统的纳什均衡;语言的能力由诸如解析、词性标注、词汇分析和情感分析等目标的组合来定义;感知的能力由对象分割和识别来定义。在本文中,我们考虑一个替代假设:最大化奖励的通用目标足以驱动表现出自然和人工智能中研究的大多数(如果不是全部)能力的行为。
这个假设可能会让人吃惊,因为与智能相关的能力的巨大多样性似乎与任何通用目标都不一致。然而,动物和人类所面对的自然世界,以及假定的人工智能体在未来所面临的环境,本质上是如此复杂,以至于它们需要复杂的能力才能在这些环境中取得成功(例如,生存)。因此,以最大化奖励衡量的成功需要与智能相关的各种能力。在这样的环境中,任何最大化奖励的行为必然会表现出这些能力。从这个意义上说,奖励最大化的通用目标包含许多甚至可能所有智能的目标。
因此,奖励为自然界中发现的智能的丰富表现提供了两个层次的解释。首先,不同形式的智能可能来自于在不同环境中最大化不同的奖励信号,例如导致蝙蝠的回声定位、鲸歌的交流或黑猩猩的工具使用等不同的能力。同样,人工智能体可能需要在未来的环境中最大化各种奖励信号,从而产生新的智能形式,其能力与基于激光的导航、电子邮件通信或机器人操作一样独特。
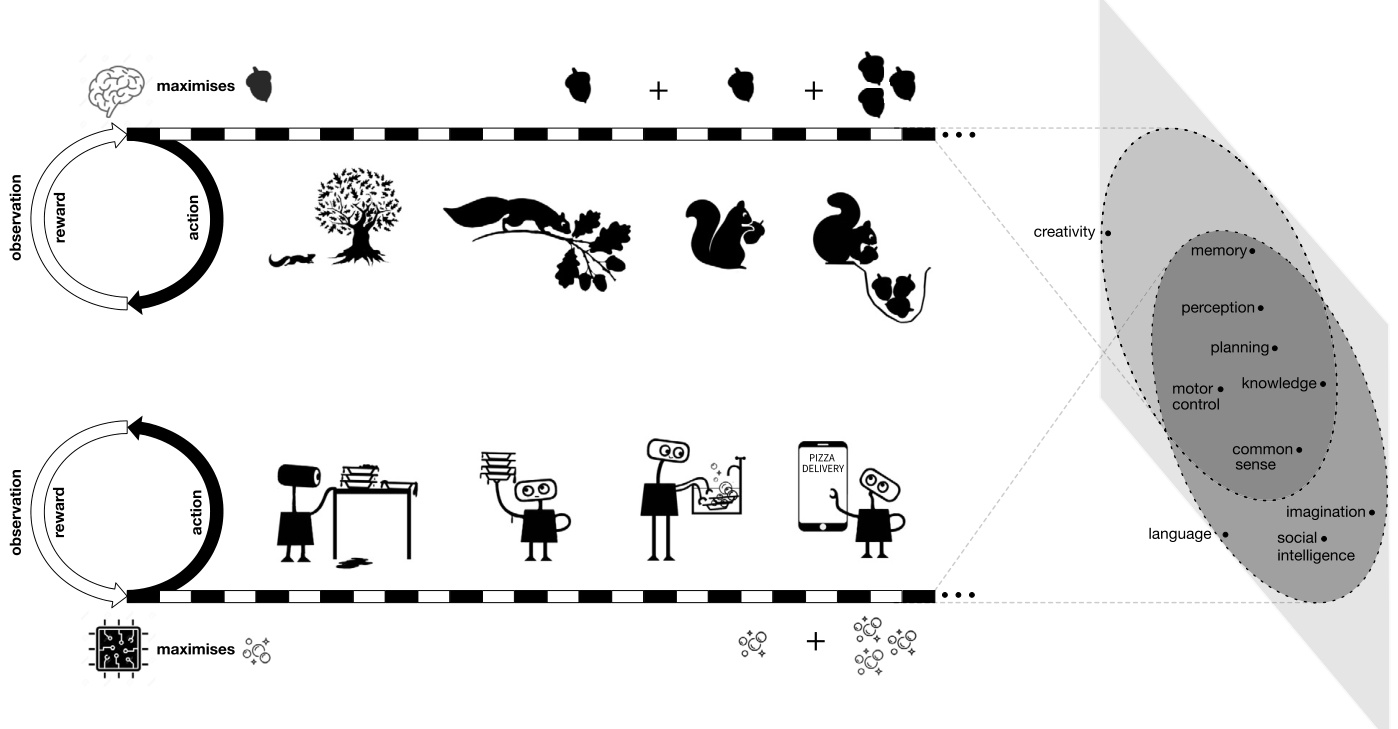 图 1. 奖励即足够假设认为,智能及其相关能力可以被理解为服务于智能体在其环境中行动以最大化奖励。例如,松鼠的行为是为了最大化其食物消耗(顶部,奖励用橡子符号表示),或者厨房机器人的行为是为了最大化清洁度(底部,奖励用气泡符号表示)。为了实现这些目标,需要复杂的行为,这些行为表现出与智能相关的各种能力(在右侧被描述为从智能体的经验流到在该经验中表达的一组能力的投影)。
图 1. 奖励即足够假设认为,智能及其相关能力可以被理解为服务于智能体在其环境中行动以最大化奖励。例如,松鼠的行为是为了最大化其食物消耗(顶部,奖励用橡子符号表示),或者厨房机器人的行为是为了最大化清洁度(底部,奖励用气泡符号表示)。为了实现这些目标,需要复杂的行为,这些行为表现出与智能相关的各种能力(在右侧被描述为从智能体的经验流到在该经验中表达的一组能力的投影)。
其次,即使是单个动物或人类的智能也与大量能力相关联。根据我们的假设,所有这些能力都服务于最大化该动物或智能体在其环境中的奖励的单一目标。换句话说,追求一个目标可能会产生复杂的行为,从而表现出与智能相关的多种能力。事实上,这种最大化奖励的行为可能经常与从追求与每种能力相关的单独目标中获得的特定行为一致。
例如,松鼠的大脑可以被理解为一个决策系统,该系统接收来自松鼠身体的感觉并向其发送运动命令。松鼠的行为可以被理解为最大化诸如饱腹感(即负饥饿)之类的累积奖励。为了使松鼠最大程度地减少饥饿,松鼠的大脑可能必须具有感知能力(以识别好坚果)、知识(以了解坚果)、运动控制(以收集坚果)、计划(以选择在哪里藏坚果)、记忆(以回忆藏坚果的位置)和社会智能(以虚张声势关于藏坚果的位置,以确保它们不被盗)。因此,与智能相关的每种能力都可以被理解为服务于最大程度地减少饥饿的单一目标(见图 1)。
第二个例子,厨房机器人可以实现为一个决策系统,该系统接收来自机器人身体的感觉并向其发送执行器命令。厨房机器人的单一目标是最大化衡量清洁度的奖励信号。1为了使厨房机器人最大化清洁度,它可能必须具有感知能力(以区分干净和脏的用具)、知识(以了解用具)、运动控制(以操纵用具)、记忆(以回忆用具的位置)、语言(以预测对话中未来的混乱)和社会智能(以鼓励幼儿减少混乱)。因此,最大化清洁度的行为必须产生所有这些能力以服务于该单一目标(见图 1)。
当与智能相关的能力作为最大化奖励的单一目标的解决方案出现时,这实际上可能会提供更深入的理解,因为它解释了为什么会出现这种能力(例如,鳄鱼的分类对于避免被吃掉很重要)。相反,当每种能力都被理解为针对其自身特定目标的解决方案时,为了专注于该能力的作用(例如,将鳄鱼与原木区分开),便避开了为什么这个问题。此外,单一目标还可以提供对每种能力的更广泛的理解,其中可能包括其他难以形式化的特征,例如在社会智能中处理非理性智能体(例如,安抚愤怒的侵略者),将语言与感知体验联系起来(例如,关于剥水果的最佳方法的对话),或理解感知中的触觉(例如,从口袋中挑选出一个尖锐的物体)。最后,以服务于单一目标而非其自身特定目标的方式实现能力,也回答了如何整合能力的问题,否则这仍然是一个悬而未决的问题。
已经确定了奖励最大化是理解智能问题的合适目标,人们可能会考虑解决该问题的方法。然后,人们可能会期望在自然智能中找到此类方法,或者选择在人工智能中实现它们。在最大化奖励的可能方法中,最通用和可扩展的方法是通过与环境进行试错互动来学习这样做。我们推测,能够有效地学习以这种方式最大化奖励的智能体,当置于丰富的环境中时,将产生通用智能的复杂表达。
最近一个基于奖励最大化的问题和解决方案的有益示例来自围棋游戏。最初的研究主要集中在不同的能力上,例如开局、形状、战术和残局,每种能力都使用不同的目标进行形式化,例如序列记忆、模式识别、局部搜索和组合博弈论 [32]。 AlphaZero [49] 而是专注于一个单一目标:最大化奖励信号,该信号在最后一步之前为 0,然后对于获胜为 ,对于失败为 。这最终导致了对每种能力的更深入的理解——例如,发现新的开局序列 [65],在全球范围内使用令人惊讶的形状 [40],理解局部战斗之间的全球互动 [64],以及在领先时安全地进行游戏 [40]。它还产生了一组更广泛的能力,这些能力以前尚未得到令人满意的形式化——例如平衡影响力和领地、厚度和轻盈性以及进攻和防守。 AlphaZero 的能力天生就被整合为一个统一的整体,而整合在先前的工作中已被证明是高度有问题的 [32]。因此,在像围棋这样的简单环境中,最大化胜利足以驱动表现出各种专业能力的行为。此外,将相同的方法应用于不同的环境,例如国际象棋或将棋 [48],会产生新的能力,例如棋子机动性和颜色复合体 [44]。我们认为,在更丰富的环境中——在复杂性上更接近动物和人类所面对的自然世界——最大化奖励可以产生更多,甚至可能最终产生与智能相关的所有能力。
本文的其余部分组织如下。在第 2 节中,我们将奖励最大化的目标形式化为强化学习问题。在第 3 节中,我们提出了我们的主要假设。我们考虑与智能相关的几个重要能力,并讨论奖励最大化如何产生这些能力。在第 4 节中,我们转向使用奖励最大化作为解决方案策略。我们在第 5 节中介绍了相关工作,最后,在第 6 节中,我们讨论了该假设的可能弱点并考虑了几个替代方案。
2. 背景:强化学习问题
智能可以被理解为实现目标的灵活能力。例如,根据约翰·麦卡锡的说法,“智能是在世界中实现目标的计算部分的能力”[29]。强化学习 [56] 将寻求目标的智能问题形式化。可以使用广泛而实际的目标和世界范围来实例化通用问题——因此,各种形式的智能——对应于在不同环境中最大化的不同奖励信号。
2.1. 智能体和环境
与许多交互式人工智能方法 [42] 一样,强化学习遵循一种协议,该协议将问题解耦为两个系统,这两个系统随时间顺序交互:智能体(解决方案),做出决策;环境(问题),受到这些决策的影响。这与其他专业协议形成对比,这些协议可能会考虑多个智能体、多个环境或其他交互模式。
2.2. 智能体
智能体是在时间 接收到观察 并输出动作 的系统。更正式地说,智能体是一个系统 ,它在时间 t 给定其经验历史 选择动作 ,换句话说,给定智能体和环境之间交互历史中发生的观察和动作序列。
智能体系统 受到实际约束的限制,只能达到有界集合 [43]。智能体具有受其机器(例如,计算机中有限的内存或大脑中有限的神经元)限制的容量。智能体和环境系统实时执行。当智能体花费时间计算其下一个动作时(例如,在决定是否逃离狮子时产生空操作),环境系统会继续处理(例如,狮子会攻击)。因此,强化学习问题代表了一个实际问题,正如自然和人工智能所面临的那样,而不是忽略计算限制的理论抽象。
本文不深入探讨智能体的本质,而是专注于它必须解决的问题以及任何问题解决方案可能引起的智能。
表1 环境的定义是广泛的,涵盖了许多问题维度。
| 维度 | 备选方案A | 备选方案B | 注释 |
| 观察 | 离散 | 连续 | |
| 动作 | 离散 | 连续 | |
| 时间 | 离散 | 连续 | 时间步长可以是无穷小 |
| 动态 | 确定性 | 随机 | |
| 可观察性 | 完全 | 部分 | |
| 代理 | 单一智能体 | 多智能体 | 从单一智能体的角度来看,其他智能体是环境的一部分(参见第3.3节) |
| 不确定性 | 确定 | 不确定 | 不确定性可以用随机初始状态或转换来表示 |
| 终止 | 持续 | 情节式 | 环境可能终止并重置为初始状态 |
| 平稳性 | 平稳 | 非平稳 | 环境取决于历史,因此也取决于时间 |
| 同步 | 异步 | 同步 | 在执行动作之前,观察可能保持不变 |
| 现实 | 模拟 | 真实世界 | 可能包括与智能体交互的人类 |
2.3. 环境
环境是一个系统,它在时间 t 接收动作 并在下一个时间步以观察 作为响应。更正式地说,环境是一个系统 ,它确定智能体将从环境接收的下一个观察 ,给定经验历史 、最新的动作 以及潜在的随机源 。
环境在其定义中指定了与智能体的接口。智能体仅由决策实体组成;该实体之外的任何事物(包括其身体,如果有的话)都被视为环境的一部分。这包括定义智能体的观察结果的传感器和执行器以及智能体可用的动作。
请注意,环境的这个定义非常广泛,涵盖了许多问题维度,包括表 1 中的维度。
2.4. 奖励
强化学习问题通过累积奖励表示目标。奖励是一种特殊的标量观察 ,由环境中奖励信号在每个时间步 t 发出,它提供了实现目标的即时进度测量。强化学习问题的一个实例由具有奖励信号的环境 和要最大化的累积目标定义,例如有限步数的奖励总和、折扣总和或每个时间步的平均奖励。
多种目标可以用奖励来表示。2 例如,标量奖励信号可以表示目标的加权组合、随时间的不同权衡以及风险偏好或风险厌恶效用。奖励也可以由人在环中确定,例如,人类可以提供对所需行为的明确强化、通过点击或赞的在线反馈、通过问卷调查或调查的延迟反馈或通过自然语言话语。包括来自人类的反馈可以提供一种机制来制定看似模糊的目标,例如“当我看到它时我会知道”。
除了其通用性之外,奖励还在朝着目标前进的过程中提供了中间反馈,可能会在每个时间步都提供。当考虑长时间或无限的体验流时,此中间信号是问题定义的重要组成部分——如果没有中间反馈,学习是不可能的。
3. 奖励即足够
在上一节中,我们已经看到,奖励足以表达各种各样的目标,对应于智能可能针对的不同目的。
我们现在拥有了所有要素来阐明我们的主要观点:许多不同形式的智能可以被理解为服务于奖励的最大化,并且与每种智能形式相关的许多能力可能会从对这些奖励的追求中隐式地产生。达到极限,我们假设所有智能及其相关能力都可以通过这种方式来理解:
假设(奖励即足够)。智能及其相关能力可以被理解为服务于智能体在其环境中行动以最大化奖励。
这个假设很重要,因为如果它是真的,它表明一个好的奖励最大化智能体,为了实现其目标,可以隐式地产生与智能相关的能力。在这种情况下,一个好的智能体是指成功地——可能使用尚未发现的算法——在最大化其环境中的累积奖励方面表现出色的智能体。我们将在第 4 节中回到如何构建这种智能体的问题。
原则上,任何行为都可以通过明确选择来诱导该行为的奖励信号的最大化来编码 [12](例如,当正确识别对象或生成语法正确的句子时提供奖励)。这里的假设旨在更加有力:智能和相关能力将隐式地产生于最大化许多可能的奖励信号中的一个,对应于自然或人工智能可能针对的许多实用目标。
复杂的环境可能会从简单奖励的最大化中产生复杂的能力。例如,在松鼠的自然环境中减少饥饿需要熟练地操纵坚果的能力,这种能力来自于松鼠的肌肉骨骼动力学(包括其他因素)之间的相互作用;树叶、树枝或土壤等物体,松鼠或坚果可能位于其上、连接到或被其阻碍;坚果的大小和形状的变化;诸如风、雨或雪之类的环境因素;以及由于衰老、疾病或受伤而引起的变化。同样,厨房机器人对清洁度的追求需要一种复杂的能力,以感知各种状态下的器具,包括杂乱、遮挡、眩光、结壳、损坏等等。
此外,通过松鼠(例如最大化生存时间、最小化疼痛或最大化繁殖成功率)或厨房机器人(例如最大化健康饮食指标、最大化用户的积极反馈或最大化其胃肠道内啡肽)以及在许多其他环境中(例如不同的栖息地、其他灵巧的身体或其他气候)最大化许多其他奖励信号,也将产生感知、运动、操作等能力。因此,通向通用智能的道路实际上对于奖励信号的选择可能相当稳健。事实上,产生智能的能力通常可能与其给定的目标是正交的,因为在许多不同环境中最大化许多不同的奖励信号可能会产生与智能相关的相似能力。
在以下各节中,我们将探讨是否以及如何在实践中将此假设应用于各种重要能力,包括一些看似难以形式化为强化学习问题的能力。我们不提供对与智能相关的所有能力的详尽讨论,但鼓励读者考虑诸如记忆、想象力、常识、注意力、推理、创造力或情感等能力,以及这些能力如何服务于奖励最大化的通用目标。
3.1. 奖励足以获得知识和学习
我们将知识定义为智能体内部的信息;例如,知识可能包含在智能体的用于选择动作、预测累积奖励或预测未来观察特征的函数的参数中。其中一些知识可能是先天的(先验知识),而另一些知识可能是通过学习获得的。
环境可能需要先天知识。特别是,为了最大化总奖励,可能需要在新情况下立即访问知识。例如,一只新生的小羚羊可能需要逃离狮子。在这种情况下,在有机会学习这种知识之前,对捕食者逃避的先天理解可能是必要的。但是,请注意,先验知识的范围在理论上(受智能体能力的限制)和实践上(受构造有用的先验知识的难度的限制)都是有限的。此外,与我们将要考虑的其他能力不同,对先天知识的环境需求无法操作化;它是经验之前的知识,因此无法从经验中获得。
环境也可能需要学习知识。当由于环境的未知元素、随机性或复杂性而导致未来体验不确定时,就会发生这种情况。这种不确定性导致智能体可能需要的各种各样的潜在知识,这取决于智能体对未来事件的特定实现。在丰富的环境中,包括自然和人工智能中最困难和最重要的问题,潜在知识的总空间远大于智能体的能力。例如,考虑一下早期人类的环境。智能体可能出生在北极或非洲,从而导致对知识的需求截然不同,以最大化总奖励:面对北极熊或狮子;穿越冰川或稀树草原;用冰或泥建造;等等。智能体生活中的特定事件也可能导致截然不同的需求:选择狩猎或耕种;面对蝗虫或战争;失明或失聪;遇到朋友或敌人;等等。在每个可能的生命中,智能体必须获得详细和专业的知识。如果这种潜在知识的总和超过了智能体的能力,那么知识必须是智能体经验的函数,并适应智能体的特定情况——因此需要学习。在实践中,这种学习可能采用多种计算形式,例如通过参数的适应或结构的构造、管理和重用来做出预测、模型或技能。
总而言之,环境可能需要先天知识和学习知识,并且一个奖励最大化的智能体将在需要时始终包含前者(例如,通过自然智能体中的进化和人工智能体中的设计)并获取后者(通过学习)。在更丰富和更长寿命的环境中,需求平衡越来越倾向于学习知识。
3.2. 奖励足以获得感知
人类世界需要各种感知能力才能积累奖励。一些生死攸关的例子包括:图像分割以避免从悬崖上掉下来;对象识别以分类健康和有毒的食物;面部识别以区分朋友和敌人;驾驶时的场景解析;或语音识别以理解“闪开!”的口头警告。可能需要几种感知模式,包括视觉、听觉、嗅觉、体感或本体感觉。
历史上,这些感知能力是使用单独的问题定义来制定的 [9]。最近,人们越来越倾向于将感知能力统一为监督学习问题的解决方案 [24]。该问题通常被形式化为最小化测试集中示例的分类错误,给定正确标记示例的训练集。将许多感知能力统一为监督学习问题已在各种现实世界应用程序中取得了相当大的成功,在这些应用程序中可以获得大量数据集 [23,15,8]。
根据我们的假设,我们建议感知可以被理解为服务于奖励的最大化。例如,上面列出的感知能力可能会隐式地产生,以服务于最大化健康食品、避免事故或最小化疼痛。事实上,在某些动物中,感知已被证明与奖励最大化一致 [46,16]。从奖励最大化的角度而不是监督学习来考虑感知,最终可能会支持更广泛的感知行为,包括具有挑战性的和现实的感知能力形式:
- 动作和观察通常交织成主动感知形式,例如触觉感知(例如,通过移动指尖来识别口袋中的内容)、视觉扫视(例如,移动眼睛以在蝙蝠和球之间切换焦点)、物理实验(例如,用石头击打坚果以查看是否会破裂)或回声定位(例如,以不同的频率发出声音并测量后续回声的定时和强度)。
- 感知的效用通常取决于智能体的行为——例如,错误分类鳄鱼的成本取决于智能体是在行走还是在游泳,以及智能体随后会战斗还是逃跑。
- 获取信息可能存在显性或隐性成本(例如,转头并检查捕食者是否存在能量、计算和机会成本)。
- 数据的分布通常与上下文相关。例如,北极智能体可能需要对冰和北极熊进行分类,其奖励取决于此;而非洲智能体可能需要对稀树草原和狮子进行分类。潜在数据的多样性在丰富的环境中可能远远超过智能体的能力或预先存在的数据量(参见第 3.1 节)——需要从经验中学习感知。
- 感知的许多应用都无法访问标记数据。
3.3. 奖励足以获得社会智能
社会智能是理解和有效地与其他智能体交互的能力。这种能力通常使用博弈论形式化为多智能体博弈的均衡解。均衡解被认为是理想的,因为它们对偏差或最坏情况具有鲁棒性。例如,纳什均衡是所有智能体的联合策略,这样单方面偏差不会给偏差者带来好处 [33]。在零和博弈中,纳什均衡也是最小最大最优的 [34]:它以最坏情况的对手获得最佳可能值。
根据我们的假设,社会智能可以被理解为,并通过最大化环境中包含其他智能体的一个智能体的累积奖励来实现。遵循这个标准的智能体-环境协议,一个智能体观察其他智能体的行为,并且可以通过其动作影响其他智能体,就像它观察和影响其环境的任何其他方面一样。可以预测和影响其他智能体行为的智能体通常可以获得更大的累积奖励。因此,如果环境需要社会智能(例如,因为它包含动物或人类),则奖励最大化将产生社会智能。
环境也可能需要鲁棒性,例如当环境包含多个遵循不同策略的智能体时。如果这些其他智能体是别名(即,没有办法提前识别其他智能体会遵循哪些策略),那么奖励最大化智能体必须对自己的赌注进行对冲,并选择一种对任何这些潜在策略都有效的稳健行为。此外,其他智能体的策略可能是自适应的。这意味着其他智能体的行为可能取决于智能体过去的互动,就像环境的其他方面一样(例如,只能在第 n 次尝试时打开的卡住的门)。特别是,这种自适应性可能会出现在包含一个或多个学习最大化自身奖励的强化学习智能体的环境中。这种环境可能需要社会智能的某些方面,例如虚张声势或隐藏信息,并且奖励最大化智能体可能必须是随机的(即,使用混合策略)以避免被利用。
奖励最大化实际上可能会导致比均衡更好的解决方案 [47]。这是因为它可能会利用其他智能体的次优行为,而不是假设最优或最坏情况的行为。此外,奖励最大化具有独特的最佳值 [38],而均衡值在一般和博弈中是非唯一的 [41]。
3.4. 奖励足以获得语言
语言一直是自然智能 [10] 和人工智能 [28] 领域的重要研究课题。由于语言在人类文化和互动中起着主导作用,因此智能本身的定义通常基于理解和使用语言的能力,尤其是自然语言 [60]。
最近,通过将语言视为对单一目标的优化:对大数据语料库中语言的预测建模 [28,8],已经取得了显著的成功。这种方法促进了在自然语言处理和理解中经常被单独研究或实施的许多语言子问题的进展,包括句法子问题(例如,形式语法、词性标注、解析、分割)和语义子问题(例如,词汇语义、蕴含、情感分析)以及将两者结合在一起的一些子问题(例如,摘要、对话系统)。
然而,仅靠语言建模可能不足以产生与智能相关的更广泛的语言能力,其中包括以下内容:
语言可能与其他动作和观察方式交织在一起。语言通常是上下文相关的,不仅在于所说的话,还取决于智能体周围环境中发生的其他事情,这些事情通过视觉和其他感官方式感知到(例如,考虑两个智能体之间携带笨拙物体或建造庇护所的对话)。此外,语言通常与其他交流行为穿插在一起,例如手势、面部表情、语调变化或肢体演示。
- 语言是结果性的和有目的的。语言话语在环境中具有结果,通常通过影响心理状态,从而影响环境中其他交流者的行为。可以优化这些结果以实现各种目的,例如,销售人员学会调整他们的语言以最大化销售额,而政治家学会调整他们的语言以最大化选票。
- 语言的效用因智能体的情况和行为而异。例如,矿工可能需要关于岩石稳定性的语言,而农民可能需要关于土壤肥力的语言。此外,语言可能存在机会成本(例如,讨论耕作而不是做耕作的工作)。
- 在丰富的环境中,使用语言处理不可预见事件的潜在用途可能会超过任何语料库的能力。在这些情况下,可能需要通过经验动态地解决语言问题——例如,交互式地开发最有效的语言来控制一种新疾病、构建一项新技术或找到一种方法来解决竞争对手的新不满,以阻止侵略。
根据我们的假设,语言在其充分丰富性方面的能力,包括所有这些更广泛的能力,都源于对奖励的追求。它是智能体基于复杂的观察序列(例如,接收句子)生成复杂的动作序列(例如,说出句子)的能力的一个实例,目的是影响环境中的其他智能体(参见上面的社会智能讨论)并积累更大的奖励 [7]。理解和产生语言的压力可能来自许多增加奖励的好处。如果智能体能够理解“危险”警告,那么它可以预测和避免负面奖励。如果智能体可以生成“取”命令,那么这可能会导致环境(例如,包含一只狗)将对象移到更靠近智能体的位置。同样,智能体可能只有在能够理解食物位置的复杂描述、生成种植食物的复杂说明、进行复杂的对话以协商食物或建立增强这些谈判的长期关系时才能进食——最终导致各种复杂的语言技能。
3.5. 奖励足以获得泛化
泛化通常被定义为将一个问题的解决方案转移到另一个问题的解决方案的能力 [37,58,61]。例如,监督学习中的泛化 [37] 可能侧重于将从一个数据集(例如照片)学习到的解决方案转移到另一个数据集(例如绘画)。元学习 [61,20] 中的泛化最近侧重于将智能体从一个环境转移到另一个环境的问题。
根据我们的假设,泛化可以被理解为,并通过在智能体和单个复杂环境之间持续的互动流中最大化累积奖励来实现——再次遵循标准的智能体-环境协议(参见第 2.1 节)。像人类世界这样的环境需要泛化,仅仅是因为智能体在不同的时间遇到环境的不同方面。例如,一只吃水果的动物可能每天都会遇到一棵新树;此外,它可能会受伤、遭受干旱或面临入侵物种。在每种情况下,动物都必须通过概括其过去状态的经验来快速适应其新状态。动物面临的不同状态不会整齐地分为具有不同标签的不相交的顺序任务。相反,状态取决于动物的行为;它可能结合各种以不同时间尺度重叠和复发的元素;并且状态的重要方面可能会被部分观察到。丰富的环境需要概括从过去状态到未来状态的能力——所有这些相关的复杂性——以便有效地积累奖励。
3.6. 奖励足以获得模仿
模仿是与人类和动物智能相关的一项重要能力,它可以促进其他能力的快速获取,例如语言、知识和运动技能。在人工智能中,模仿通常被制定为通过行为克隆 [2] 从演示中学习的问题 [45],其目标是重现教师选择的动作,当提供关于教师动作、观察和奖励的显式数据时,通常假设教师正在解决与智能体对称的问题。行为克隆导致了几个成功的机器学习应用 [54,62,5],尤其是那些人类教师数据丰富但互动体验有限或成本高昂的应用。相反,自然观察学习能力 [3] 包括从观察其他人或动物的观察行为中学习的任何形式的学习,并且不假设对称的教师或需要直接访问他们的动作、观察和奖励。这表明,与通过行为克隆进行的直接模仿相比,可能需要复杂环境中一类更广泛和更真实的观察学习能力:
- 其他智能体可能是智能体环境的组成部分(例如,婴儿观察其母亲),而不假设存在包含教师数据的独特数据集。
- 智能体可能需要学习其自身状态(例如,婴儿身体的姿势)与其他智能体状态(例如,其母亲的姿势)之间,或其自身动作(例如,旋转机器人的机械手)与其他智能体观察结果(例如,看到人手)之间的关联,可能在更高的抽象层次上(例如,模仿母亲对食物的选择,而不是她的肌肉激活)。
- 其他智能体可能被部分观察到(例如,人手被遮挡),这样只能在事后才能不完美地推断出他们的动作或目标。
- 其他智能体可能会表现出应避免的不良行为。
- 环境中可能有许多其他智能体,表现出不同的技能或不同的能力水平。
- 观察学习甚至可能在没有任何明确的代理的情况下发生(例如,从观察到横跨溪流倒下的原木中模仿桥梁建造的想法)。
我们推测,从单个智能体的角度来看,这些更广泛的观察学习能力可以通过奖励最大化来驱动,该智能体只是将其他智能体观察为其环境的组成部分 [6],这可能会导致与行为克隆相同的好处——例如知识的样本高效获取——但在更广泛和更综合的背景下。
3.7. 奖励足以获得通用智能
对于我们的最后一个例子,我们转向同时构成最大挑战的能力,我们的假设提供了最大的潜在好处。通用智能,人类可能和其他动物拥有的那种,可以定义为在不同上下文中灵活实现各种目标的能力。例如,人类可以灵活地解决问题(例如运动、运输或通信),并根据其情况采取适当的解决方案(例如游泳或滑雪、携带或踢球、写作或手语)。通用智能有时由一组环境形式化,这些环境衡量智能体在各种不同目标和上下文中的能力 [25,14]。
根据我们的假设,通用智能可以被理解为,并通过在单个复杂环境中最大化单一奖励来实现。例如,自然智能在其整个生命周期中面临着一个连续的体验流,该体验流是由与自然世界的互动产生的。动物的体验流足够丰富和多样,以至于可能需要灵活地实现各种子目标(例如觅食、战斗或逃跑),以便成功地最大化其整体奖励(例如饥饿或繁殖)。同样,如果人工智体体的体验流足够丰富,那么单一目标(例如电池寿命或生存)可能隐式地需要实现同样广泛的子目标的能力,因此奖励最大化应该足以产生人工通用智能。
4. 强化学习智能体
我们的主要假设,智能及其相关能力可以被理解为服务于奖励的最大化,这与智能体的本质无关。这给如何构建一个最大化奖励的智能体这一重要问题留下了悬念。在本节中,我们建议这个问题也可以通过奖励最大化来回答。具体来说,我们考虑具有学习如何从其与环境交互的持续经验中最大化奖励的通用能力的智能体。我们将此类智能体称为强化学习智能体,它们具有几个优势。3
首先,在最大化奖励的所有可能的解决方案中,当然最自然的方法是通过与环境交互从经验中学习这样做。随着时间的推移,这种互动体验提供了丰富的有关因果关系、行动后果以及如何积累奖励的信息。与其预先确定智能体的行为(将信任寄托于设计者对环境的预先了解)不如将一般的发现自身行为的能力赋予智能体(将信任寄托于经验)。更具体地说,最大化奖励的设计目标是通过从经验中学习最大化未来奖励的行为的持续内部过程来实现的。4
强化学习智能体通过从经验中学习,提供了一种通用的解决方案,该解决方案在许多不同的奖励信号和环境中都可能有效,而只需进行最小甚至零修改。
此外,单个环境可能非常复杂,例如自然世界,以至于它包含各种可能的体验。长期存在的智能体所面临的观察和奖励流中的潜在变化将不可避免地超过其预先编程行为的能力(参见第 3.1 节)。为了获得高奖励,智能体必须配备完全且持续地将其行为适应新体验的通用能力。事实上,强化学习智能体可能是在如此复杂的环境中唯一可行的解决方案。
一个足够强大和通用的强化学习智能体最终可能会产生智能及其相关能力。换句话说,如果一个智能体可以不断调整其行为以提高其累积奖励,那么其环境反复需要的任何能力最终都必须在智能体的行为中产生。因此,一个好的强化学习智能体可以在学习最大化环境中(例如人类世界)的奖励的过程中获得表现出感知、语言、社会智能等行为,在这些环境中这些能力具有持续的价值。
我们不提供关于强化学习智能体的样本效率的任何理论保证。事实上,能力出现的速率和程度将取决于具体的环境、学习算法和归纳偏差;此外,人们可以构建学习会失败的人工环境。相反,我们推测强大的强化学习智能体在复杂环境中实际应用时会产生复杂的智能表达。如果这个推测是正确的,它为实现人工通用智能提供了一条完整的途径。
最近,一些强化学习智能体的例子,它们被赋予了学习最大化奖励的能力,已经产生了超出预期的广泛能力的智能行为,超过了先前智能体的性能,并且在某些情况下,超过了人类专家的性能。例如,当要求最大化围棋游戏的胜利时,AlphaZero 学习了(参见第 1 节)跨越围棋的许多方面的综合智能 [49];当将相同的算法应用于最大化国际象棋游戏的成果时,AlphaZero 学习了一套不同的能力,包括开局、残局、棋子机动性、棋王安全等 [48,44]。在 Atari 2600 [30] 中最大化得分的强化学习智能体已经学习了一系列能力,包括每个特定 Atari 游戏所要求的对象识别、定位、导航和运动控制方面,而那些在基于视觉的机器人操作中最大化成功抓取的智能体已经学习了诸如对象单例化、重新抓取和动态对象跟踪之类的感觉运动能力 [22]。虽然这些例子在范围上比自然智能所面临的环境窄得多,但它们为奖励最大化原则的有效性提供了一些实践证据。
当然,人们可能会想知道如何在实践智能体中有效地学习最大化奖励。例如,可以直接最大化奖励(例如,通过优化智能体的策略 [57]),或者间接最大化奖励,方法是将其分解为诸如表征学习、值预测、模型学习和规划之类的子目标,这些子目标本身可能会被进一步分解 [56]。我们不会在本文中进一步讨论这个问题,但请注意,这是整个强化学习领域研究的中心问题。
5. 相关工作
智能长期以来一直与以目标为导向的行为相关联 [59]。这种以目标为导向的智能概念是理性概念的核心,在理性概念中,智能体以最佳方式实现其目标或最大化其效用的方式选择动作。理性已被广泛用于理解人类行为 [63,4],并作为人工智能的基础 [42],并相对于与环境交互的智能体进行了形式化。
当推理目标时,经常有人认为也应考虑到计算约束。有界 [50,43,36] 或计算理性 [27] 建议智能体应该选择最佳实现其目标的程序,给定该程序产生的实时结果(例如,程序执行需要多长时间),并受对程序集的限制(例如,限制程序的最大大小)。我们的贡献建立在这些观点之上,但侧重于一个单一的、基于奖励的简单目标是否可以为与智能相关的所有能力提供共同基础的问题。
Sutton 和 Barto [56] 定义了强化学习的标准协议;在第 2 节中,我们提出了具有部分观察历史的常见概括。
统一认知架构 [35,1] 渴望获得通用智能。它们结合了各种解决单独子问题(例如感知或运动控制)的解决方案,但不提供证明和解释架构选择的通用目标,也不提供单个组件贡献的目标。
将语言视为奖励最大化的观点可以追溯到行为主义 [52,53];然而,强化学习问题与行为主义的不同之处在于允许智能体构建和使用内部状态。在多智能体环境中,Shoham 和 Powers [47] 讨论了关注单个智能体目标的优势,而不是均衡目标。
6. 讨论
我们已经提出了奖励即足够的假设及其一些含义。接下来,我们简要地回答了在讨论这个假设时经常出现的一些问题。
哪个环境? 人们可能会问,哪个环境会通过奖励最大化来产生“最智能”的行为或“最佳”的特定能力(例如自然语言)。不可避免地,智能体遇到的特定环境体验——例如人类大脑一生中遇到的朋友、敌人、老师、玩具、工具或图书馆——会影响其后续能力的性质。虽然这个问题对于智能的任何特定应用可能都非常重要,但我们却专注于哪个通用目标可以产生所有形式的智能这个可以说更深刻的问题。在不同环境中最大化不同的奖励可能会导致不同的、强大的智能形式,每种形式都表现出自己令人印象深刻但又无法比拟的能力。一个好的奖励最大化智能体会利用其环境中存在的任何元素,但某种形式的智能的出现并非取决于其具体情况。例如,人类大脑在出生后,当暴露于其环境中的不同体验时,发展会有所不同,但无论其具体文化或教育如何,它都会获得复杂的能力。
哪个奖励信号? 操纵奖励信号的愿望通常源于只有精心构建的奖励才有可能诱导通用智能的想法。相比之下,我们认为智能的出现可能对奖励信号的性质相当稳健。这是因为像自然世界这样的环境非常复杂,即使是看似无害的奖励信号也可能需要智能及其相关能力。例如,考虑一个每次收集到圆形卵石时都向智能体提供 奖励的信号。为了有效地最大化这个奖励信号,智能体可能需要对卵石进行分类、操纵卵石、导航到卵石海滩、储存卵石、了解海浪和潮汐及其对卵石分布的影响、说服人们帮助收集卵石、使用工具和车辆收集更多数量的卵石、采石和塑造新卵石、发现和建造收集卵石的新技术,或建立一家收集卵石的公司。
除了奖励最大化,什么还能足以获得智能? 无监督学习 [19](例如识别观察中的模式)和预测 [18,11](例如未来观察的预测 [31])可能为理解体验提供有效的原则,但不提供动作选择的原则,因此不能单独满足以获得以目标为导向的智能。监督学习提供了一种模仿人类智能的机制;给定足够的人类数据,人们可能会想象与人类智能相关的所有能力都可能出现。然而,从人类数据进行监督学习不足以获得能够在非人类环境中为非人类目标进行优化的通用智能。即使在人类数据充足的情况下,模仿智能的能力也可能仅限于数据中已经为人所知和表现的行为,而不是发现以意想不到的方式解决问题的新创造性行为(另请参见下面的离线学习)。自然选择的进化可以在抽象层面理解为最大化适应性,如通过个体生殖成功来衡量,并通过诸如突变和交叉之类的基于种群的机制来优化。在我们的框架中,生殖成功可以被视为驱动自然智能出现的一种可能的奖励信号。然而,人工智能可能被设计为具有其他目标,而不是生殖成功,并且可以使用不同于突变和交叉的方法来最大化相应的奖励信号,这可能会导致非常不同的智能形式。此外,虽然适应性最大化可以解释自然智能的初始配置(例如,人类婴儿大脑),但试错学习最大化内在奖励信号 [51] 的过程(参见第 4 节)可以进一步解释自然智能如何通过经验适应,从而在服务适应性最大化的过程中发展复杂的能力(例如,人类成年人大脑)。自由能最大化或惊奇最小化 [13] 可能会产生自然智能的多种能力,但不能提供可以针对不同环境中广泛的不同目标的通用智能。因此,它也可能错过实现任何一个这些目标的最佳表现所需的能力(例如,与伴侣交配所需的社会智能方面,或将对手将死的战术智能)。优化是一种通用的数学形式主义,可以最大化任何信号,包括累积奖励,但不会指定智能体如何与其环境互动。相比之下,强化学习问题将互动置于其核心:优化行动以最大化奖励,这些行动反过来决定从环境接收的观察,这些观察本身会告知优化过程;此外,优化是在环境继续运行时实时在线发生的。
哪个奖励最大化问题? 即使在强化学习研究人员中,也研究了奖励最大化问题的许多变体。与遵循标准的智能体-环境协议相反,交互循环通常会针对不同的情况进行修改,这些情况可能包括多个智能体、多个环境或多个训练寿命。与最大化由累积奖励定义的通用目标相反,目标的制定通常对不同的情况单独进行:例如多目标学习、风险敏感目标或由人在环中指定的目标。此外,与解决一般环境的奖励最大化问题相反,通常会针对特定类型的环境研究特殊情况问题,例如线性环境、确定性环境或稳定环境。虽然这可能适用于特定的应用,但专门问题的解决方案通常不会概括;相比之下,一般问题的解决方案也将为任何特殊情况提供解决方案。强化学习问题也可以转换为一种概率框架,该框架近似奖励最大化的目标 [66,39,26,17]。最后,通用决策框架 [21] 提供了跨所有环境的智能的理论但不可计算的公式;而强化学习问题则提供了给定环境中智能的实际公式。
从足够大的数据集中进行离线学习是否足以获得智能? 离线学习可能只足以解决已经在可用数据中在很大程度上得到解决的问题。例如,松鼠收集坚果的大型数据集不太可能展示建造坚果收割机所需的所有行为。尽管有可能从离线数据中演示或提取的解决方案概括到智能体当前的问题,但在复杂的环境中,这种概括不可避免地是不完善的。此外,解决智能体当前问题所需的数据通常在离线数据中发生的概率可以忽略不计(例如,在随机行为或不完善的人类行为下)。在线互动允许智能体专门针对它当前面临的问题,不断验证和纠正其知识中最紧迫的漏洞,并找到与数据集中的行为非常不同且获得更大奖励的新行为。
奖励信号是否过于贫乏? 人们可能会怀疑,在复杂、未知的环境中,样本高效的强化学习智能体是否必然存在,它们能够最大化奖励。在回答这个问题时,我们首先注意到,一个有效的智能体可能会利用额外的经验信号来促进未来奖励的最大化。包括无模型强化学习在内的许多解决方案,通过值函数逼近,学习将未来的奖励与观察特征相关联,这反过来提供了丰富的辅助信号,这些信号通过递归引导过程驱动更深层次关联的学习 [55]。包括基于模型的强化学习在内的其他解决方案,构建观察预测或观察特征预测,从而通过规划促进后续的奖励最大化。此外,如第 3.6 节所述,环境中其他智能体的观察也可能促进快速学习。
然而,通常是在复杂环境中样本高效的强化学习的挑战导致研究人员引入假设或开发更简单的抽象,这些抽象更适合于理论和实践。然而,这些假设和抽象可能只是回避了任何具有广泛能力的智能必然会面临的困难。我们选择正面迎接挑战并专注于解决方案;我们希望其他研究人员也能加入我们的探索之旅。
7. 结论
在本文中,我们提出了最大化总奖励可能足以理解智能及其相关能力的假设。关键思想是,丰富的环境通常需要各种能力来服务于奖励最大化。在自然界中发现的,以及可能在未来人工智体中发现的,智能的丰富表达可以被理解为在不同环境和不同奖励下对同一思想的实例化。此外,与每种不同能力的专业问题公式相比,奖励最大化的单一目标可能会对能力的理解更加深入、更广泛和更集成。特别是,我们更深入地探讨了几种乍一看似乎难以通过奖励最大化单独理解的能力,例如知识、学习、感知、社会智能、语言、概括、模仿和通用智能,并发现奖励最大化可以为理解每种能力提供基础。最后,我们提出了一个推测,即智能可以在实践中从足够强大的强化学习智能体中出现,这些智能体学习最大化未来的奖励。如果这个推测是正确的,那么它为理解和构建人工通用智能提供了一条直接的途径。
利益竞争声明:所有作者均为 DeepMind 的雇员。
鸣谢:我们要感谢审稿人以及我们在 DeepMind 的同事对本文的投入。
参考文献
- [1] J.R. Anderson, D. Bothell, M.D. Byrne, S. Douglass, C. Lebiere, Y. Qin, An integrated theory of the mind, Psychol. Rev. 111 (4) (2004) 1036.
- [2] M. Bain, C. Sammut, A framework for behavioural cloning, in: Machine Intelligence 15, 1995, pp. 103–129.
- [3] A. Bandura, D.C. McClelland, Social Learning Theory, vol. 1, Prentice Hall, Englewood Cliffs, 1977.
- [4] G.S. Becker, The Economic Approach to Human Behavior. Economic Theory, University of Chicago Press, 1976.
- [5] M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L.D. Jackel, M. Monfort, U. Muller, J. Zhang, X. Zhang, J. Zhao, K. Zieba, End to end learning for self-driving cars, CoRR, arXiv:1604 07316 [abs], 2016.
- [6] D. Borsa, N. Heess, B. Piot, S. Liu, L. Hasenclever, R. Munos, O. Pietquin, Observational learning by reinforcement learning, in: Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, International Foundation for Autonomous Agents and Multiagent Systems, 2019, pp. 1117–1124.
- [7] J. Bratman, M. Shvartsman, R. Lewis, S. Singh, A new approach to exploring language emergence as boundedly optimal control in the face of environmental and cognitive constraints, in: Proceedings of the 10th International Conference on Cognitive Modeling, ICCM, 2010.
- [8] T.B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., Language models are few-shot learners, arXiv:2005 14165, 2020.
- [9] E.C. Carterette, M.P. Friedman, Handbook of Perception, Academic Press, 1978.
- [10] N. Chomsky, D.W. Lightfoot, Syntactic Structures, Walter de Gruyter, 2002.
- [11] A. Clark, Whatever next? Predictive brains, situated agents, and the future of cognitive science, Behav. Brain Sci. 36 (3) (2013) 181–204.
- [12] G. Debreu, Representation of a Preference Ordering by a Numerical Function, 1954.
- [13] K. Friston, The free-energy principle: A unified brain theory?, Nat. Rev. Neurosci. 11 (127–38) (2010) 02.
- [14] B. Goertzel, C. Pennachin, Artificial General Intelligence, vol. 2, Springer, 2007.
- [15] A. Graves, A.-r. Mohamed, G. Hinton, Speech recognition with deep recurrent neural networks, in: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2013, pp. 6645–6649.
- [16] N. Grujic, J. Brus, D. Burdakov, R. Polania, Rational inattention in mice, bioRxiv, https://doi org 10 1101 2021.05 26 445807, 2021.
- [17] D. Hafner, P.A. Ortega, J. Ba, T. Parr, K.J. Friston, N. Heess, Action and perception as divergence minimization, CoRR, arXiv:2009 01791 [abs], 2020.
- [18] J. Hawkins, S. Blakeslee, On Intelligence, Times Books, USA, 2004.
- [19] G. Hinton, T.J. Sejnowski, Unsupervised Learning: Foundations of Neural Computation, The MIT Press, 1999.
- [20] T.M. Hospedales, A. Antoniou, P. Micaelli, A.J. Storkey, Meta-learning in neural networks: A survey, CoRR, arXiv:2004 05439 [abs], 2020.
- [21] M. Hutter, Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability, Springer, 2005.
- [22] D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V. Vanhoucke, S. Levine, Scalable deep reinforcement learning for vision-based robotic manipulation, in: 2nd Annual Conference on Robot Learning, Proceedings, CoRL 2018, Zürich, Switzerland, 29-31 October 2018, in: Proceedings of Machine Learning Research, vol. 87, PMLR, 2018, pp. 651–673.
- [23] A. Krizhevsky, I. Sutskever, G.E. Hinton, Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems, 2012, pp. 1097–1105.
- [24] Y. LeCun, Computer perception with deep learning, 2013.
- [25] S. Legg, M. Hutter, Universal intelligence: A definition of machine intelligence, Minds Mach. 17 (4) (2007) 391–444.
- [26] S. Levine, Reinforcement learning and control as probabilistic inference: Tutorial and review, CoRR, arXiv:1805 00909 [abs], 2018.
- [27] R.L. Lewis, A. Howes, S. Singh, Computational rationality: Linking mechanism and behavior through bounded utility maximization, Top. Cogn. Sci. 6 (2) (2014) 279–311.
- [28] C.D. Manning, C.D. Manning, H. Schütze, Foundations of Statistical Natural Language Processing, MIT Press, 1999.
- [29] J. McCarthy, What Is AI?, 1998.
- [30] V. Mnih, K. Kavukcuoglu, D. Silver, A.A. Rusu, J. Veness, M.G. Bellemare, A. Graves, M. Riedmiller, A.K. Fidjeland, G. Ostrovski, et al., Human-level control through deep reinforcement learning, Nature 518 (7540) (2015) 529.
- [31] J. Modayil, A. White, R.S. Sutton, Multi-timescale nexting in a reinforcement learning robot, Adapt. Behav. 22 (2) (2014) 146–160.
- [32] M. Müller, Computer Go, Artif. Intell. 134 (1–2) (2002) 145–179.
- [33] J.F. Nash, et al., Equilibrium points in n-person games, Proc. Natl. Acad. Sci. 36 (1) (1950) 48–49.
- [34] J.v. Neumann, Zur theorie der gesellschaftsspiele, Math. Ann. 100 (1) (1928) 295–320.
- [35] A. Newell, Unified Theories of Cognition, Harvard University Press, USA, 1990.
- [36] L. Orseau, M.B. Ring, Space-time embedded intelligence, in: Proceedings of the 5th International Conference on Artificial General Intelligence, Lecture Notes in Computer Science, vol. 7716, Springer, 2012, pp. 209–218.
- [37] S.J. Pan, Q. Yang, A survey on transfer learning, IEEE Trans. Knowl. Data Eng. 22 (10) (2009) 1345–1359.
- [38] M.L. Puterman, Markov Decision Processes: Discrete Stochastic Dynamic Programming, John Wiley & Sons, 2014.
- [39] K. Rawlik, M. Toussaint, S. Vijayakumar, On stochastic optimal control and reinforcement learning by approximate inference, in: Twenty-Third International Joint Conference on Artificial Intelligence, 2013.
- [40] M. Redmond, C. Garlock, AlphaGo to Zero: The Complete Games, Smart Go, 2020.
- [41] J. Ben Rosen, Existence and uniqueness of equilibrium points for concave n-person games, Econometrica (1965) 520–534.
- [42] S. Russell, P. Norvig, Artificial Intelligence: A Modern Approach, Prentice Hall, 1995.
- [43] S.J. Russell, D. Subramanian, Provably bounded-optimal agents, J. Artif. Intell. Res. 2 (1995) 575–609.
- [44] M. Sadler, N. Regan, G. Kasparov, Game Changer: AlphaZero’s Groundbreaking Chess Strategies and the Promise of AI, New in Chess, 2019.
- [45] S. Schaal, Learning from demonstration, in: M. Mozer, M.I. Jordan, T. Petsche (Eds.), Advances in Neural Information Processing Systems 9, NIPS, Denver, CO, USA, December 2–5, 1996, MIT Press, 1996, pp. 1040–1046.
- [46] J. Schaffner, P. Tobler, T. Hare, R. Polania, Neural codes in early sensory areas maximize fitness, bioRxiv, https://doi org 10 1101 2021.05 10 443388, 2021.
- [47] Y. Shoham, R. Powers, T. Grenager, If multi-agent learning is the answer, what is the question?, Artif. Intell. 171 (7) (2007) 365–377.
- [48] D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, et al., A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play, Science 362 (6419) (2018) 1140–1144.
- [49] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, et al., Mastering the game of go without human knowledge, Nature 550 (7676) (2017) 354–359.
- [50] H.A. Simon, A behavioral model of rational choice, Q. J. Econ. 69 (1) (1955) 99–118.
- [51] S. Singh, R.L. Lewis, A.G. Barto, J. Sorg, Intrinsically motivated reinforcement learning: An evolutionary perspective, IEEE Trans. Auton. Ment. Dev. 2 (2) (2010) 70–82.
- [52] B.F. Skinner, The Behavior of Organisms: An Experimental Analysis, Appleton-Century-Crofts, New York, 1938.
- [53] B.F. Skinner, Verbal Behavior, Appleton-Century-Crofts, New York, 1957.
- [54] N. Stiennon, L. Ouyang, J. Wu, D.M. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, P.F. Christiano, Learning to summarize with human feedback, in: Advances in Neural Information Processing Systems 33, 2020.
- [55] R.S. Sutton, Learning to predict by the methods of temporal differences, Mach. Learn. 3 (1) (1988) 9–44.
- [56] R.S. Sutton, A.G. Barto, Reinforcement Learning: An Introduction, second edition, The MIT Press, 2018.
- [57] R.S. Sutton, D.A. McAllester, S. Singh, Y. Mansour, Policy gradient methods for reinforcement learning with function approximation, in: Advances in Neural Information Processing Systems, 2000, pp. 1057–1063.
- [58] M.E. Taylor, P. Stone, Transfer learning for reinforcement learning domains: A survey, J. Mach. Learn. Res. 10 (1) (2009) 1633–1685.
- [59] E.C. Tolman, Purposive Behavior in Animals and Men, Century/Random House, UK, 1932.
- [60] A.M. Turing, Computing machinery and intelligence, Mind 59 (236) (1950) 433.
- [61] J. Vanschoren, Meta-learning: A survey, CoRR, arXiv:1810 03548 [abs], 2018.
- [62] O. Vinyals, I. Babuschkin, W.M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D.H. Choi, R. Powell, T. Ewalds, P. Georgiev, J. Oh, D. Horgan, M. Kroiss, I. Danihelka, A. Huang, L. Sifre, T. Cai, J.P. Agapiou, M. Jaderberg, A.S. Vezhnevets, R. Leblond, T. Pohlen, V. Dalibard, D. Budden, Y. Sulsky, J. Molloy, T.L. Paine, Gülçehre, Wang Wu, R. Ring, D. Yogatama, D. Wünsch, K. McKinney, O. Smith, T. Schaul, T.P. Lillicrap, K. Kavukcuoglu, D. Hassabis, C. Apps, D. Silver, Grandmaster evel in starcraft II using multi-agent reinforcement learning, Nature 575 (7782) (2019) 350–354.
- [63] M. Weber, G. Roth, C. Wittich, E. Fischoff, Economy and Society: An Outline of Interpretive Sociology, University of California Press, 1978.
- [64] Y. Zhou, AlphaGo vs Ke Jie, Slate and Shell, 2017.
- [65] Y. Zhou, Rethinking Opening Strategy: AlphaGo’s Impact on Pro Play, Slate and Shell, 2018.
- [66] B.D. Ziebart, J.A. Bagnell, A.K. Dey, Modeling interaction via the principle of maximum causal entropy, in: Proceedings of the 27th International Conference on Machine Learning, Omnipress, 2010, pp. 1255–1262.