P vs. NP 与计算的难度:一种规则学路径「Wolfram」
- 作者: Stephen Wolfram
- 发布日期: 2026年1月30日
- 来源: Stephen Wolfram Writings

经验性的理论计算机科学
“有没有更快的程序能做到这一点?”这是理论计算机科学中的一个基本问题。但在除特殊情况外,这类问题已被证明极难回答。例如,半个世纪以来,即使是那个相当粗略(尽管非常著名)的 P vs. NP 问题 ——本质上即是否对于任何非确定性程序,总存在一个同样快的确定性程序——也几乎没有任何进展。从纯理论的角度来看,甚至很少有人清楚该如何着手解决这个问题。但是,如果我们从经验(empirical)的角度来看待这个问题,比如实际上通过枚举可能的程序并明确观察它们的运行速度等,会发生什么呢?
人们可能会认为,任何能被现实枚举的程序都太小了,不足以产生趣味性。但我在20世纪80年代初发现,情况绝对不是这样——事实上,即使是小到可以轻松枚举的程序,也常常表现出极其丰富和复杂的行为。凭借这种直觉,早在 20 世纪 90 年代,我就已经开始了一些经验性探索,例如用图灵机计算函数的最快方法。但现在——特别是有了Ruliad(规则全集/规则之网)的概念——我们有了一个更系统的框架来思考可能程序的空间。因此,我决定再次通过计算宇宙来审视理论计算机科学中出现的计算复杂性理论问题——包括 P vs. NP 问题。
我们不会彻底解决 P vs. NP 问题。但我们将获得大量确定的、更受限的结果。通过在“一般理论之下”观察明确具体的案例,我们将感知到 P vs. NP 问题的一些基本问题和微妙之处,以及为什么关于它的证明可能如此困难。
在这个过程中,我们还将看到大量证据证明计算不可约性(Computational Irreducibility)现象——以及计算难度的普遍模式。我们会看到有些计算可以被“约简”,从而完成得更快。但也会看到其他的计算,我们可以绝对明确地看到——至少在我们研究的程序类别中——根本没有更快的方法来完成计算。实际上,这将为我们提供大量关于受限形式的计算不可约性的证明。看到这些将让我们进一步建立对日益核心的计算不可约性现象的直觉,并了解我们通常如何使用规则学(Ruliology)的方法论来探索理论计算机科学的问题。
基本设定
点击任何图表均可获取复现该图表的 Wolfram Language 代码。
我们如何枚举可能的程序?我们可以选择任何计算模型。为了便于与传统理论计算机科学联系,我将使用一个经典模型:图灵机。
在理论计算机科学中,人们通常关注“是/否”的判定问题。但在这里,考虑计算整数函数的图灵机(更具“数学性”)通常会更方便。我们使用的设定如下:在图灵机的纸带上以某个整数 n 的数字作为起始。然后运行图灵机,如果图灵机的读写头移动到了比起始位置更靠右的地方,则停止。函数在输入 n 下的值,即为图灵机停止时纸带上保留的二进制数字。(我们还可以使用许多其他“停机”标准,但这一种特别稳健且方便。)
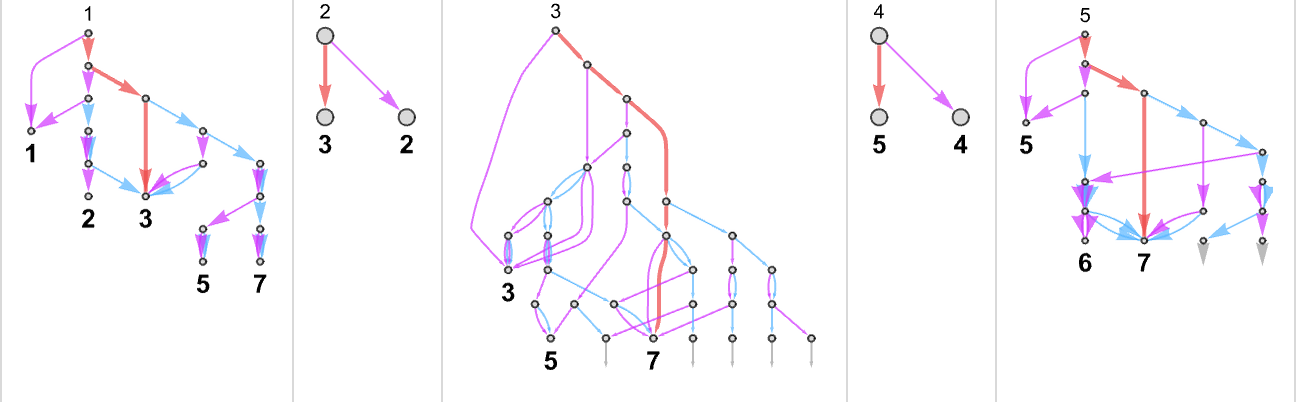
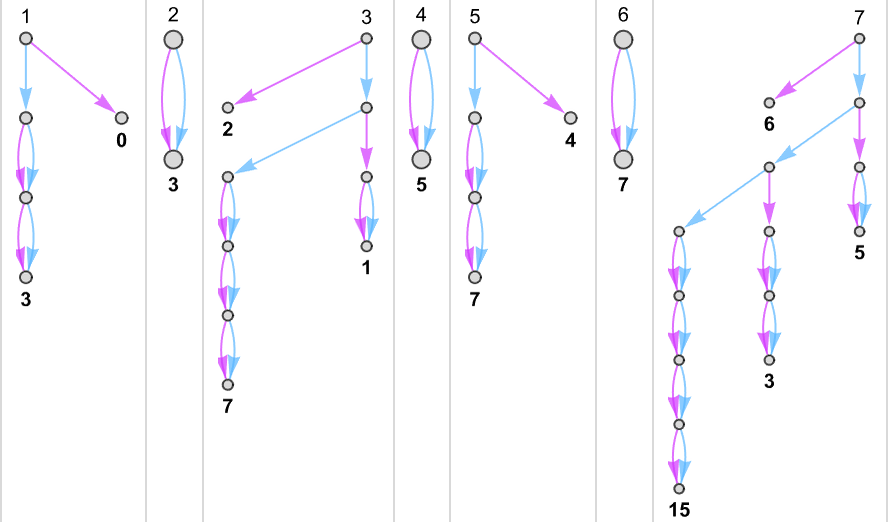
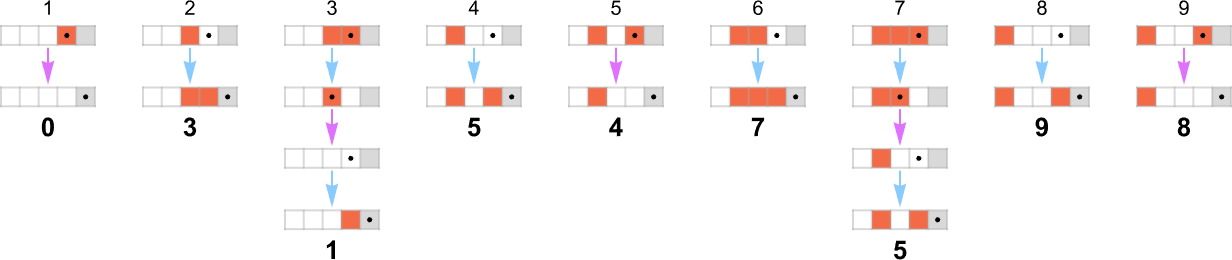
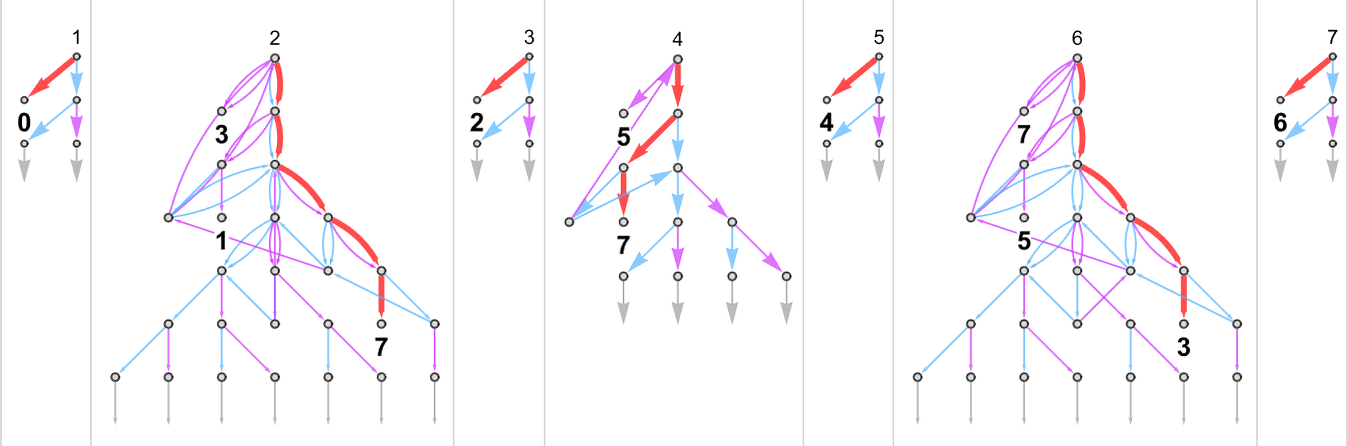
例如,给定一个规则如下的图灵机:
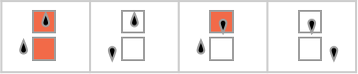
我们可以输入连续的整数,然后运行机器以找到它计算出的连续值:
在这种情况下,图灵机计算的函数是:

即图形形式:
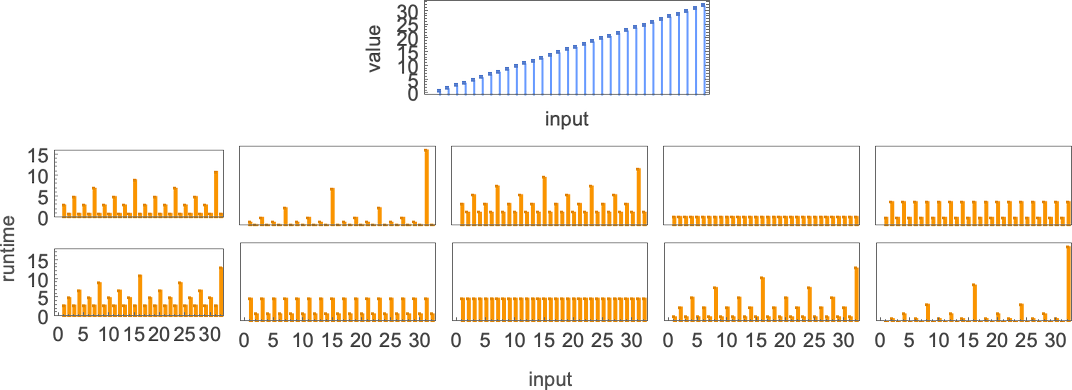
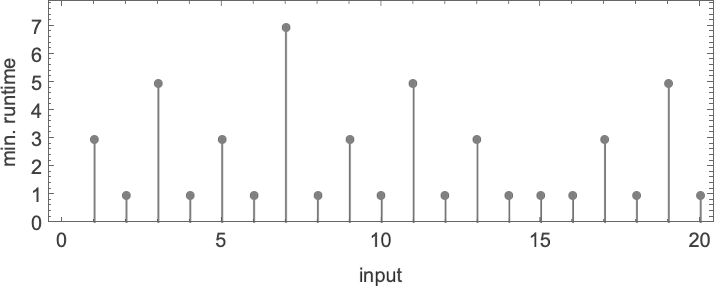
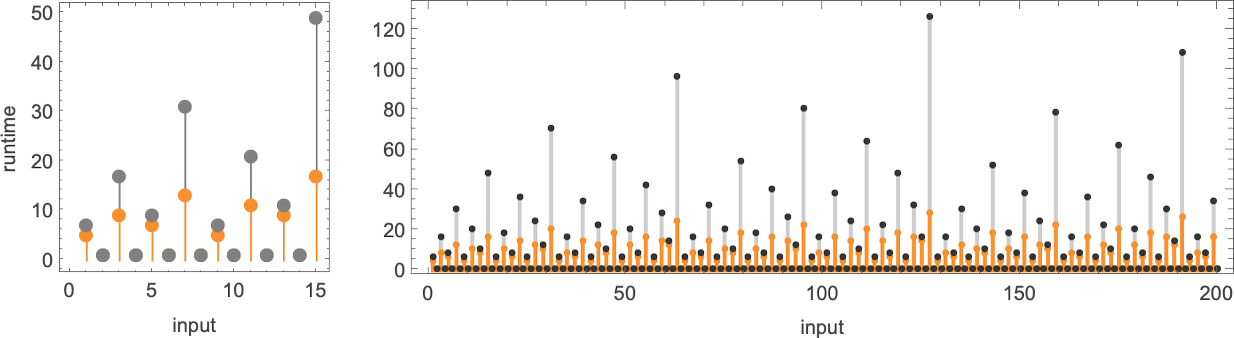
对于每个输入,图灵机需要一定的步数才能停止并给出输出(即函数的值):
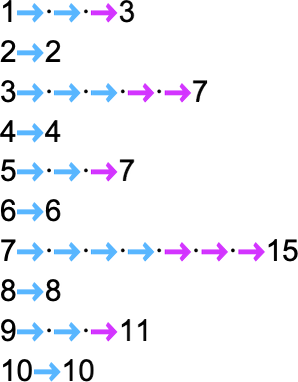
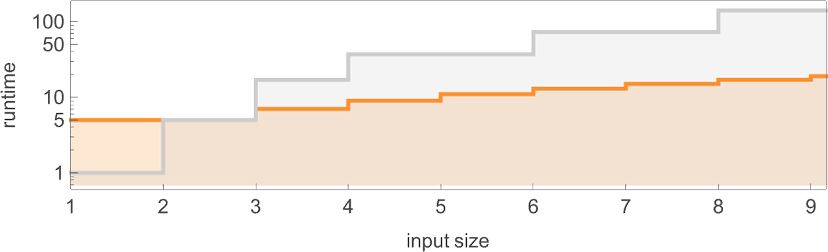
但这并不是唯一能计算该函数的图灵机。这里还有两个:
输出与之前相同,但运行时间(runtime)不同:
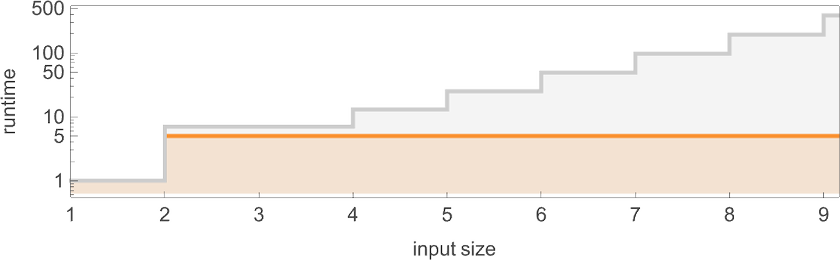
分别用蓝色、橙色和绿色表示它们并绘制在一起,我们看到有明显的趋势——但并没有明显的“最快程序”赢家:

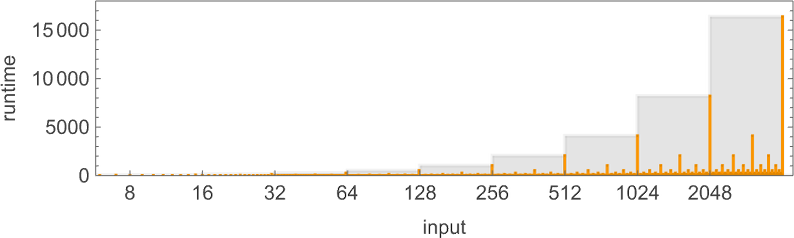
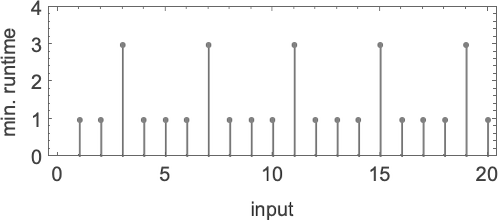
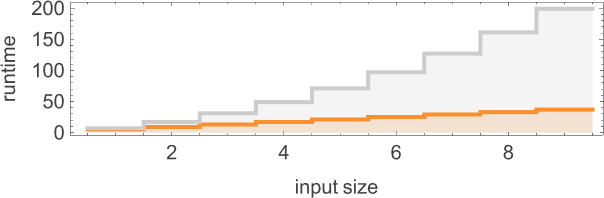
在计算复杂性理论中,讨论运行时间如何随输入规模变化是很常见的——在这里,这意味着取具有给定数字位数的每组输入块,并找出其最大值:
我们看到的是,在这种情况下,显示的第一个图灵机比其他两个“系统性地更快”——事实上,在我们使用的尺寸范围内,它提供了计算该特定函数的最快方法。
由于我们将处理大量的图灵机,用数字来指定它们会很方便——我们将采用 Wolfram Language 中 TuringMachine 函数的方式。在这种设定下,我们刚刚考虑的机器编号分别为 261、3333 和 1285。
在思考图灵机计算的函数时,有一个直接的微妙之处需要考虑。我们说过,通过读取图灵机停止时纸带上的内容来找到输出。但是如果机器从未停止呢?(或者在我们的例子中,如果图灵机的读写头从未到达右端?)那么,就没有定义输出值。一般来说,我们的图灵机计算的函数只是部分函数(partial functions)——即对于某些输入,可能没有定义的输出值(如下图中的机器 2189):
当我们绘制这种部分函数时,未定义值的地方会出现空缺:
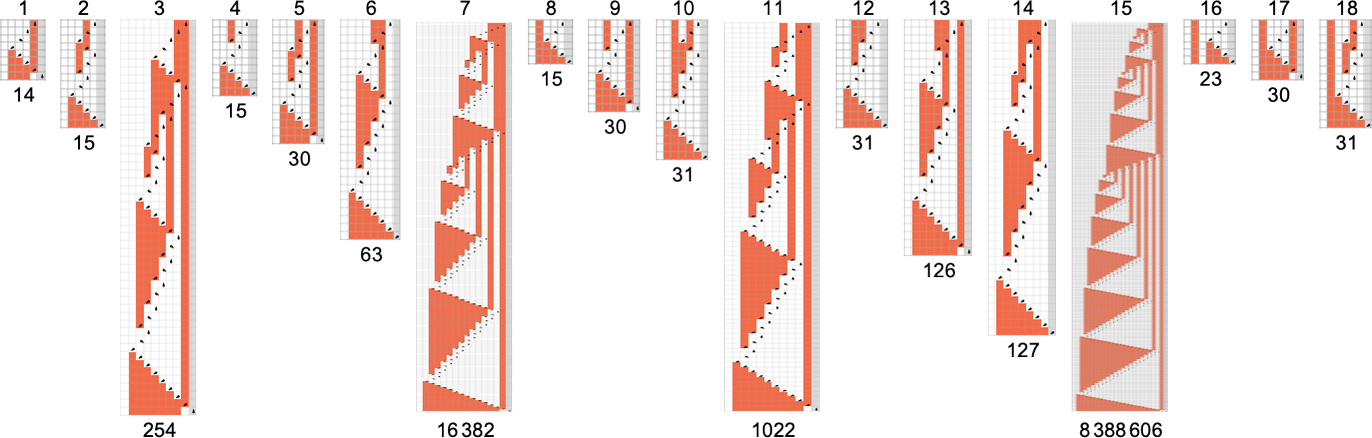
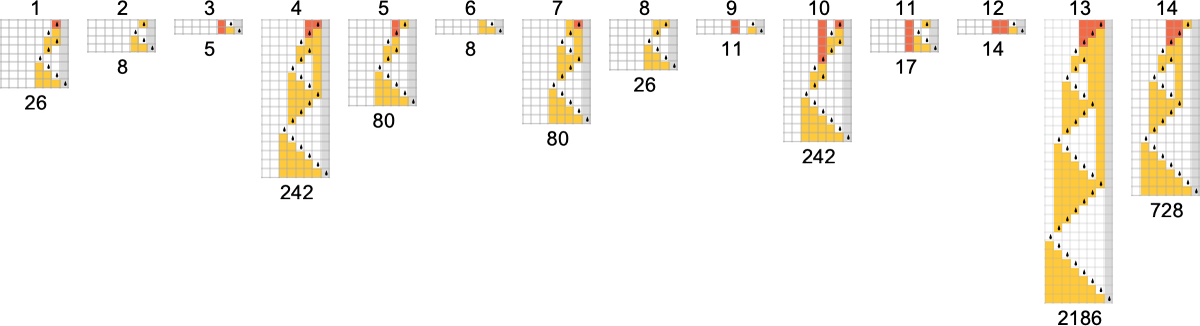
在下文中,我们将探索不同“大小”的图灵机。我们假设纸带上的每个位置有两种可能的颜色——读写头有 s 种可能的状态。具有 k = 2 种颜色和 s 种状态的可能图灵机的总数为 ——这随着 s 的增加而迅速增长:

对于任何给定的函数,我们就可以问:在给定大小以下的机器中,哪台(或哪些)机器计算得最快。换句话说,通过显式地研究可能的图灵机,我们将能够为计算某个函数的计算难度建立一个绝对下界,至少当该计算由不大于给定大小的图灵机完成时。(是的,图灵机的大小可以被认为是在表征其“算法信息内容”。)
在传统的计算复杂性理论中,建立下界通常非常困难。但我们这里的规则学方法将允许我们系统地做到这一点(至少相对于给定大小的机器,即具有给定算法信息内容的机器)。(值得指出的是,如果机器足够大,它可以包含任何给定函数的任意数量案例的查找表——这使得关于计算这些案例的难度问题变得没有意义。)
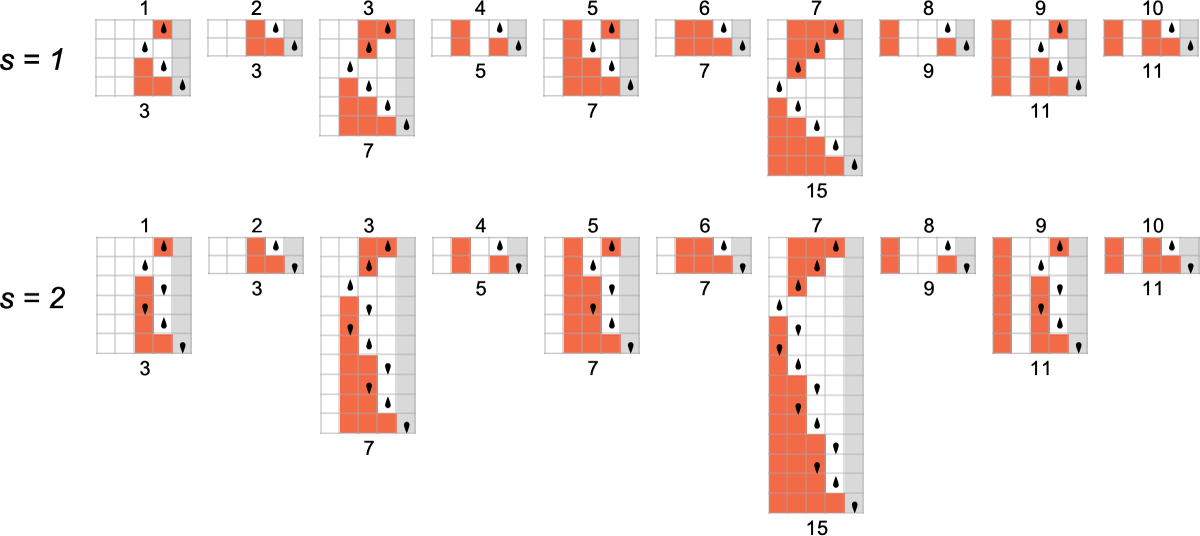
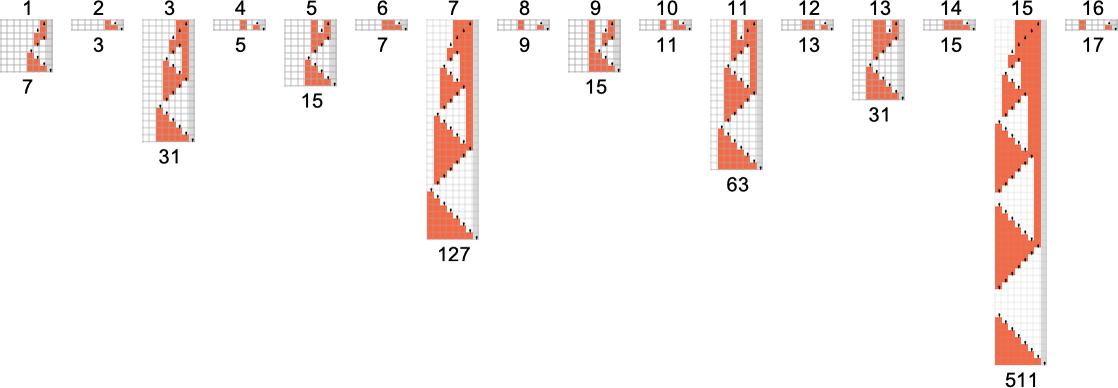
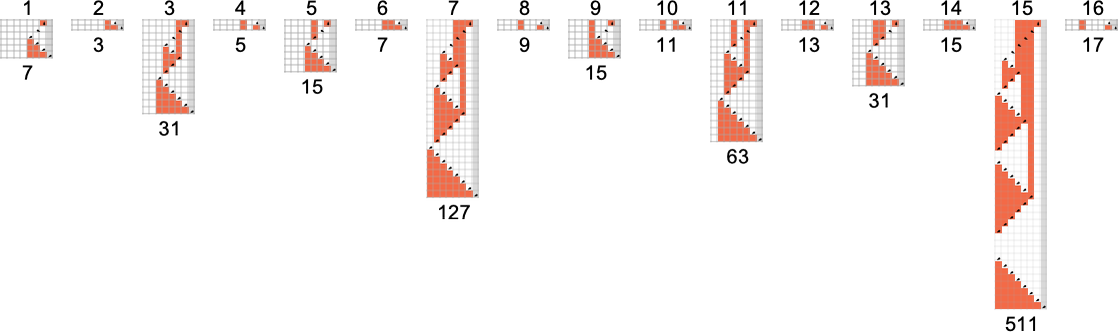
s = 1, k = 2 图灵机
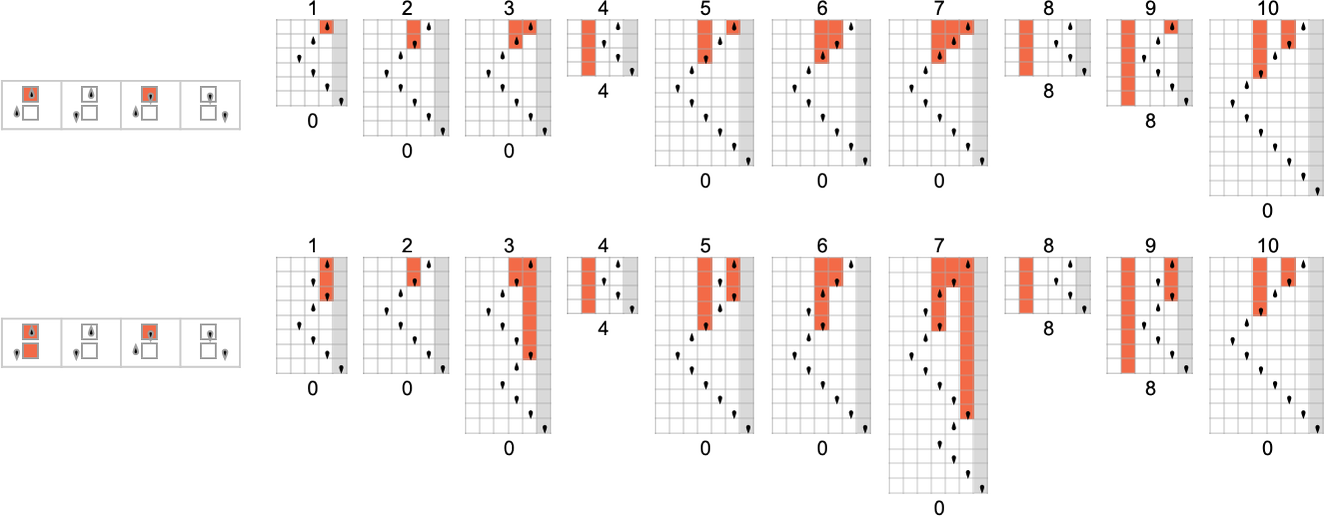
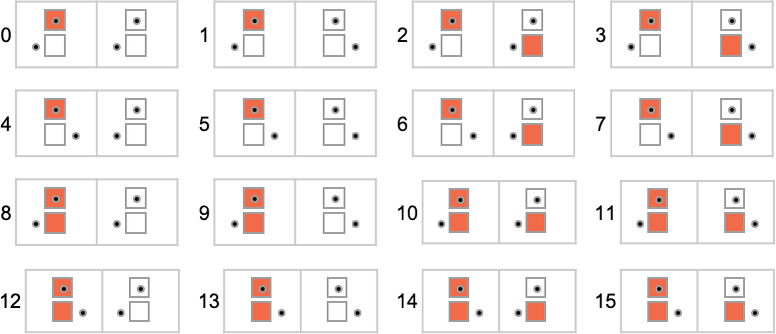
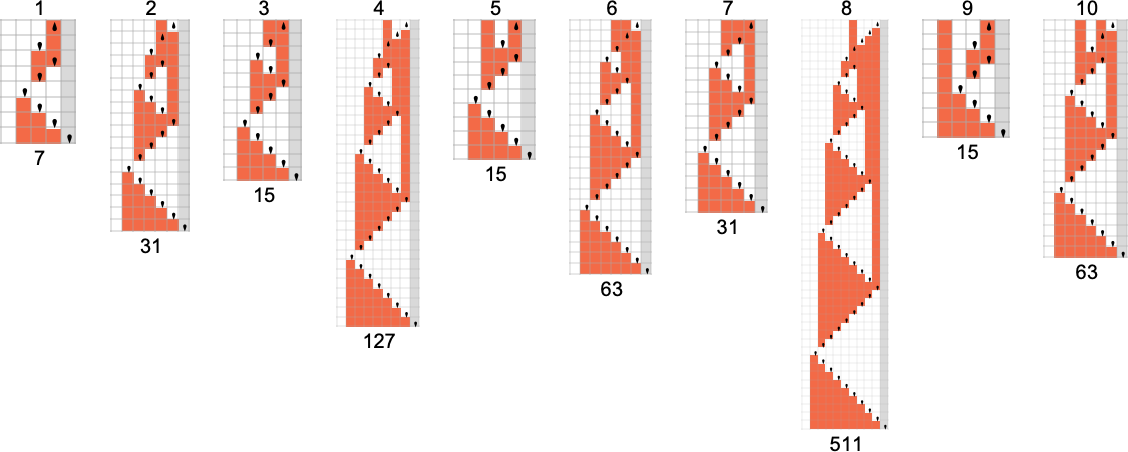
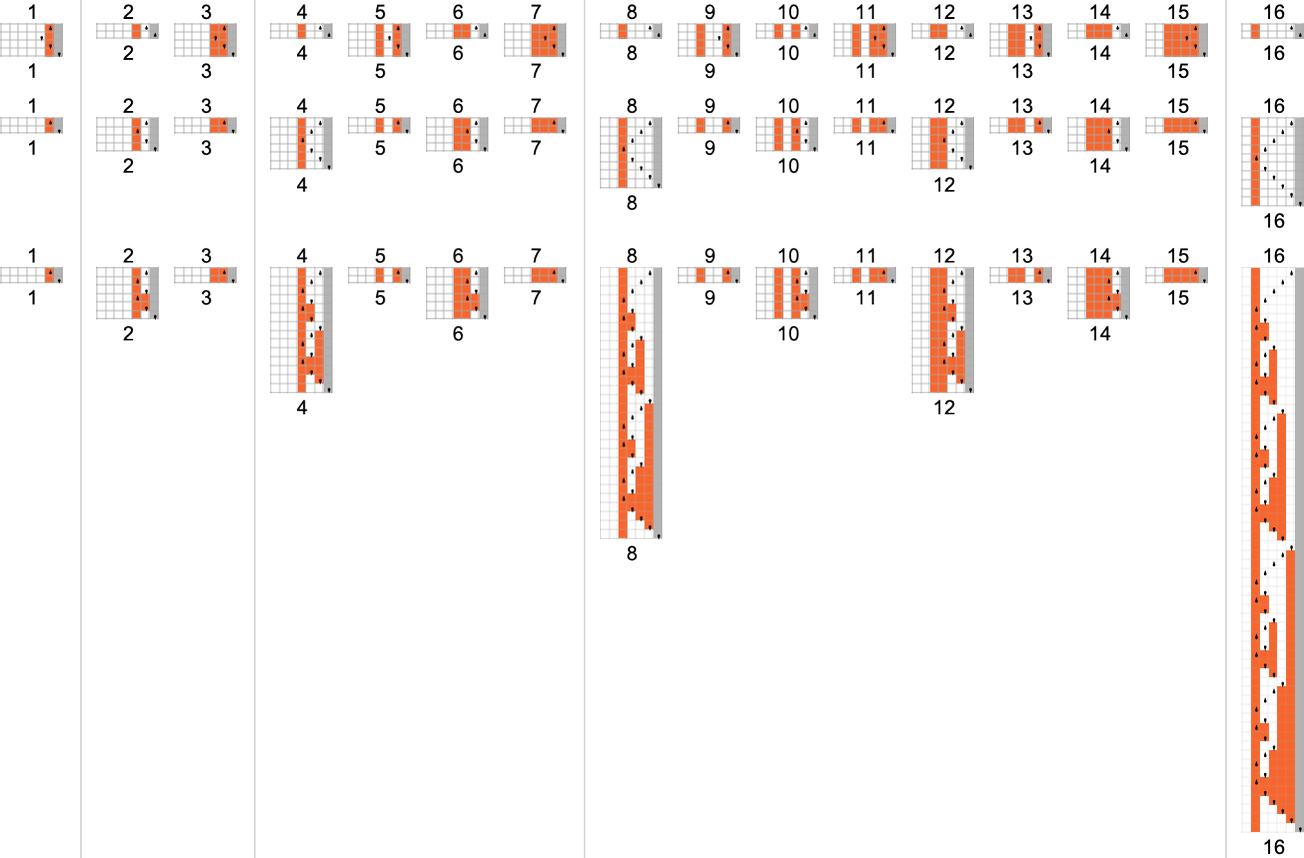
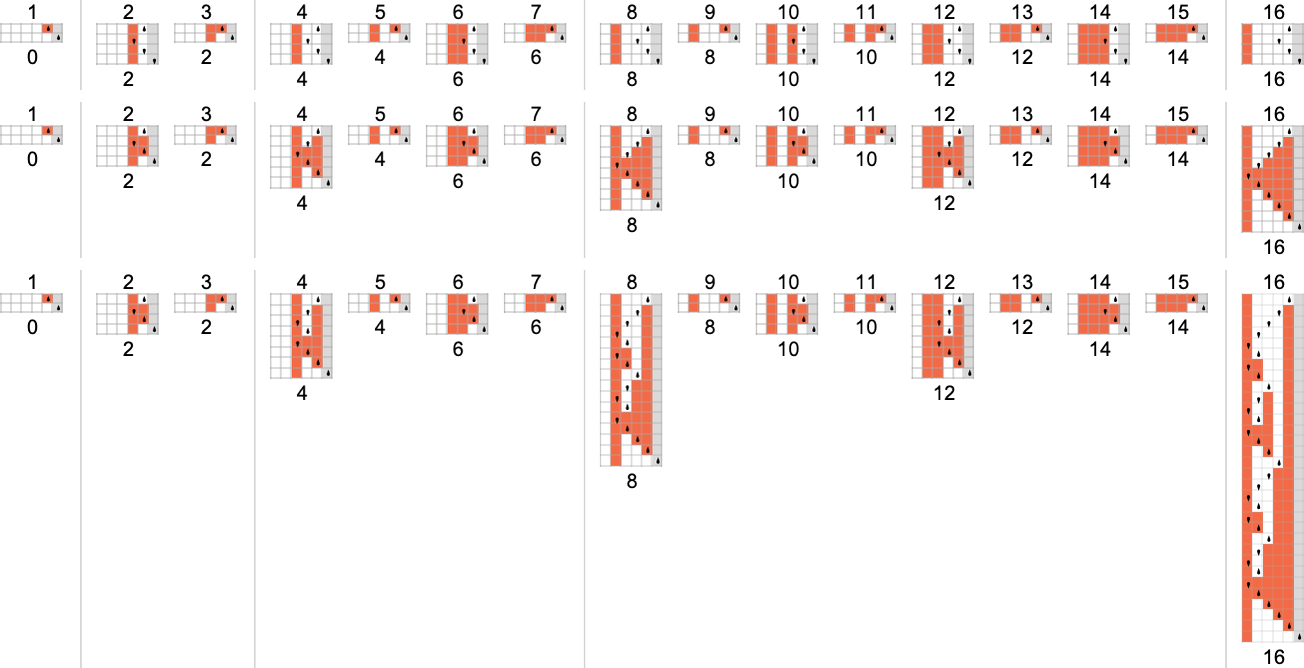
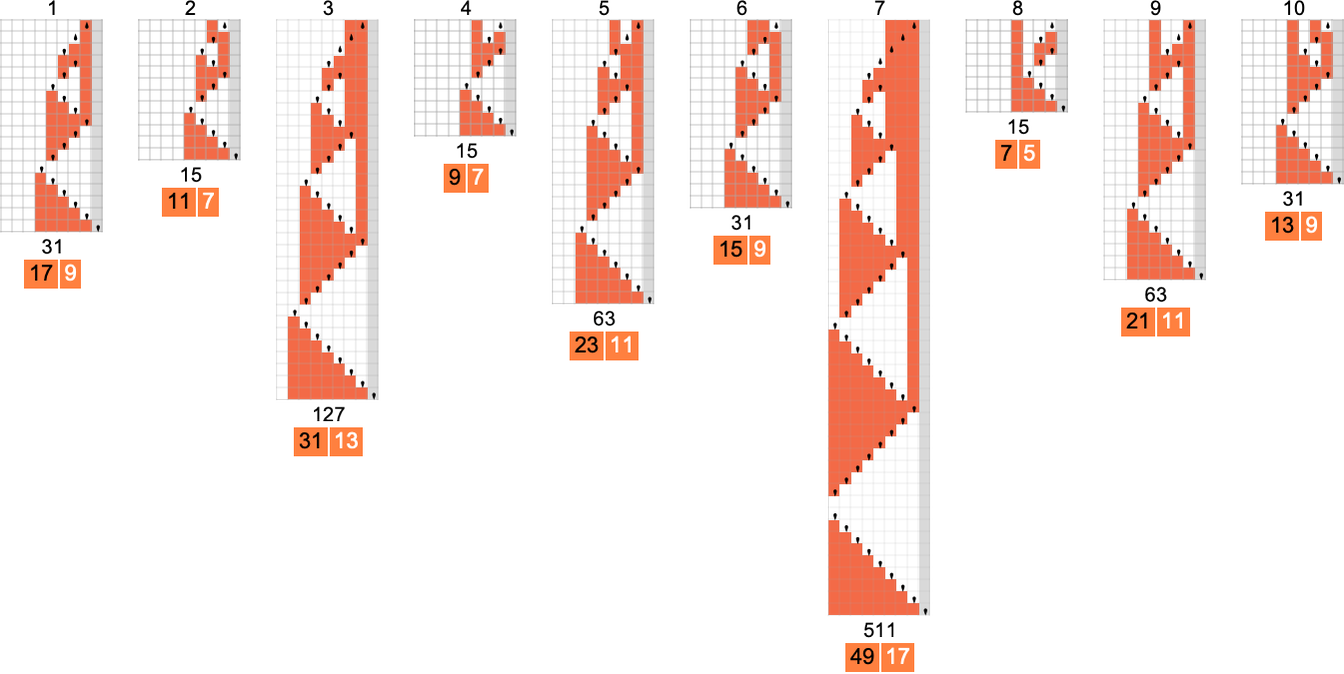
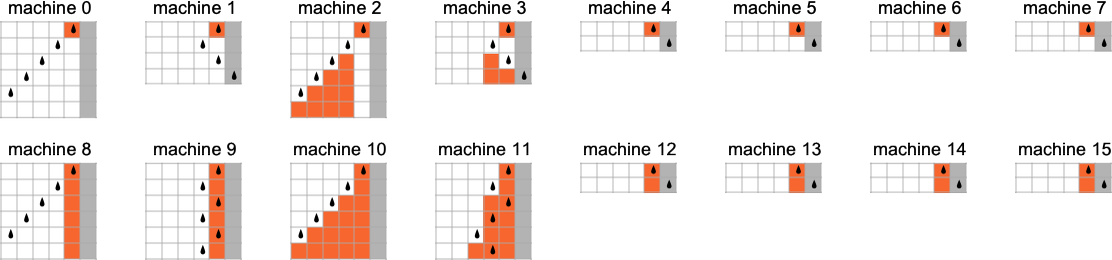
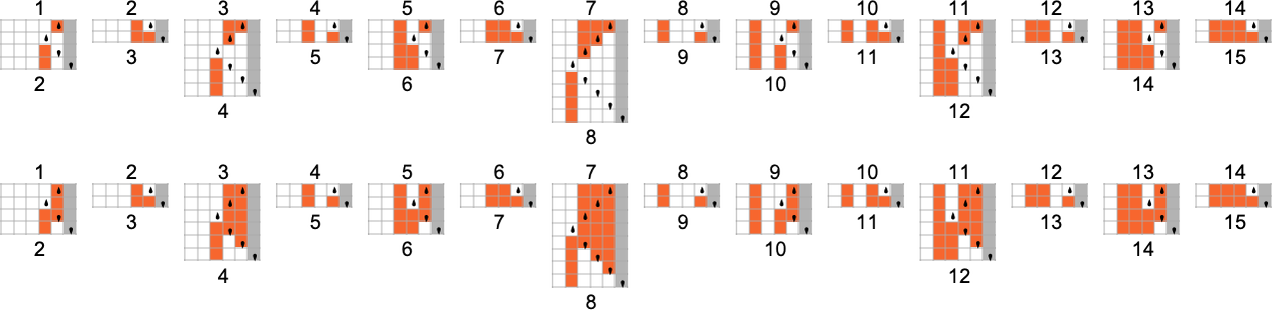
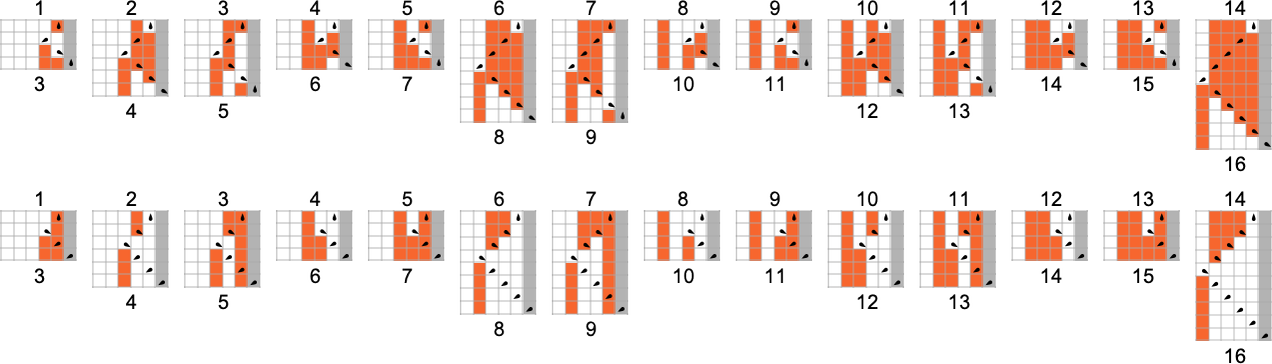
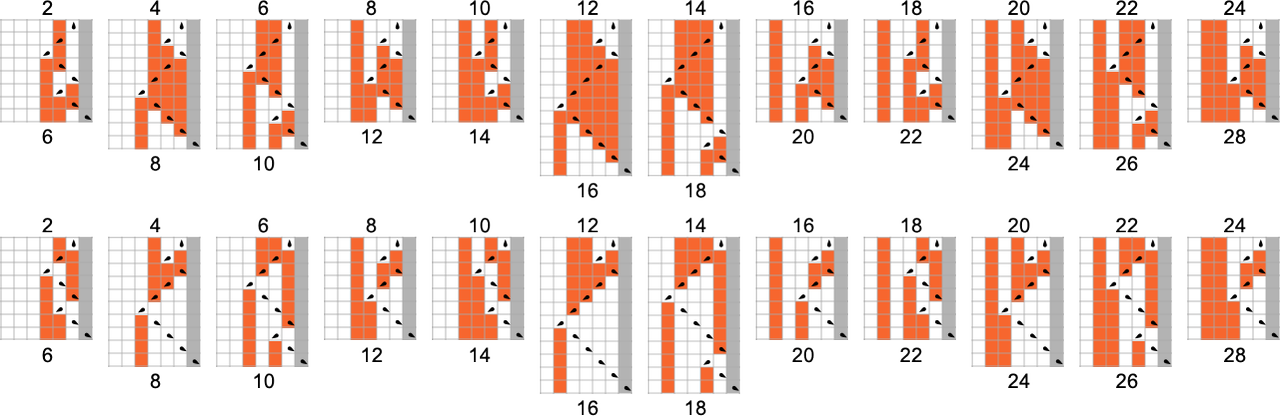
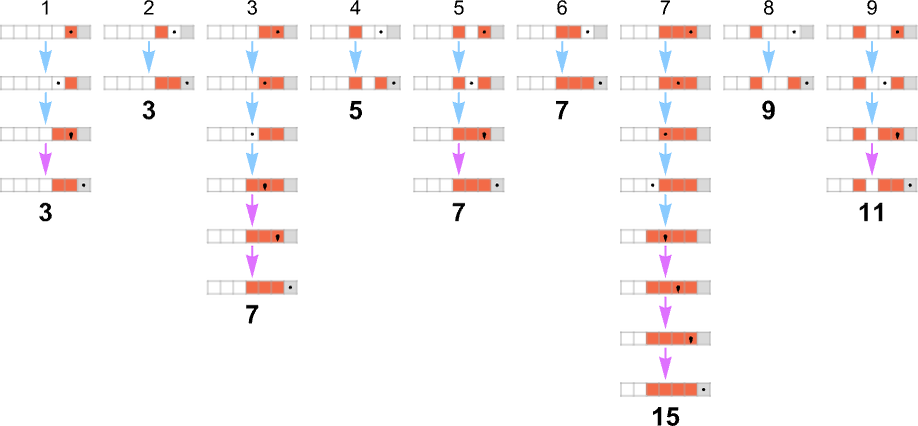
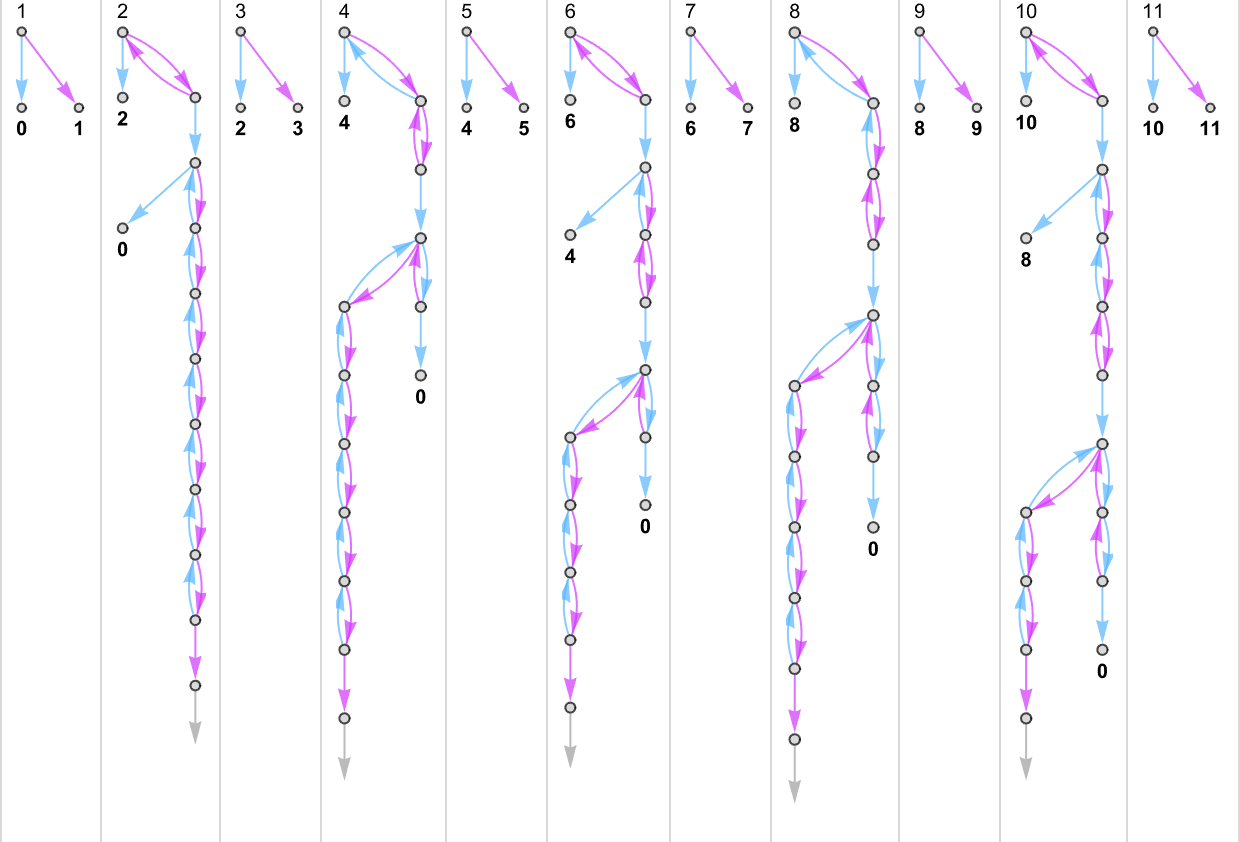
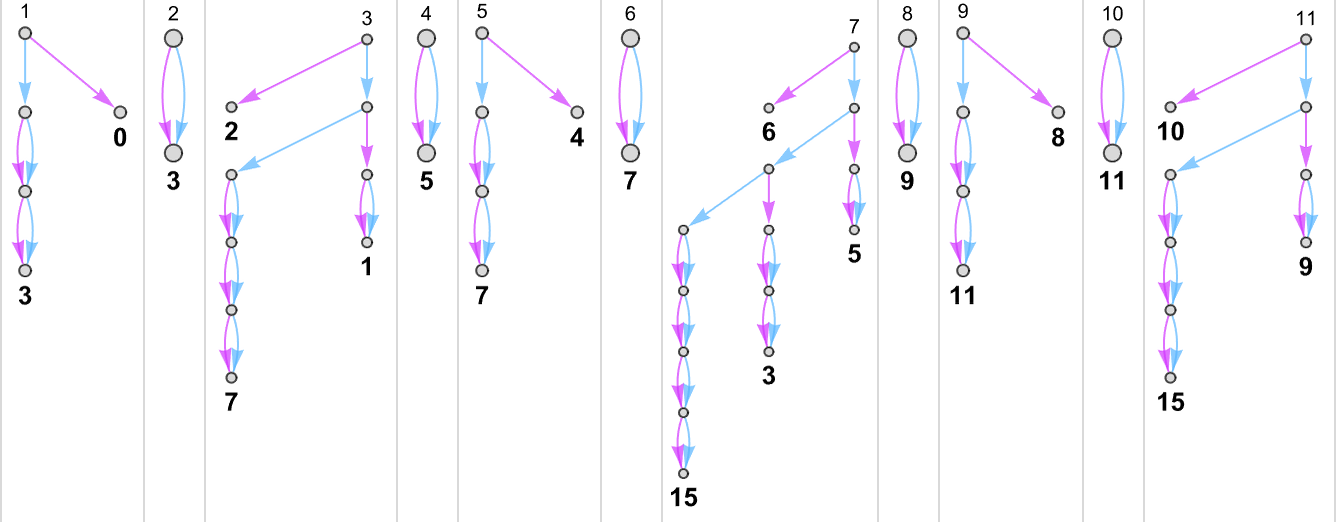
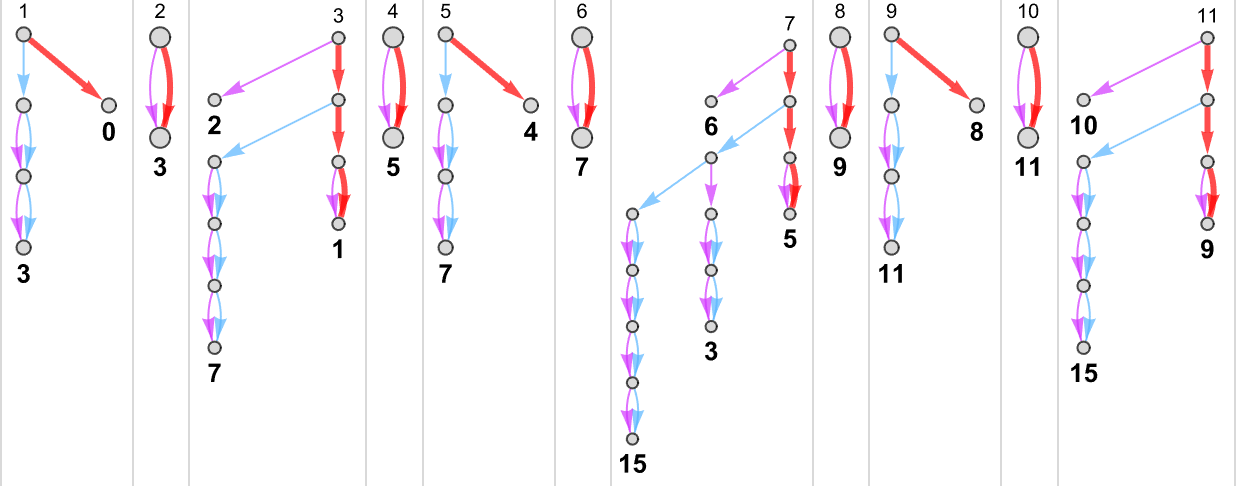
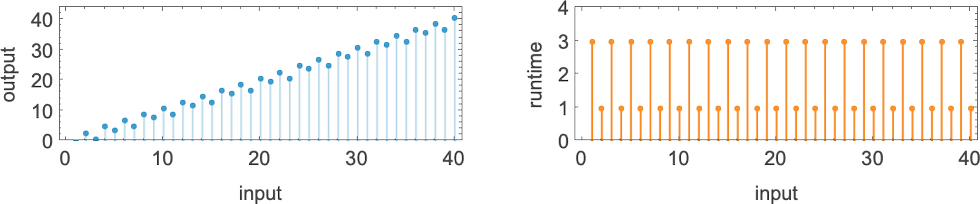
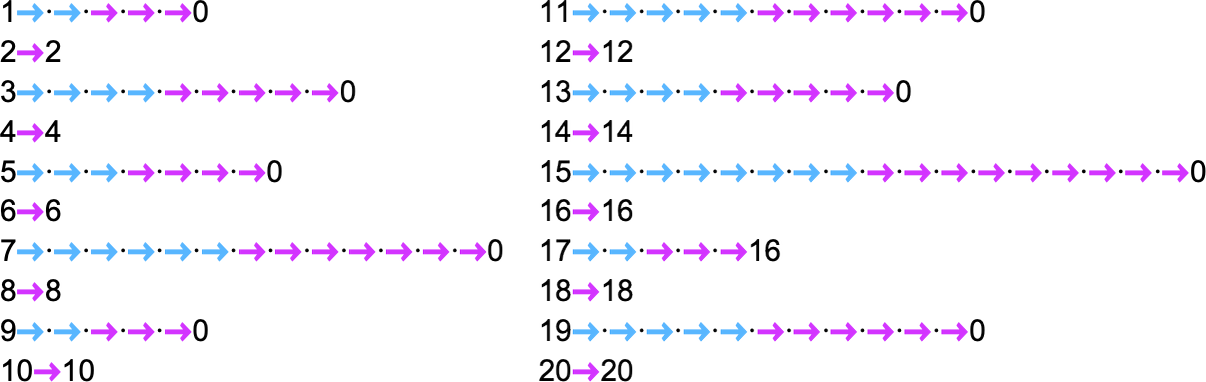
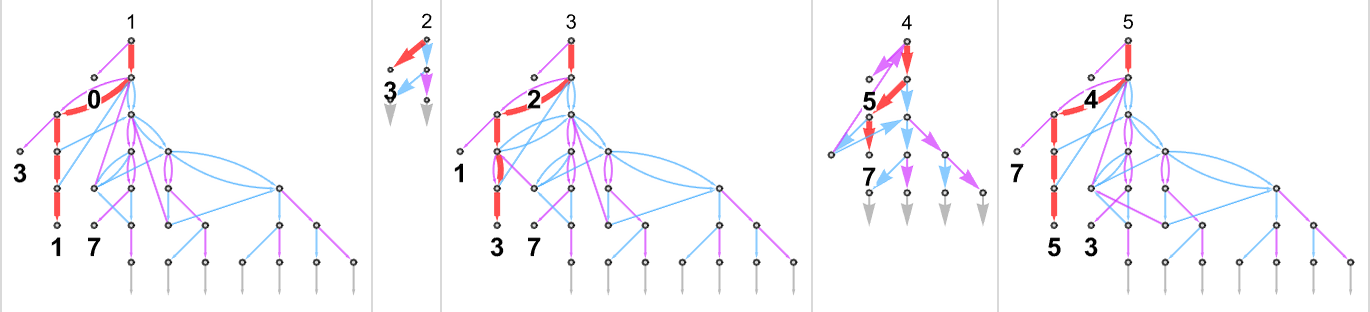
为了开始我们对可能程序的系统调查,让我们考虑本质上最简单的情况:具有 1 个状态和纸带上有 2 种可能颜色的图灵机(s = 1, k = 2)。这类机器只有 16 台——我们可以将其编号为 0 到 15——规则如下:
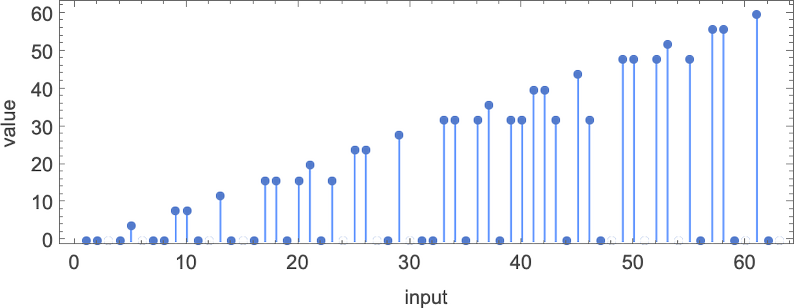
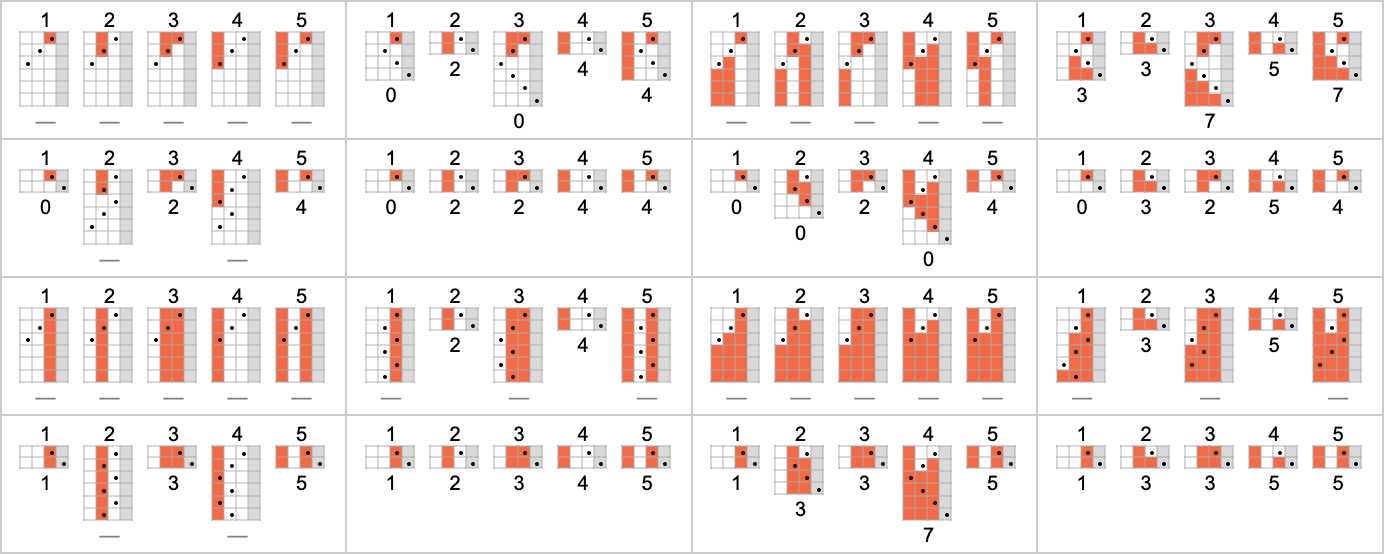
以下是这些机器对连续整数输入的处理结果:
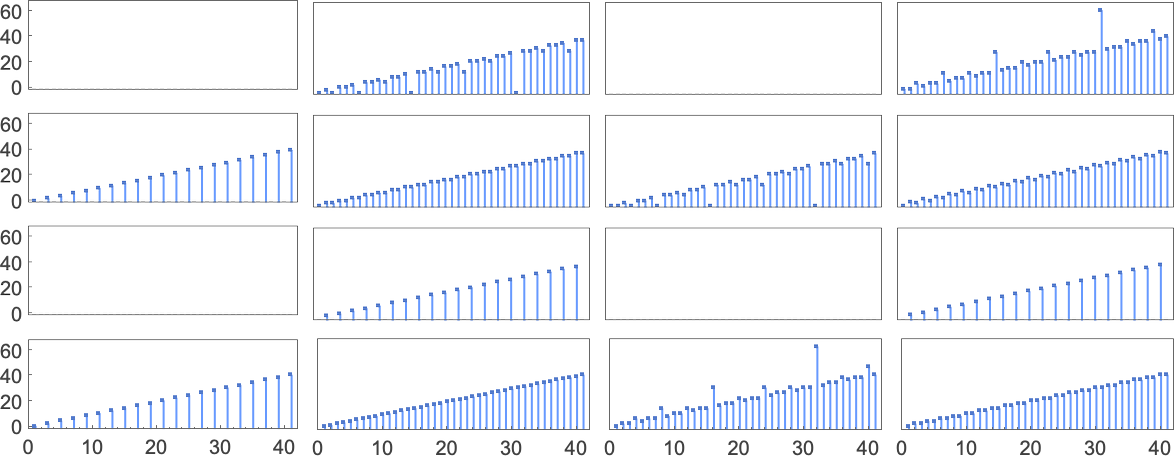
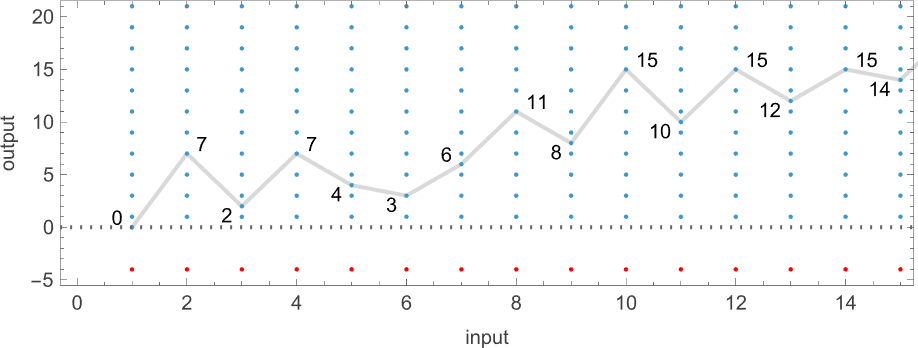
查看每个案例的输出,我们可以绘制它们计算的函数:
这是对应的运行时间:
在所有 16 台机器中,8 台计算全函数(total functions,即机器总是终止,因此函数的每个输入都有定义值),8 台则不是。四台机器产生了“看起来复杂”的函数;一个例子是机器 14,它计算的函数是:

这个函数有多种表示形式,包括:
和:
该函数由图灵机计算的方式如下:
运行时间由下式给出:

对于大小为 n 的输入,这意味着计算该函数的最坏情况时间复杂度为 。时间复杂度为 的大小为 n 的输入的比例为 ——导致中位时间复杂度收敛于常数值 2,平均时间复杂度收敛于 3。
每一台 1 状态机器的工作方式至少略有不同。但最终,它们所有行为都足够简单,我们可以很容易地为任何给定的 i 给出 f[i] 值的“闭式公式”:

值得注意的是——除了所有值都未定义的微不足道的情况外——在 s = 1, k = 2 的图灵机中,没有任何不同的机器计算相同函数的例子。实际上,这种类型的图灵机太少了,以至于不会出现重叠。但是,正如我们将看到的,一旦我们到达 s = 2, k = 2,就会开始出现重叠……
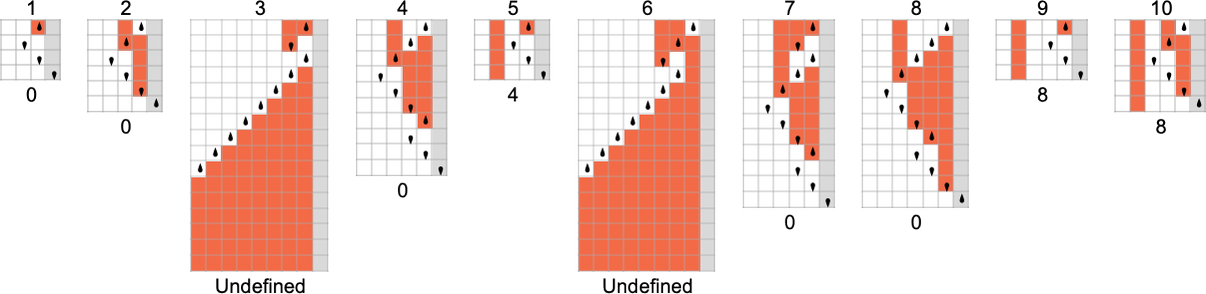
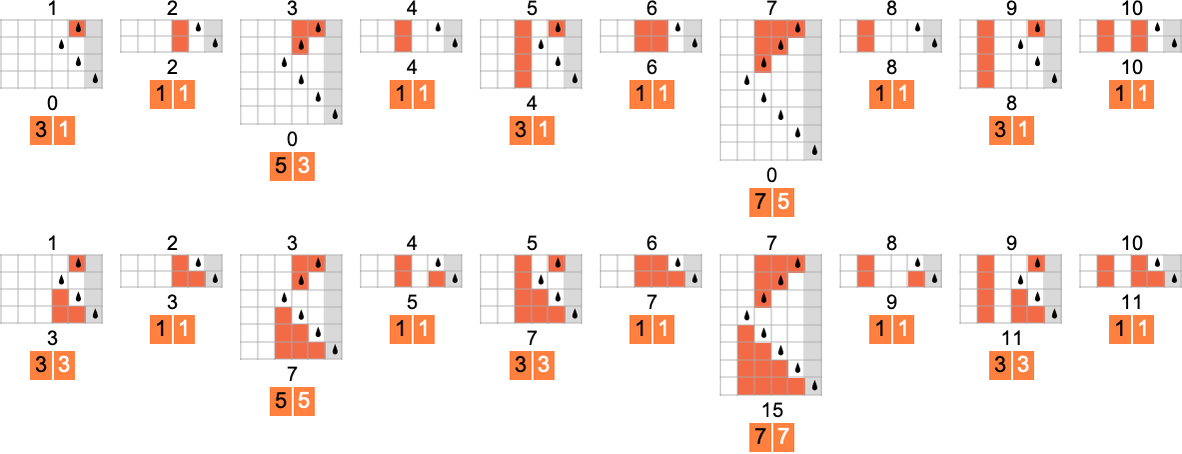
s = 2, k = 2 图灵机
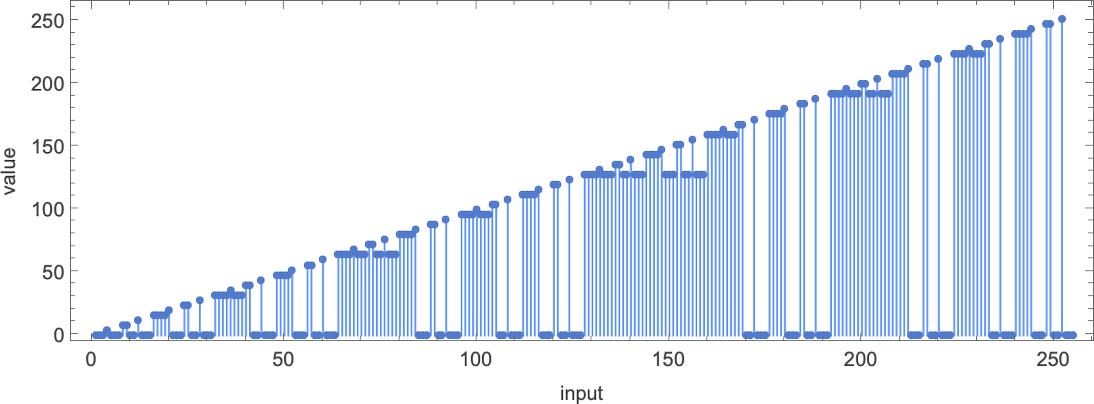
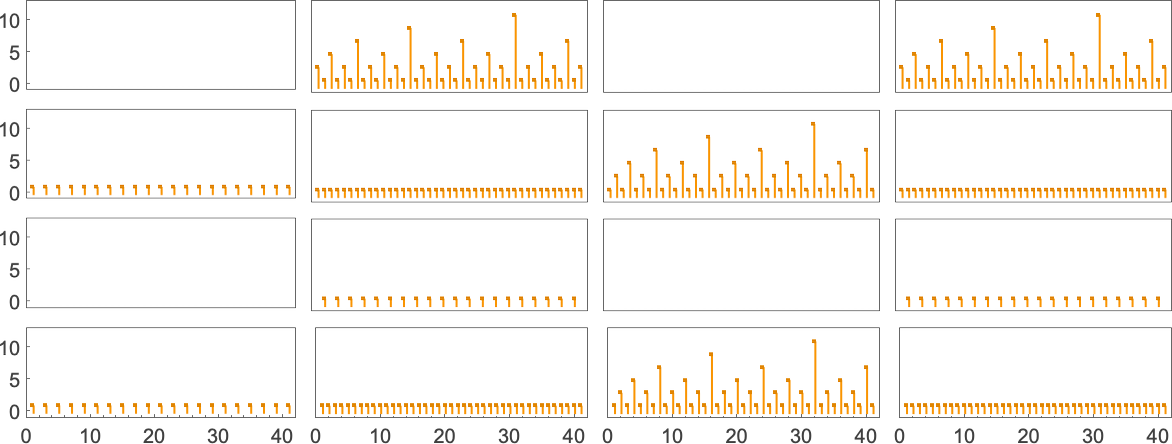
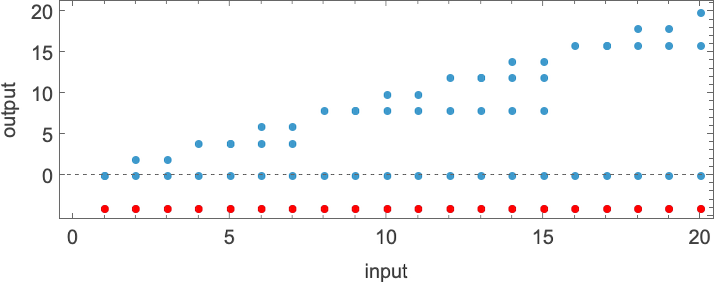
总共有 4096 种可能的 2 状态、2 颜色图灵机。运行所有这些机器,我们发现它们总共计算了 350 个不同的函数——其中 189 个是全函数。以下是这些不同全函数的图表——以及生成它们的机器数量统计(4096 台机器中总共有 2017 台总是终止,因此计算全函数):

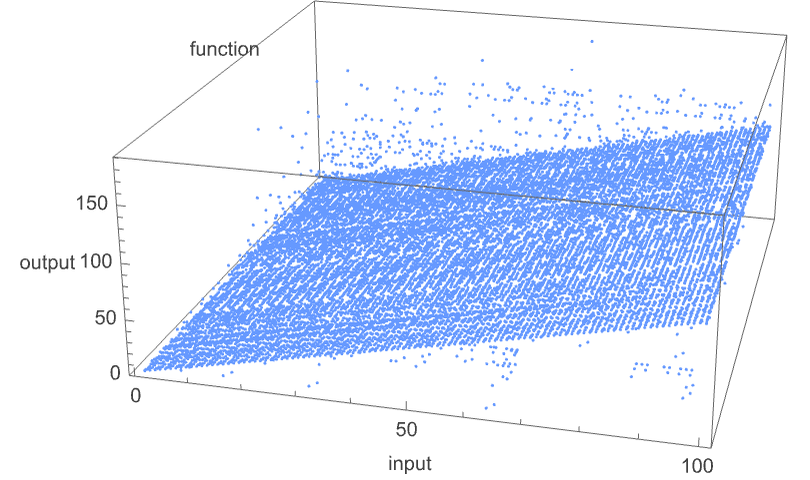
在 3D 中绘制所有这些函数的值,我们看到绝大多数的值 f[i] 都接近其输入 i——这表明在某种意义上,图灵机通常“并没有对输入做太多事情”:
为了更清楚地看到机器“实际做了什么”,我们可以观察量 。我们发现,在 189 个不同函数中的 59 个(以及 1325 台基础机器)里,这个量的值最终是周期的。最常见的周期是 4,如下所示:
尽管在 6 种情况下周期是 2,在 3 种情况下(包括“最流行”的情况 )周期是 1。
去除周期性情况,剩下的不同 是:

我们在这里看到的一些情况与 1 状态的情况相似。机器 2223 出现了不同行为的例子:
其 如下:
在这种情况下, 结果可以简单地表示为:
或者:
另一个例子是机器 2079:
其 如下:
这个函数再次证明可以用“闭式”表达:
有些函数增长很快。例如,机器 3239:
具有值:
这些值具有属性 ,因此 。
即使在处理 2 状态图灵机时也有许多微妙之处。例如,不同的机器可能“看起来”生成相同的函数 直到某个 值,然后才出现偏差。在生成全函数的机器中,这种“惊喜”的最极端例子发生在以下机器中:

直到 i = 26,所有这些机器对所有 i 生成相同的 值。但在 i = 27 时,第一台机器突然 ,而其他机器 :

部分函数呢?至少对于 2 状态机器,如果 中会出现未定义的值,它们总是已经在小的 i 中出现了。“坚持最久”的是机器 1960 和 2972,它们都在输入 8 时首次未定义:
但它们以不同的方式“变得未定义”:在机器 1960 中,读写头系统地向左移动,而在机器 2972 中,读写头周期性地来回移动,永远不会到达右端。(尽管机制不同,但这两种规则都有一个共同特点,即对所有是 8 的倍数的输入都未定义。)
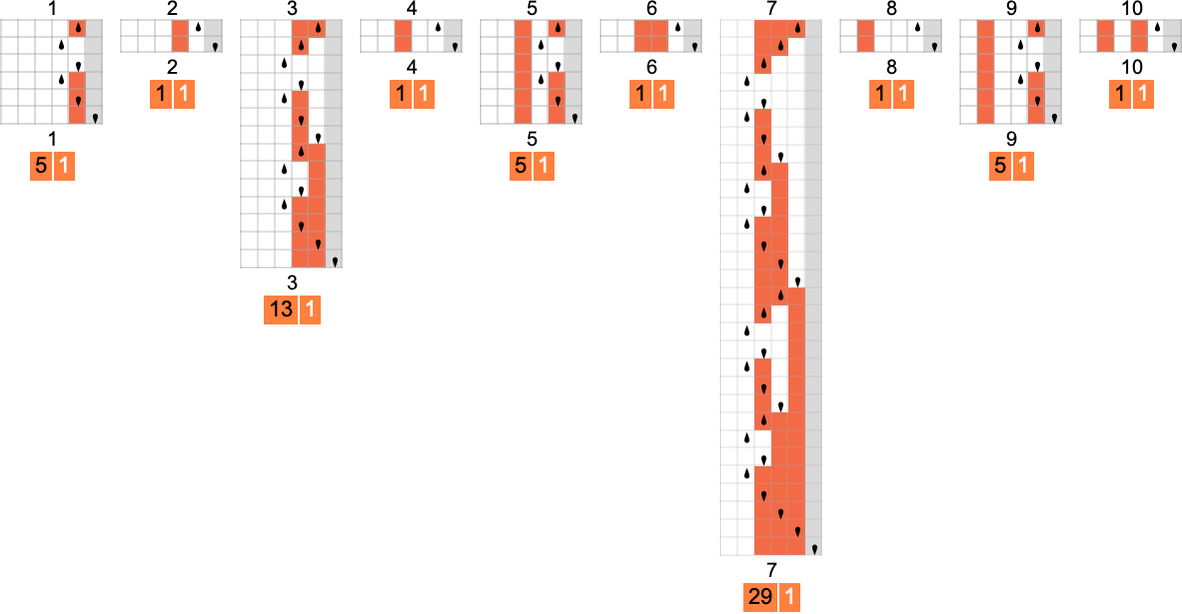
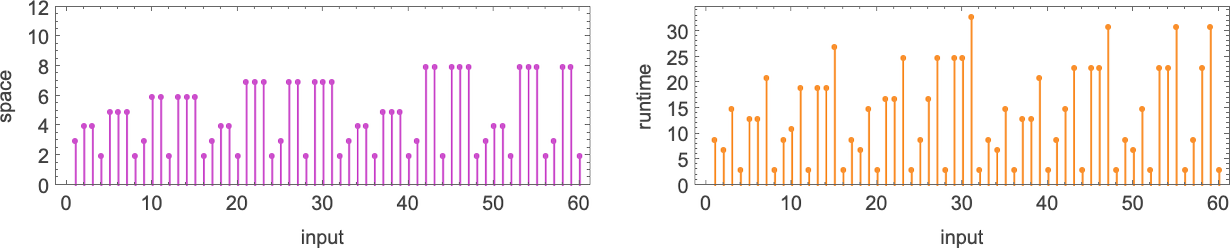
s = 2, k = 2 机器的运行时间
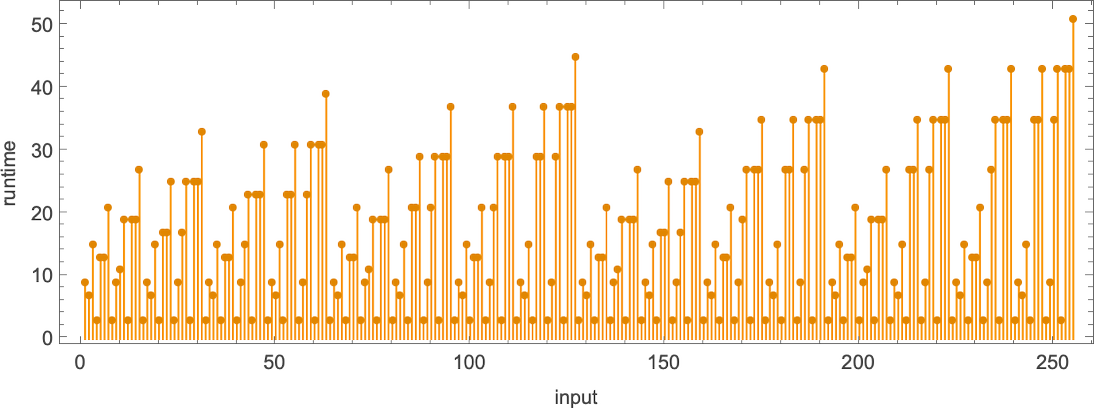
运行时间如何?如果一个函数 由几个不同的图灵机计算,每台机器计算的细节通常至少会略有不同。尽管如此,在许多情况下,机制非常相似,以至于它们的运行时间是相同的。最终,在计算我们的 189 个不同全函数的 2017 台机器中,只有 103 个不同的运行时间与输入的“概况(profiles)”(实际上其中许多非常相似):

如果我们不为每个特定的输入值绘制运行时间,而是绘制给定大小的所有输入的最坏情况运行时间,情况会变得更简单。(实际上我们是针对 IntegerLength[i, 2] 或 Ceiling[Log2[i+1]] 绘图)。结果表明这种最坏情况时间复杂度只有 71 种不同的概况:

实际上,所有这些都有相当简单的闭式形式——对于偶数 n(奇数 n 也有类似的直接形式):

如果我们考虑这些最坏情况运行时间对于大输入长度 n 的行为,我们发现出现的不同增长率相当少——特别是线性、二次和指数情况,但没有中间情况:

增长最快 () 的机器是密切相关的 378 和 1351。两者实际上都“付出了很大努力”——但最终只是计算了恒等函数 :
对于大小为 n 的输入,函数的最大值只是具有 n 位数字的最大整数,或 。最大运行时间 正好出现在这些输入上:
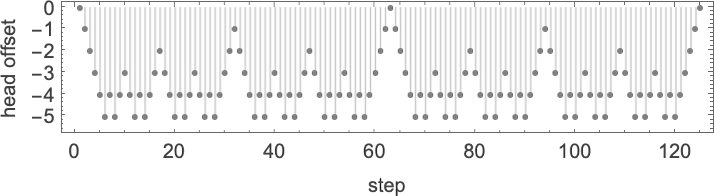
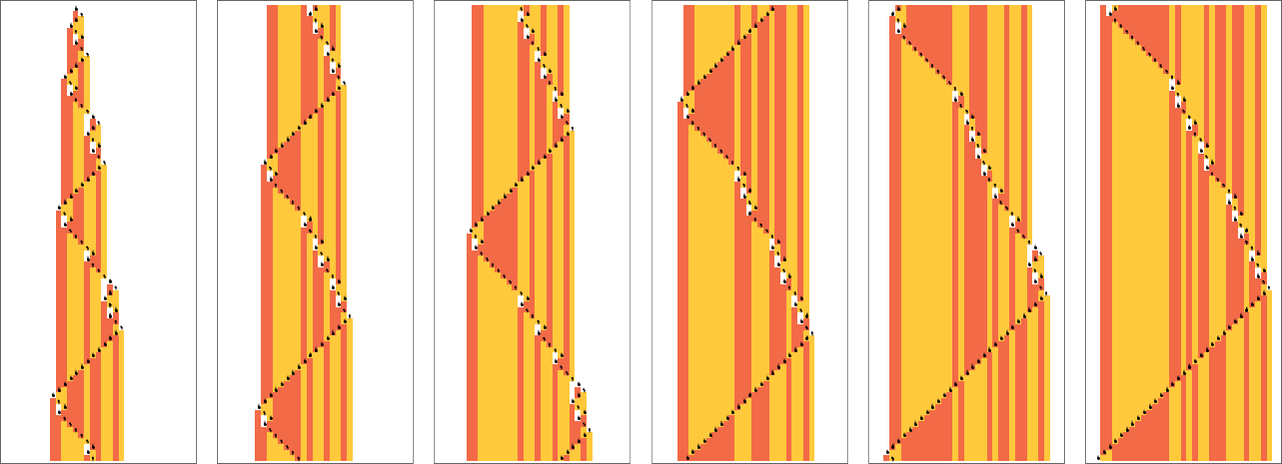
在这些最大值处,机器就像二进制计数器一样运行,生成它可以生成的所有状态,读写头以非常规则的嵌套模式移动:
事实证明,对于 s = 2, k = 2 的图灵机,所有运行时间呈指数增长的机器最终计算的都是相当微不足道的函数——本质上就是恒等函数。在 4 台运行时间渐近增长如 的机器中,3626 和 3717 计算恒等函数 ,而 2289 和 1953 计算 。只有一台机器——924——具有 的渐近运行时间增长;其实际最坏情况运行时间是 ,它计算 。
在 8 台运行时间增长如 的机器中,所有的机器都导致具有嵌套结构的函数,其大小为 n 的输入的最大值增长如 (对应于最大函数值 )——这里显示在一个对数-对数图上:
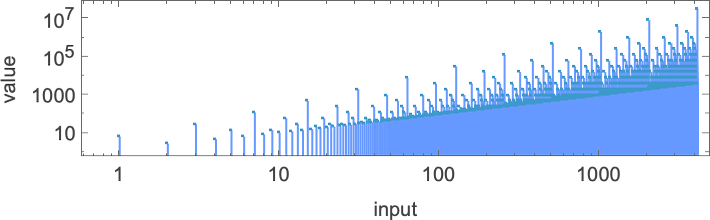
渐近运行时间增长为 的两台机器和渐近运行时间增长为 的机器表现出稍微更复杂的行为(注意函数值在对数-对数图上):
这是这些机器在输入 1 到 10 时的实际行为:
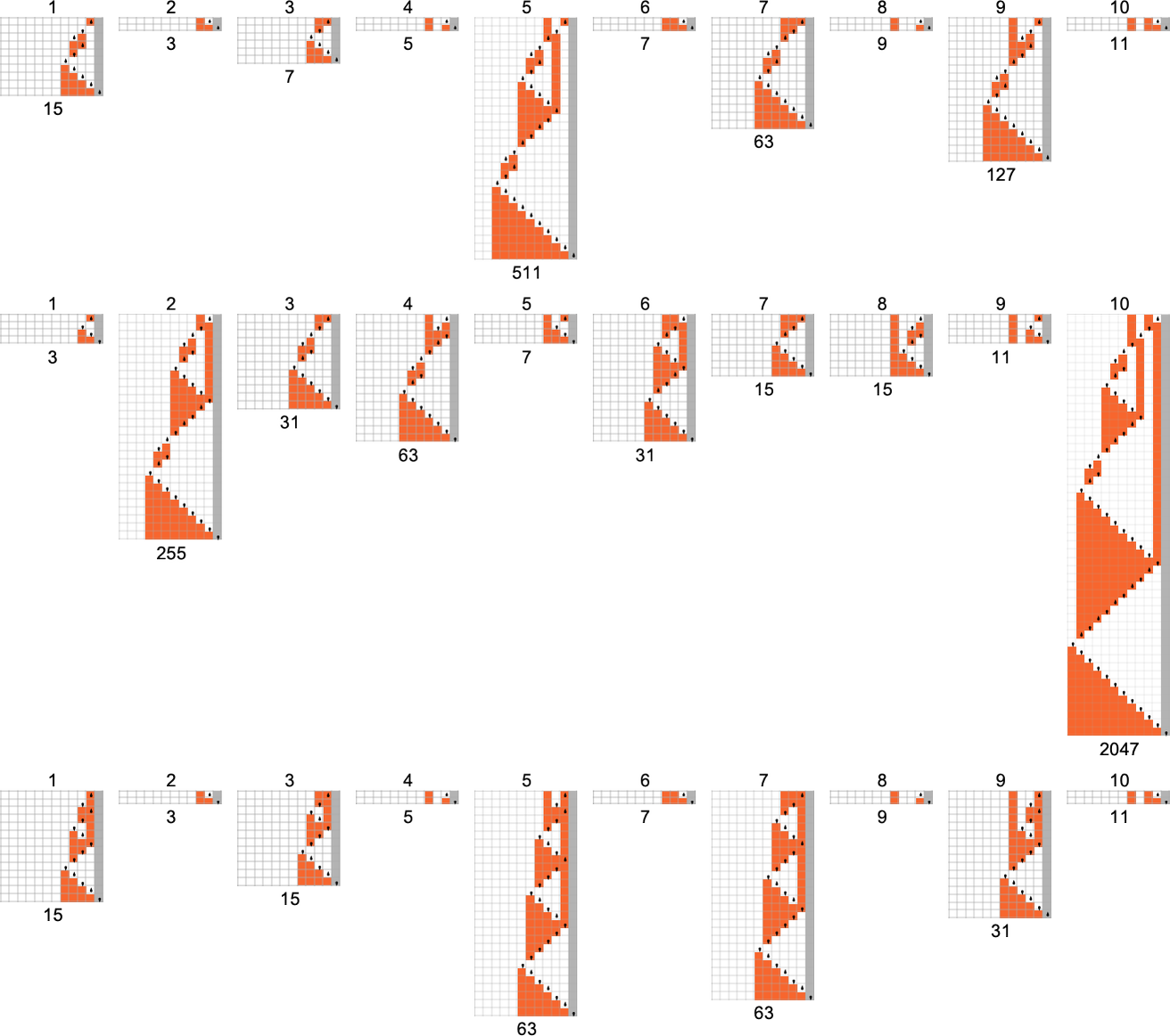
(在二次和指数之间缺乏中间运行时间是值得注意的——也许让人想起在有限生成群和多路系统中看到的那种罕见的“中间增长”。)
运行时间分布
到目前为止,我们的重点是最坏情况运行时间:任何给定大小的输入所需的最大运行时间。但我们也可以询问给定大小的输入内运行时间的分布。
例如,这里是一个典型图灵机(s = 2, k = 2, 机器 3111)所有大小为 11 的输入的运行时间:

这里的最大值(“最坏情况”)是 43——但中位数只有 13。换句话说,虽然有些计算需要一段时间,但大多数运行得更快——因此运行时间分布在小值处达到峰值:
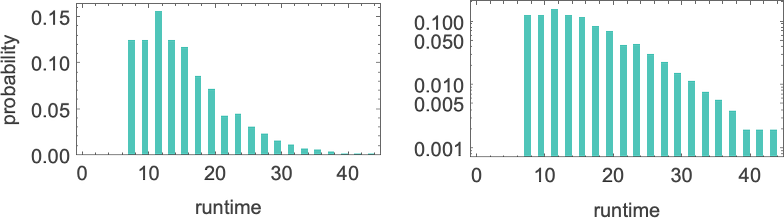
(根据我们图灵机的设置方式,它们总是在终止前运行偶数步——因为要终止,读写头必须为每一个向左的移动向右移动一个位置。)
如果我们增加输入的大小,我们会看到分布(至少在这种情况下)接近指数分布:
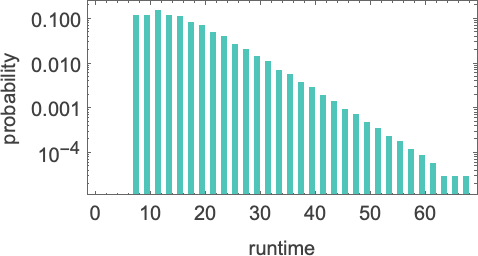
事实证明,这种指数分布是我们几乎在所有图灵机中看到的典型分布。(值得注意的是,这与我们预期的如果图灵机读写头“平均”执行带有吸收边界的随机游走时的 “停机时间”分布有很大不同。)尽管如此,有些机器的分布与指数分布有显著偏差,例如:
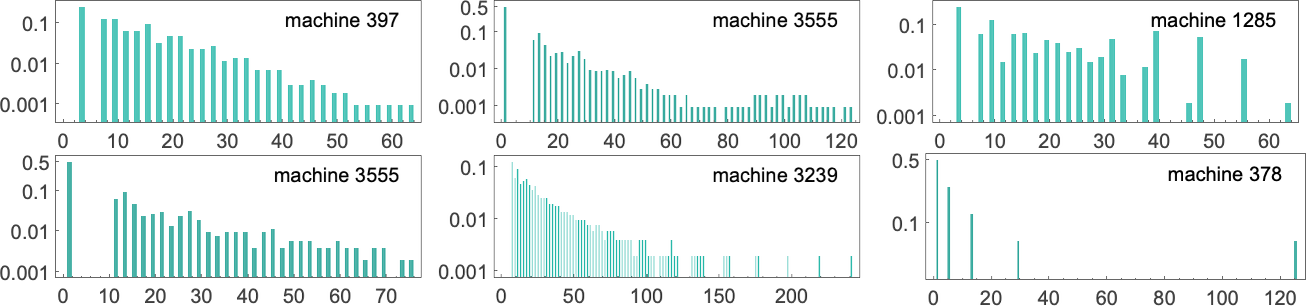
有些只是有长尾指数。然而,其他的则具有整体非指数的形式。
函数计算能有多快?
我们现在已经看到了 s = 2, k = 2 图灵机可以产生的大量函数——以及运行时间概况。这使我们能够进一步讨论我们的核心问题:计算函数能有多快?
我们已经看到有些机器计算函数相当慢——比如用指数时间。但是,这些机器是计算这些特定函数的最快机器吗?事实证明,答案是否定的。
如果我们查看 s = 2, k = 2 机器计算的所有 189 个全函数,并询问计算这些函数的最快机器有多快,我们会发现以下情况:

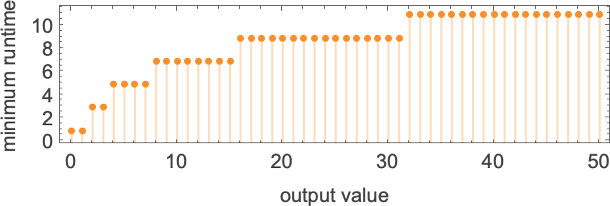
换句话说,对于 s = 2, k = 2 图灵机,有 8 个函数是“最难计算的”——这类机器无法在小于 的时间内计算它们。
这些函数是什么?这是其中之一(由机器 1511 计算):

如果我们绘制这个函数,它似乎具有嵌套形式:
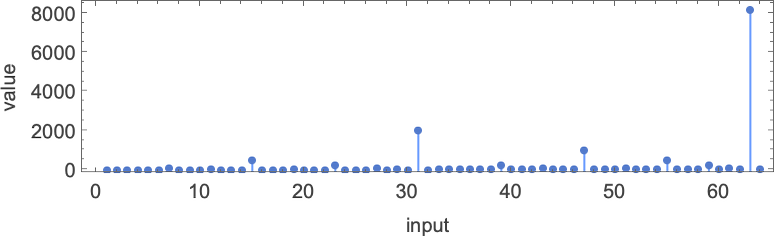
这在对数-对数图上变得更加明显:
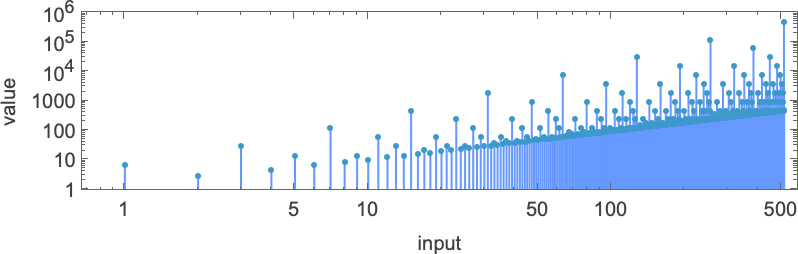
事实证明,这个函数有一个相当于“闭式”的形式:
尽管不像我们上面看到的闭式形式,这个涉及 Nest,并且有效地递归计算其结果:

机器 1511 怎么样?它是这样计算这个函数的——实际上显而易见地使用了递归:
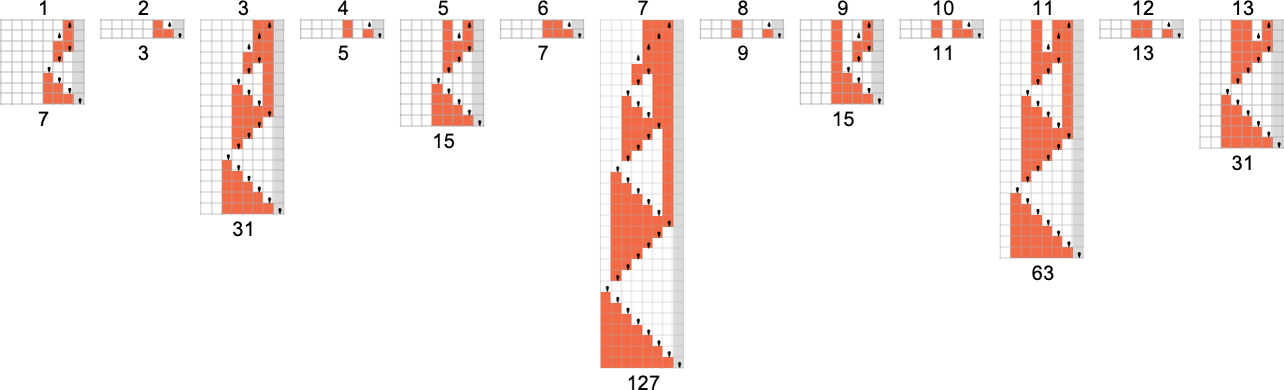
运行时间为:
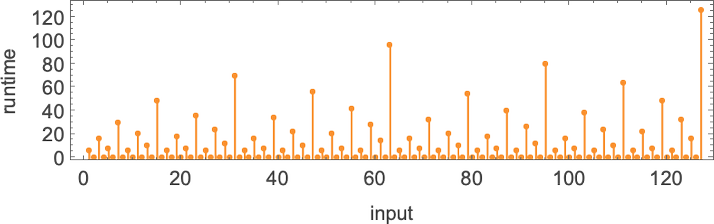
对于大小为 n 的输入,给出的最坏情况运行时间形式为:
事实证明,所有 8 个最小运行时间增长如 的函数的工作原理都非常相似——计算它们的确切运行时间为:

对于最快计算时间为 和 的函数,我们在上一节中看到了这些函数的形式以及计算它们的图灵机的行为。这些机器的运行时间(对于偶数 n)为:

那么我们可以得出什么结论?我们现在知道有些函数无法被 s = 2, k = 2 图灵机以快于二次的时间计算。换句话说,通过穷尽所有 s = 2, k = 2 图灵机,我们已经建立了这些函数计算时间的下界——至少在这类图灵机中。
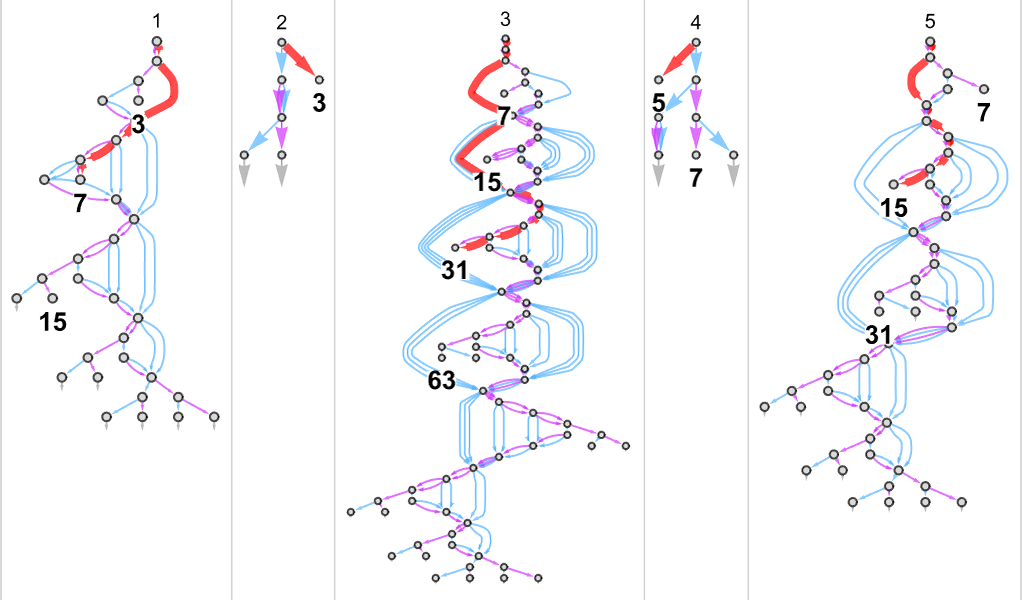
以不同速度计算相同函数
我们现在知道某些函数被 s = 2, k = 2 图灵机计算的最快速度。但是,同样的函数是否也可以被同类型的其他机器更慢地计算?事实证明,对于我们在上一节中讨论的情况,只有一台 s = 2, k = 2 图灵机可以计算这些函数中的每一个。换句话说,用 s = 2, k = 2 图灵机计算这些函数既没有更快的方法,也没有更慢的方法。
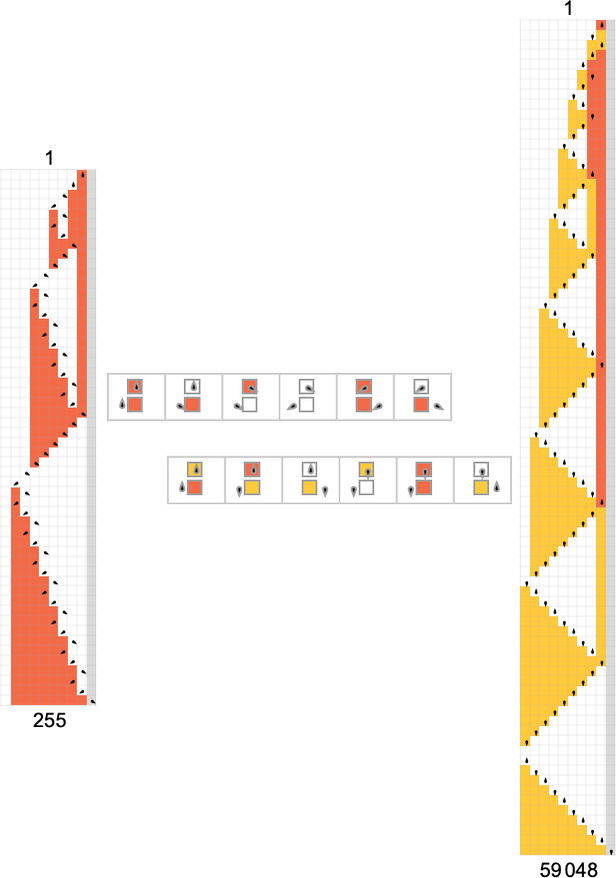
事实上,只有一台机器计算给定函数的情况很常见。在 s = 2, k = 2 图灵机可以计算的 189 个全函数中,有 105 个只能由这样的一台机器计算。尽管如此,还有其他函数由多台机器计算——最极端的例子是恒等函数 ,它竟然可以由不少于 299 台不同的机器计算:

好的,如果多台机器计算相同的函数,我们可以问它们的速度如何比较。结果表明,对于我们的 189 个全函数中的 145 个,所有计算相同函数的不同机器都以相同的“运行时间概况”(即每个输入 i 的运行时间相同)进行计算。但这留下了 44 个具有多个运行时间概况的函数:

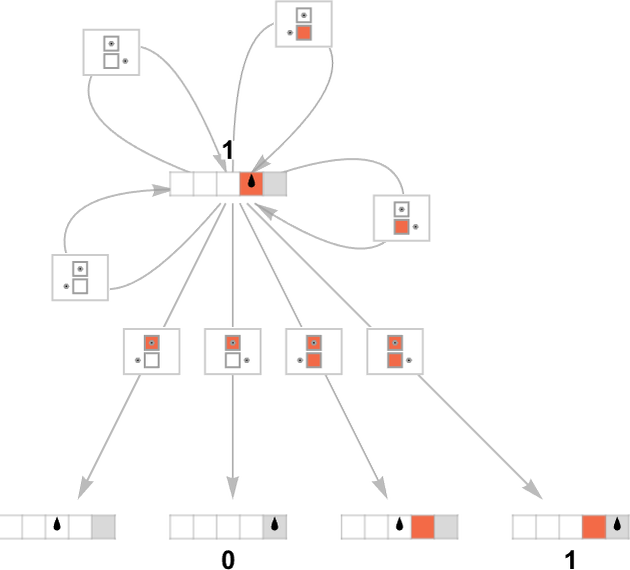
以下是所有这 44 个函数,以及计算它们的机器的不同运行时间概况:
很多时候我们看到计算给定函数的可能运行时间概况差异很小。但有时差异更显著。例如,对于恒等函数 ,共有 299 台机器计算它,结果有 10 种不同的运行时间概况:
在这 10 种概况中,按输入大小的最坏情况运行时间有 3 种不同的增长率:常数、线性和指数:

分别以机器 3197、3589 和 3626 为例:
当然,计算这个特定函数有一种微不足道的方法——只要有一个不改变输入的图灵机即可。不用说,这样的机器对于所有输入的运行时间都是 1:

事实证明,对于 s = 2, k = 2 图灵机,唯一表现出如此大运行时间范围的全函数是恒等函数 ,以及密切相关的 ——例如由机器 829、926 和 924 计算:
但是,虽然在任何其他(全)函数中都没有出现最坏情况运行时间的不同“增长阶数”,但在运行时间中仍有许多特定的变化——无论是整体规模的变化,还是“周期性”的变化。例如,机器 773、897 和 919 都计算函数:

通过稍微不同的方法:
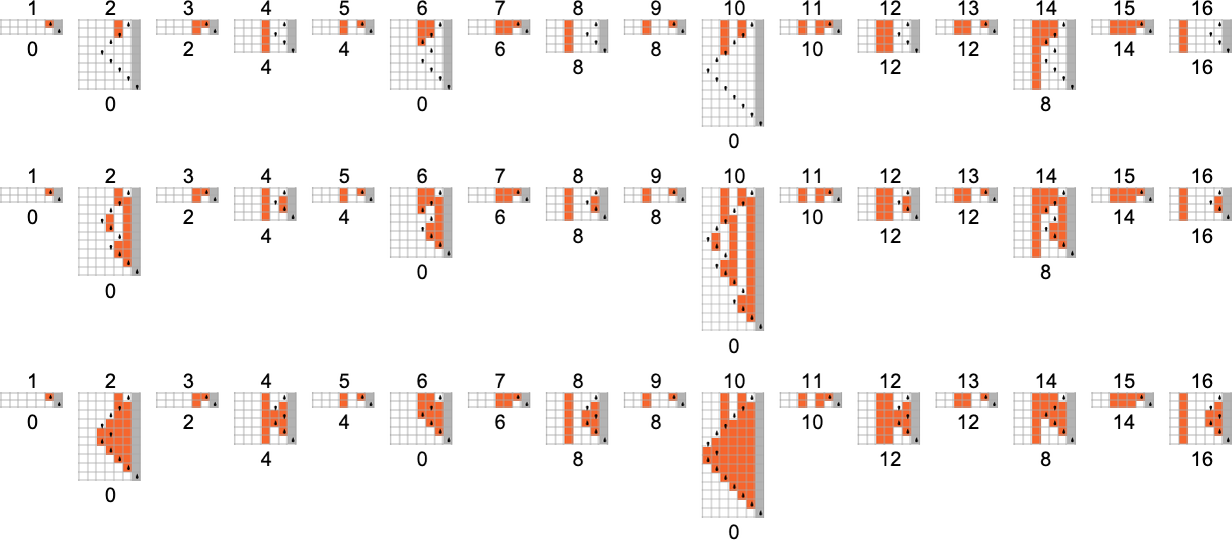
具有不同的最坏情况运行时间概况:

或者:
顺便说一句,如果我们考虑部分函数而不是全函数,没有什么特别不同的事情发生,至少对于 s = 2, k = 2 图灵机是这样——唯一的线性 vs. 指数运行时间与如下机器有关:
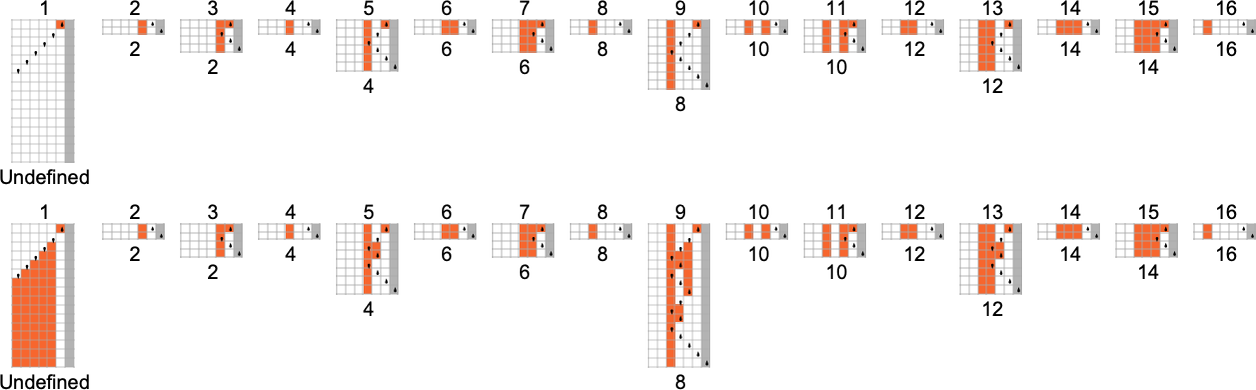
它们本质上还是在计算恒等函数。
另一个问题是 s = 2 图灵机与 s = 1 相比如何。不足为奇的是,有许多 s = 2 机器可以计算与 s = 1 机器相同的函数:
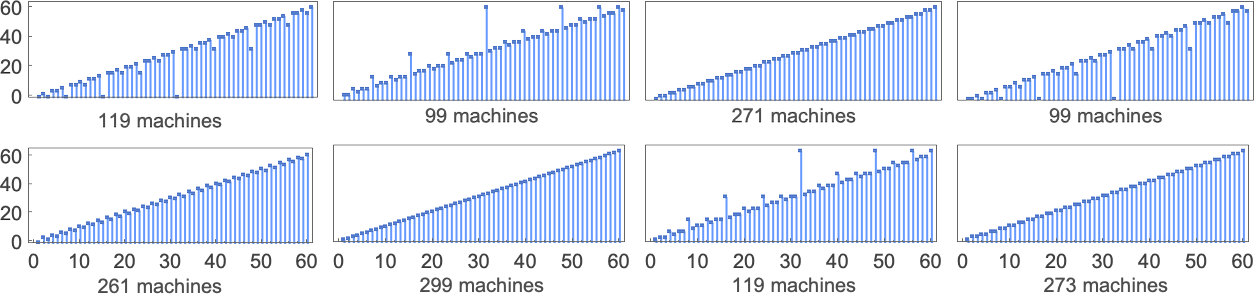
但计算速度如何?这比较了 s = 2 机器和(紫色)计算相同函数的 s = 1 机器的可能最坏情况运行时间:

总会有 s = 2 机器以与 s = 1 机器相同的速度计算。只需要 s = 2 机器的规则在从 s=1 开始时永远不“访问”其第二个状态,如下所示:
但是 s = 2 机器能比对应的 s = 1 机器运行得更快吗?答案是否定的。通常 s = 2 机器倾向于更慢,基本上是因为它们做了更多的“闲逛(puttering around)”,如下所示:
绝对下界和机器的效率
我们已经看到,不同的图灵机计算特定函数可能花费不同的时间。但是,任何可以想象的图灵机——即使在原则上——计算给定函数能有多快?
运行时间有一个明显的绝对下界:按照我们的设定,如果图灵机要接受输入 i 并生成输出 j,其读写头必须至少能够向左移动得足够远,以触及从 i 变为 j 时需要更改的所有位——以及回到右端以便机器停机。这所需的步数是:
对于高达 8 位的 i 和 j 值,其为:
那么实际图灵机计算的运行时间与这些绝对下界相比如何?
这是 s = 1, k = 2 机器 1 和 3 的行为,对于每个输入,我们给出实际运行时间以及绝对下界:
在第二种情况下,机器总是尽可能的绝对高效;在第一种情况下,它只是有时是——尽管最大减速只有 2 步。
对于 s = 2, k = 2 机器,差异可能会大得多。例如,机器 378 可能需要指数时间——即使这种情况下的绝对下界只有 1 步,因为这台机器计算的是恒等函数:
这是另一个例子(机器 1447),其实际运行时间总是大约是绝对下界的两倍:
但是,计算给定函数的任何 s = 2 图灵机的最小(最坏情况)运行时间与绝对下界相比如何?好吧,在一个预示着我们稍后在讨论 P vs. NP 问题时会看到的结果中,差异可能越来越大:

这里计算的函数是:

做到这一点的最快 s = 2 图灵机是(机器 2205、3555 和 2977):

我们的绝对下界决定了图灵机生成给定输出可能有多快。但也可以将其视为衡量图灵机在生成给定输出时“实现”了多少。如果输出与输入完全相同,图灵机实际上“什么也没实现”。它们差异越大,就可以认为机器“实现”得越多。
所以现在我们可以问一个问题:是否存在这样的函数,在从输入到输出的转换中实现得很少,但执行这种转换的最小运行时间仍然很长?人们可能会想到恒等函数——实际上“什么也没实现”。实际上我们已经看到,有图灵机计算这个函数,但速度很慢。然而,也有机器能快速计算它——所以在某种意义上,它的计算不需要很慢。
上面由机器 2205 计算的函数是一个稍微好一点的例子。随着输入大小 n 的增加,输入和输出之间的(最坏情况)“距离”增长如 ,但计算该函数的最快速度是机器 2205 所做的,其运行时间增长如 。是的,这些在 n 上仍然都是线性的。但这在某种程度上是一个例子,说明一个函数“不需要慢就能计算”,但在计算上至少有些慢——至少对于任何 s = 2, k = 2 图灵机而言。
空间复杂性
计算一个函数的值有多难,比如用图灵机?衡量标准之一是所需的时间,或者更具体地说,需要多少个图灵机步骤。但另一个衡量标准是它占用了多少“空间”,或者更具体地说,在我们的设定下,图灵机读写头向左移动了多远——这决定了必须存在多少“图灵机内存”或“纸带”。
这是特定图灵机中使用的“空间”与“时间”比较的典型例子:
如果我们查看作为输入大小函数的所有可能的空间使用概况,我们会发现——至少对于 s = 2, k = 2 图灵机——结果相当平淡;空间使用要么变为常数,要么基本上随输入大小线性增加:
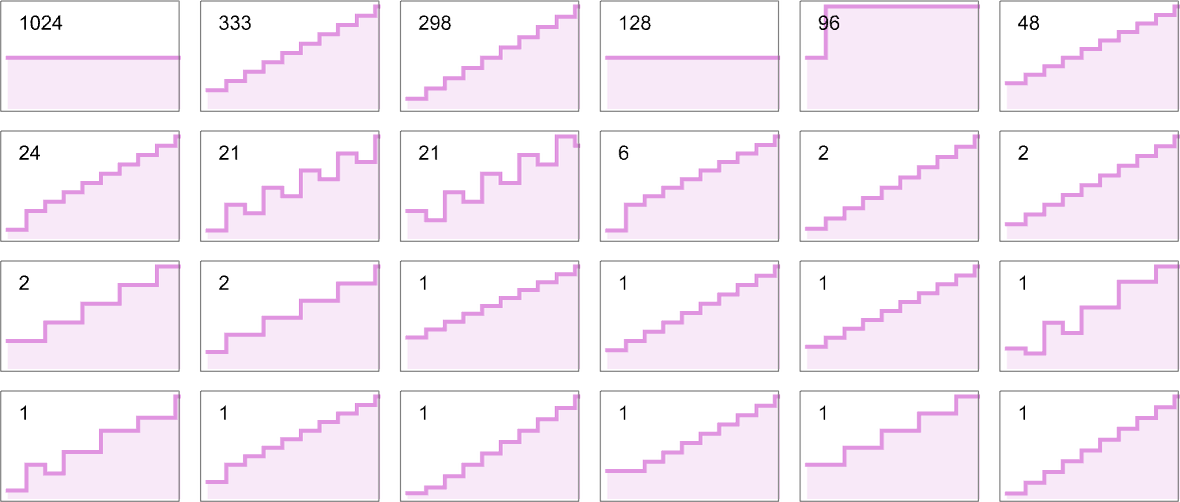
(人们还可以考虑不同的“复杂性”度量——也许适用于不同类型的理想化硬件。例如,查看读写头遍历的路径总长度、读写头划定区域的总面积、计算过程中将 1 写入纸带的次数等。)
跨机器的特定输入运行时间分布
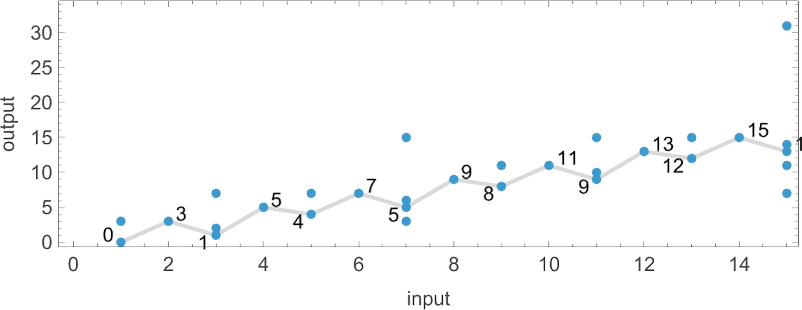
我们已经讨论了很多关于特定机器的运行时间如何随输入(或输入大小)变化。但是关于互补的问题呢:给定一个特定输入,运行时间在不同机器之间如何变化?例如,考虑 s = 1, k = 2 图灵机。这是所有 16 台此类机器从输入值 1 开始的情况:
这些机器的运行时间是:

如果我们继续到更大的输入,我们会看到:

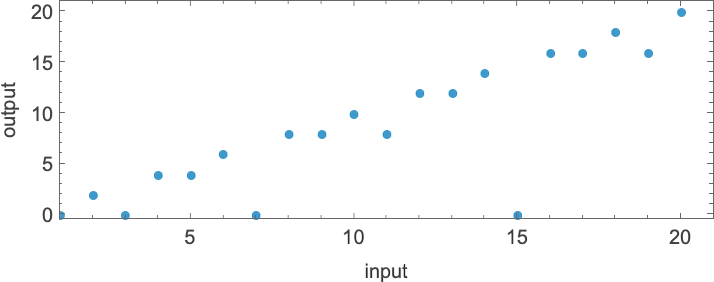
所有 s = 1, k = 2 机器的最大(有限)运行时间随输入 i 变化如下:

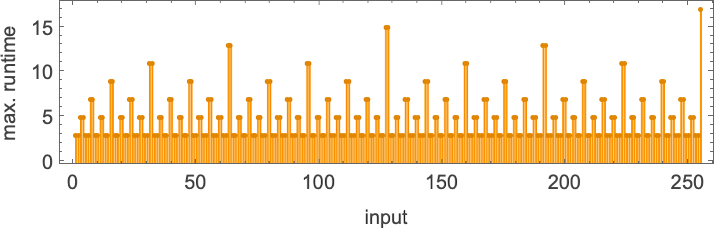
或闭式形式:
对于 s = 2, k = 2 机器,输入 1 的运行时间分布是:
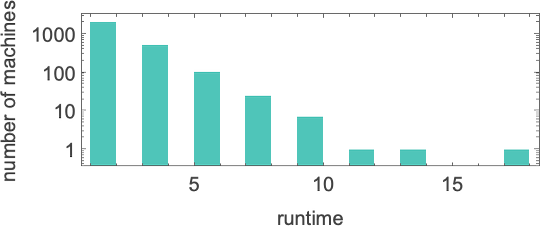
其中最大值 17 由机器 1447 实现。对于更大的输入,最大运行时间是:

绘制这些最大运行时间:
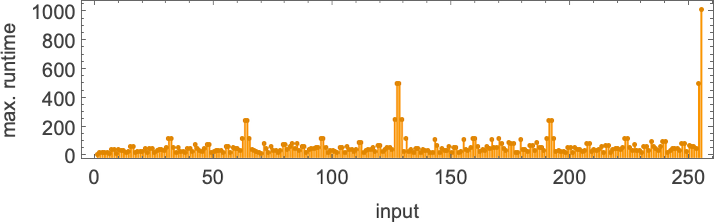
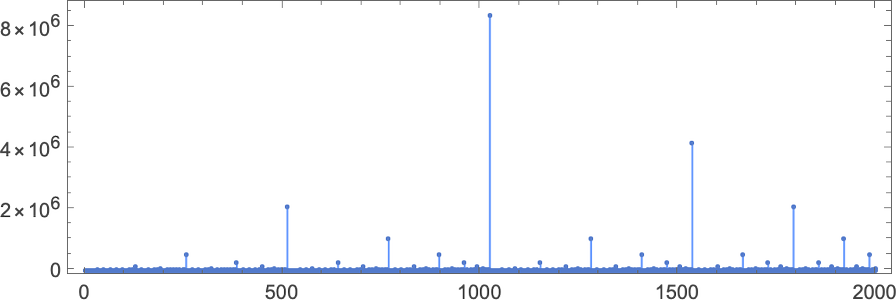
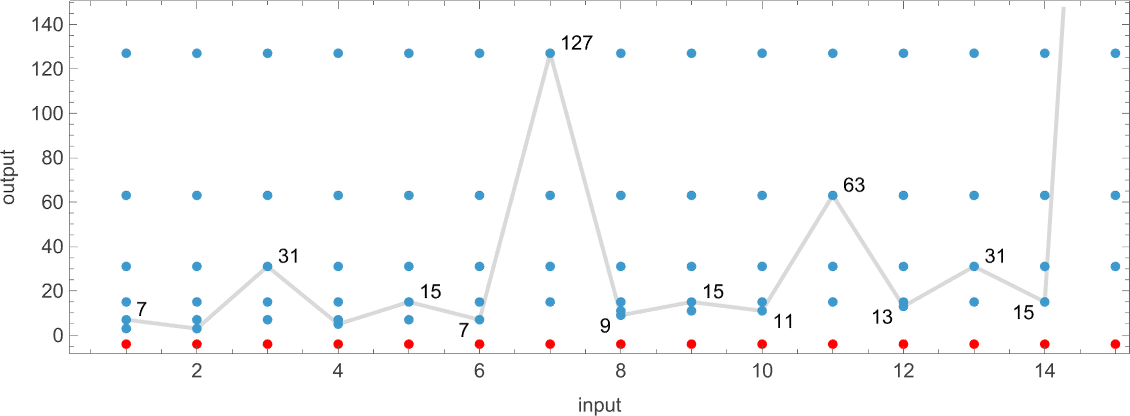
我们在输入 127 处看到一个大峰值,对应于运行时间 509(由机器 378 和 1351 实现)。是的,绘制所有机器输入 127 的运行时间分布,我们看到这是一个显著的离群值:
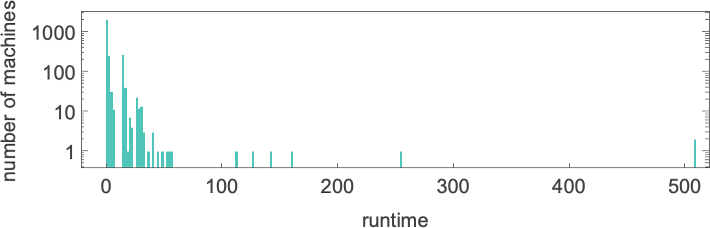
如果计算所有机器和所有输入的运行时间最大值,对于逐渐增大的输入尺寸,可以得到(再次由机器 378 和 1351 主导):

顺便说一句,不仅可以计算运行时间,还可以计算跨机器最大化的值和宽度:

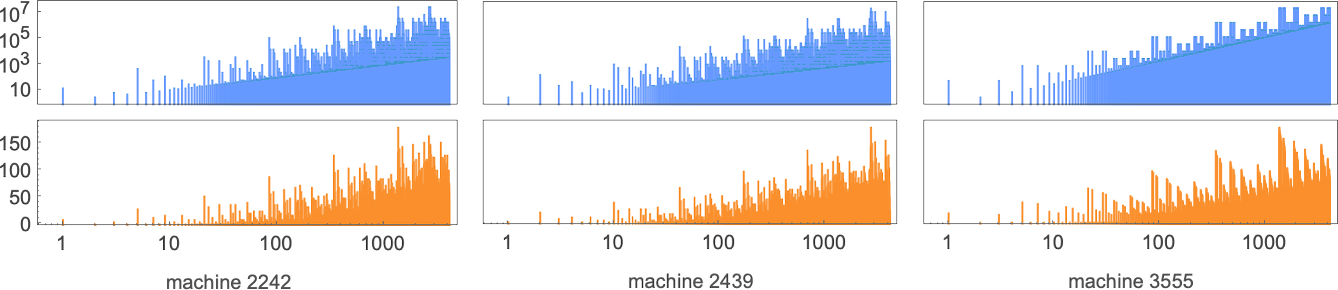
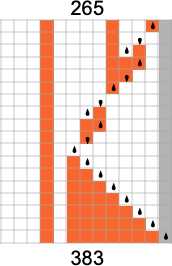
不,最大值并不总是 的形式:第一个不是的情况是输入 265——它是 383,由机器 2242 生成:
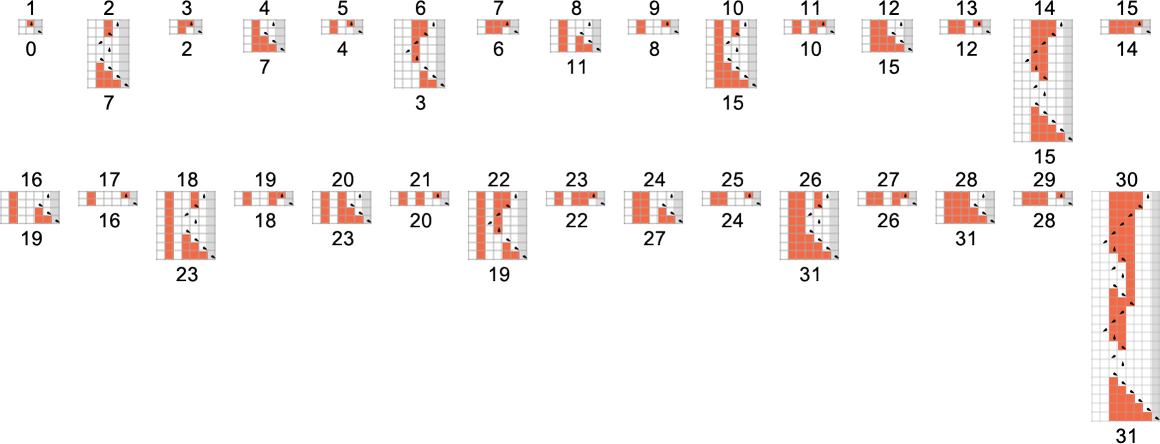
s = 3, k = 2 图灵机与不可判定性问题
到目前为止,我们已经研究了 s = 1, k = 2 和 s = 2, k = 2 图灵机。现在让我们谈谈 s = 3, k = 2 机器。总共有 2,985,984 台这样的机器。这似乎是一个简单的问题:这些机器可以计算多少个不同的函数?但实际上这个问题绝不简单。
问题——一如既往——在于计算不可约性。假设你有一台机器,试图弄清楚它是否计算某个特定函数。或者你只是想弄清楚对于输入 i 它是否给出输出 j。好吧,你可能会说,为什么不直接运行这台机器呢?当然可以。但问题是:你应该运行它多久?假设机器已经运行了一百万步,仍然没有产生任何输出。机器最终会停止并产生输出 j 或其他输出吗?还是机器会永远运行下去,永远不产生任何输出?
如果机器的行为是计算可约的,那么你可以期望能够“跳跃前进”并弄清楚它会做什么,而无需遵循所有步骤。但如果是计算不可约的,那么你就不能指望这样做。这是一种典型的停机问题情况。你必须得出结论:确定机器是否会产生例如输出 j 的一般问题是不可判定的。
当然,在许多特定情况下(比如对于许多特定输入),可能很容易知道会发生什么,或者只需运行一定数量的步数,或者使用某种证明或其他抽象推导。但重点是——由于计算不可约性——所需的计算工作量没有上限。因此,“总是得到答案”的问题必须在形式上被视为不可判定。
但在实践中会发生什么?假设我们观察所有 s = 3, k = 2 机器在给定特定输入 1 时的行为。运行机器一百万步,我们推导出一个特定的运行时间分布:

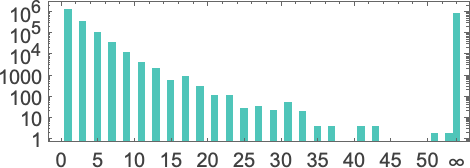
然后我们得出结论,略多于一半的机器会停机——最大的有限运行时间是相当温和的 53,由机器 630283(本质上等同于 718804)实现:
但这真的正确吗?或者有些我们认为在运行一百万步后不会停机的机器实际上最终会停机——但只是在更多步之后?
以下是发生情况的几个例子:
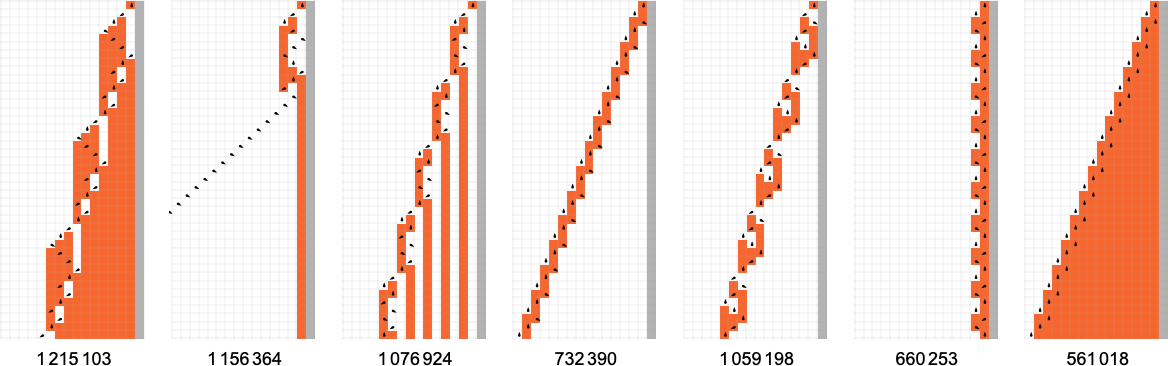
是的,在所有这些情况下,我们可以很容易地看到机器永远不会停机——相反,可能在经过一些瞬态后,其读写头只是永远基本周期性地移动。这是发现的周期分布:
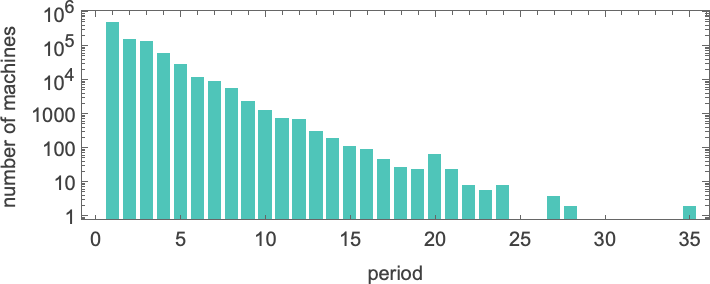
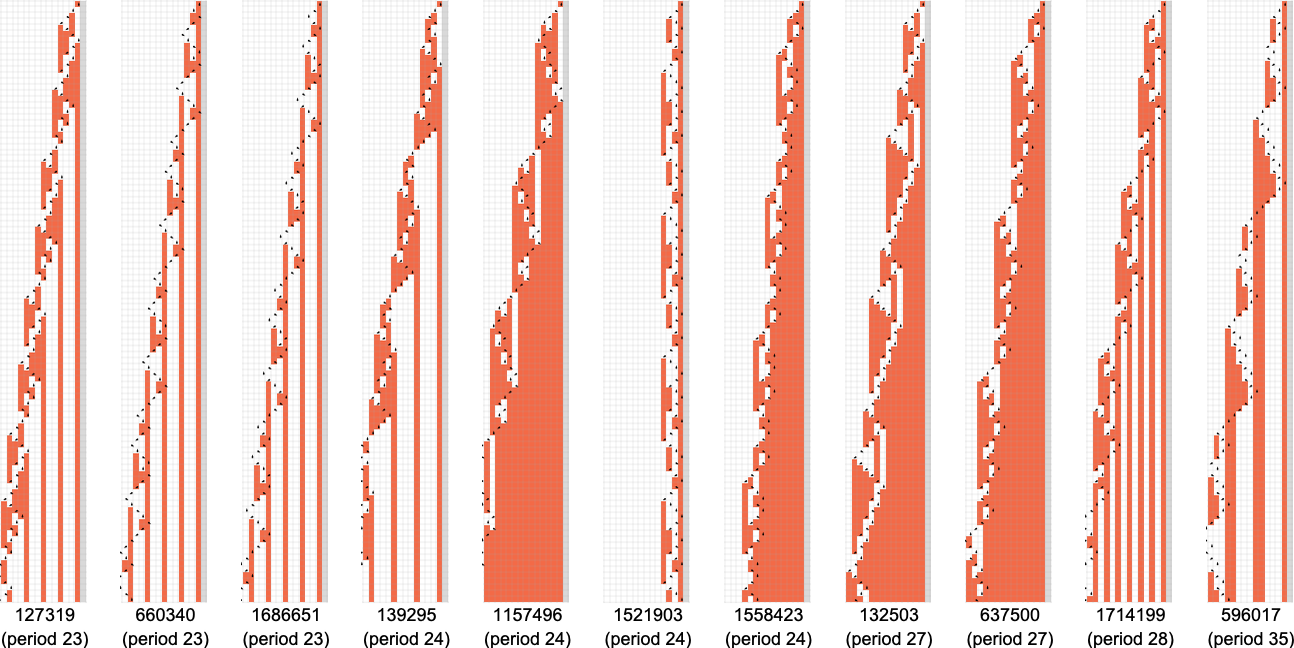
最长周期的情况是:
这是瞬态的分布:
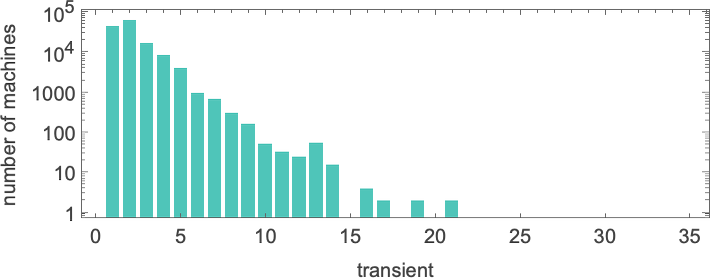
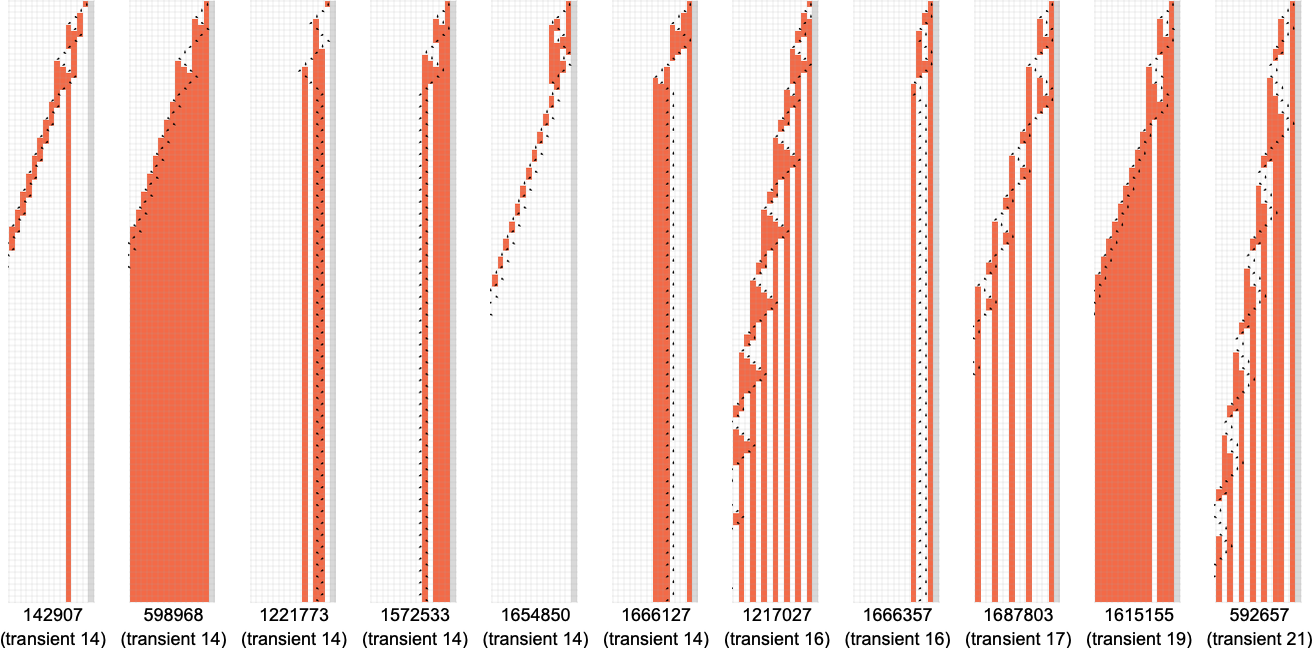
最长瞬态的情况是:
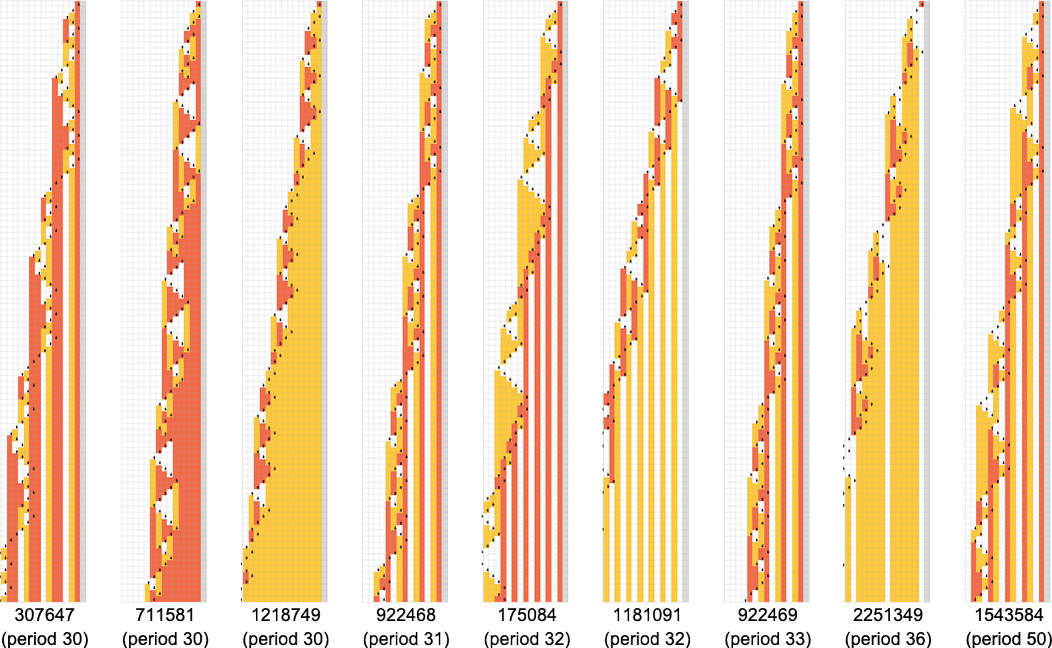
但这并不能完全解释所有在一百万步后没有停机的机器:还有 1938 台遗留。有 91 种不同的增长模式——这里是发生的样本:

所有这些最终都有一个基本的嵌套结构。模式以不同的速率增长——但总是以规则的连续步骤进行。有时这些步骤之间的间隔是多项式,有时是指数——意味着相应模式的分数幂或对数增长。但对于我们这里的目的来说,重点是我们有信心——至少对于输入 1——我们知道哪些 s = 3, k = 2 图灵机会停机,哪些不会。
但是如果我们增加提供的输入值会发生什么?以下是我们得到的前 20 个最大有限寿命:

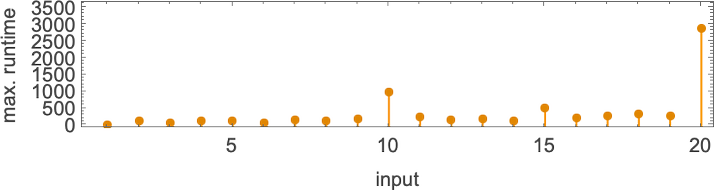
在输入 10 的“峰值情况”下,运行时间的分布是:
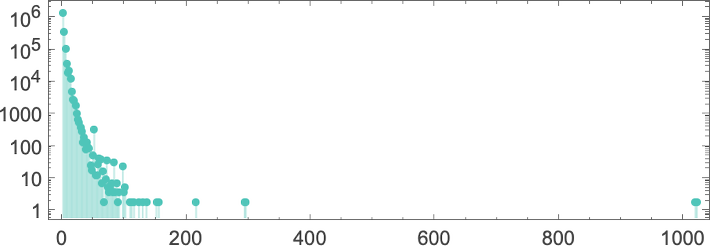
是的,最大值是一个有点奇怪的离群值。
那个离群值是什么?它是 机器 600720(以及相关的机器 670559)——我们将在下一节更深入地讨论它。但现在只需说,600720 作为一个具有最长运行时间的 s = 3, k = 2 机器反复出现。有运行时间更长的机器吗?很难绝对确定。但至少对于高达 的运行时间和高达 20 的输入,我们可以说绝对没有。根据我们看到的运行时间分布——以及与我们在更易于管理的 s = 2, k = 2 图灵机案例中看到的比较——似乎确实没有运行时间更长的机器,至少对于小输入是这样。
对于更大的输入呢?好吧,那时候事情变得更疯狂了。比如,考虑机器 1955095 的情况。对于所有高达 41 的输入,机器在适度的步数后停机:
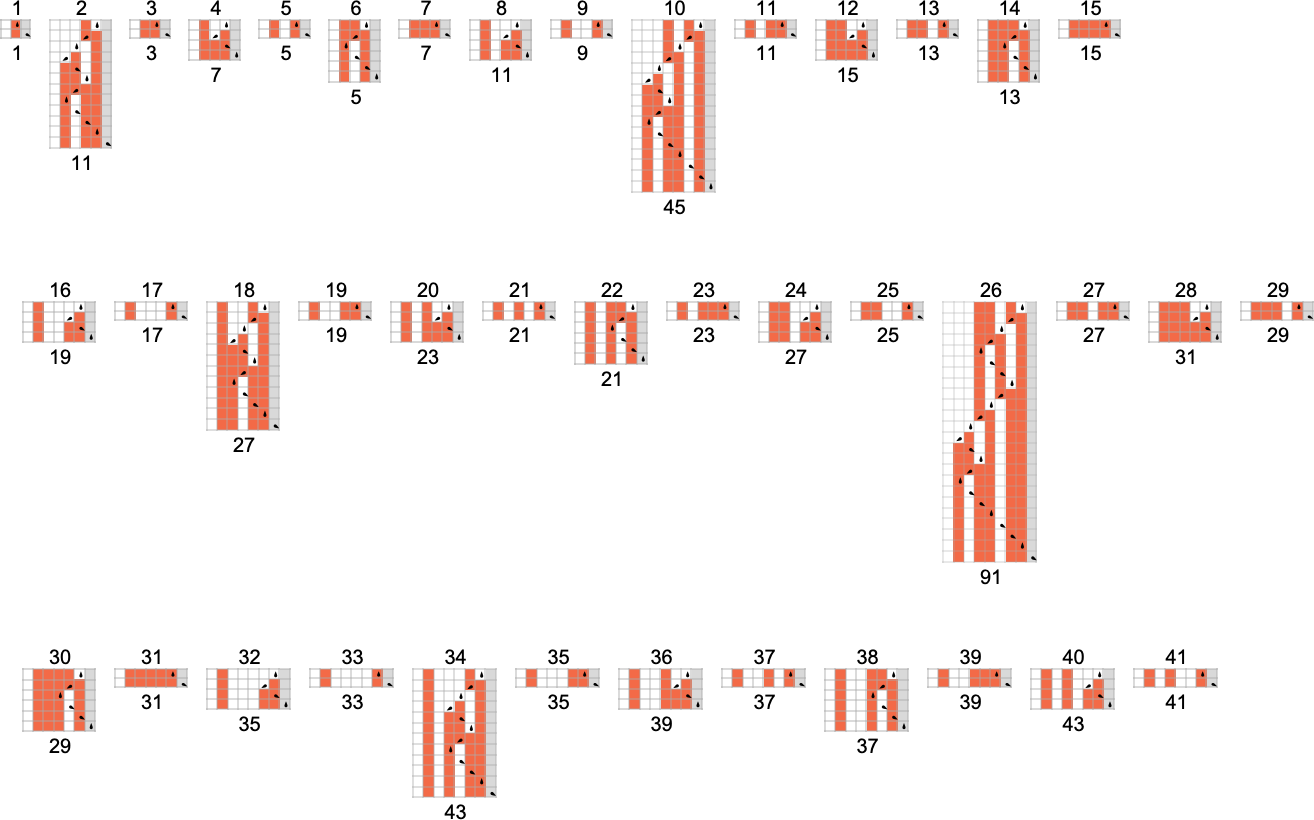
但是,在输入 42 时,突然出现了一个惊喜——机器从未停机:
是的,我们可以立即看出它从未停机,因为我们可以很容易地看到相同的增长模式周期性地重复——每 24 步。(一个更极端的例子是 s = 3, k = 2 机器 1227985,它对所有高达 150 的输入都停机——然后对输入 151 不停机。)
是的,像这样的事情是不可判定性的“长臂”伸进来了。但是通过连续调查更大的输入和更长的运行时间,人们可以建立合理的信心——至少在大多数时候——正在正确识别导致停机的情况和不导致停机的情况。由此可以估计,在所有 2,985,984 种可能的 s = 3, k = 2 图灵机中,总是停机的数量大约是 1,455,560。(这个结果的不确定性来自于有些机器可能仅在输入超过 200 万时才不停机,或者在较小输入上停机,但仅在超过 1 亿步之后。)
总结我们的结果,我们发现——有点令人惊讶的是——对于不同数量的状态,停机分数非常相似,总是接近 1/2:
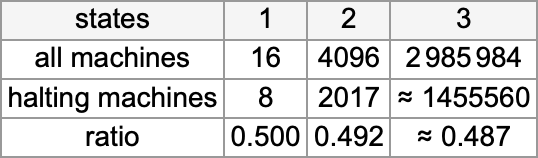
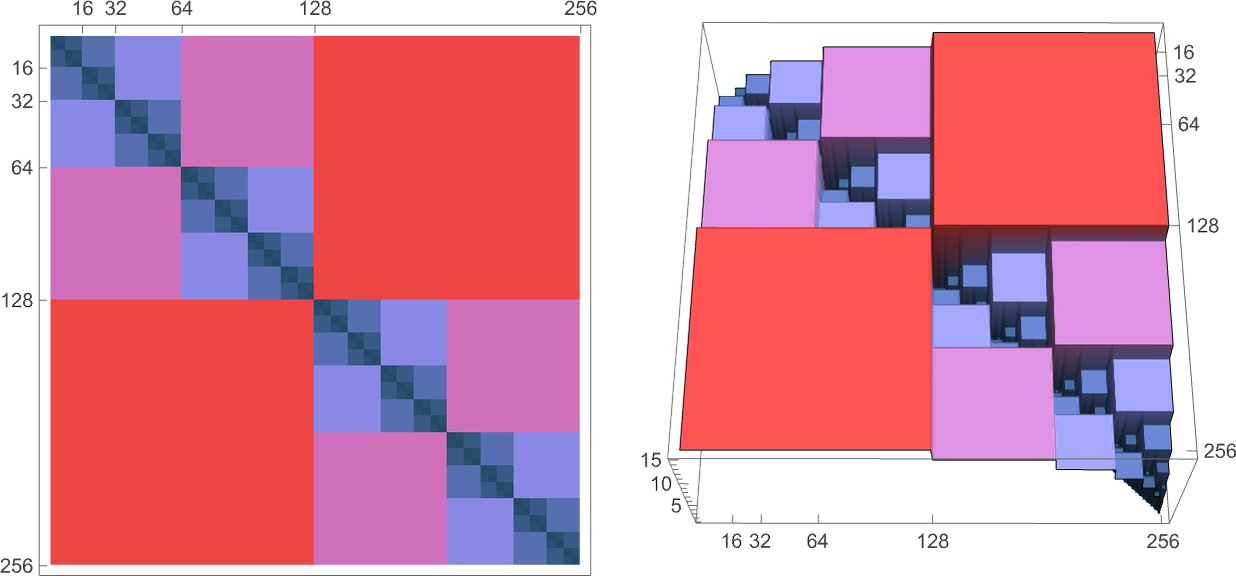
根据我们的停机机器普查,我们可以得出结论,由 s = 3, k = 2 图灵机计算的不同全函数的数量是 18,429:

机器 600720
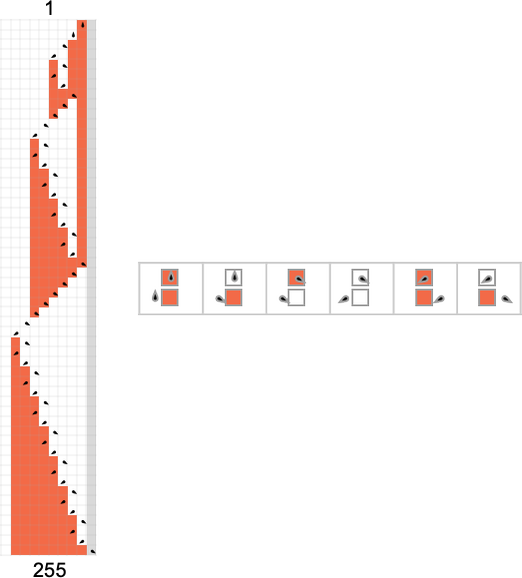
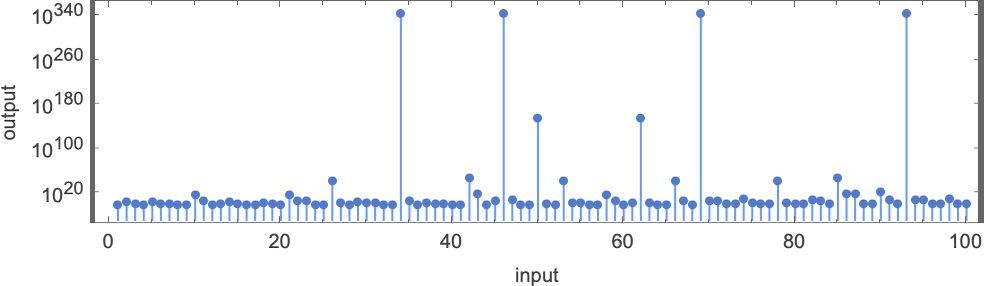
在观察 s = 3, k = 2 机器的运行时间时,我们注意到了一个离群值:一台可以给出异常长运行时间的机器。那台机器是 600720(以及相关的机器 670559):

我实际上是在 20 世纪 90 年代作为我关于 A New Kind of Science 工作的一部分第一次注意到这台机器的——并付出了巨大的努力,至少对其部分行为给出了相当详尽的分析:

关于这台机器,第一件引人注目的事情是它生成的输出值出现巨大的峰值:
伴随这些峰值的是相应的(稍微不那么剧烈的)运行时间峰值:
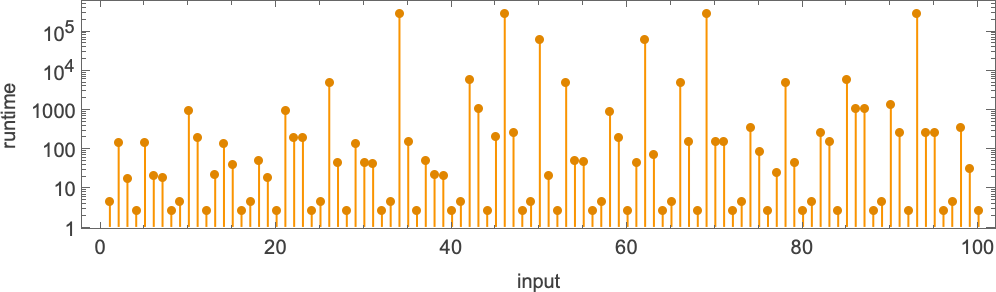
这里显示的第一个峰值出现在输入 i = 34——运行时间为 315,391,输出为 (或大约 )。当显示这些峰值时,图灵机在底下做什么?对于早期的峰值更容易看到(这里的后期图像已被压缩以使其行为更明显):
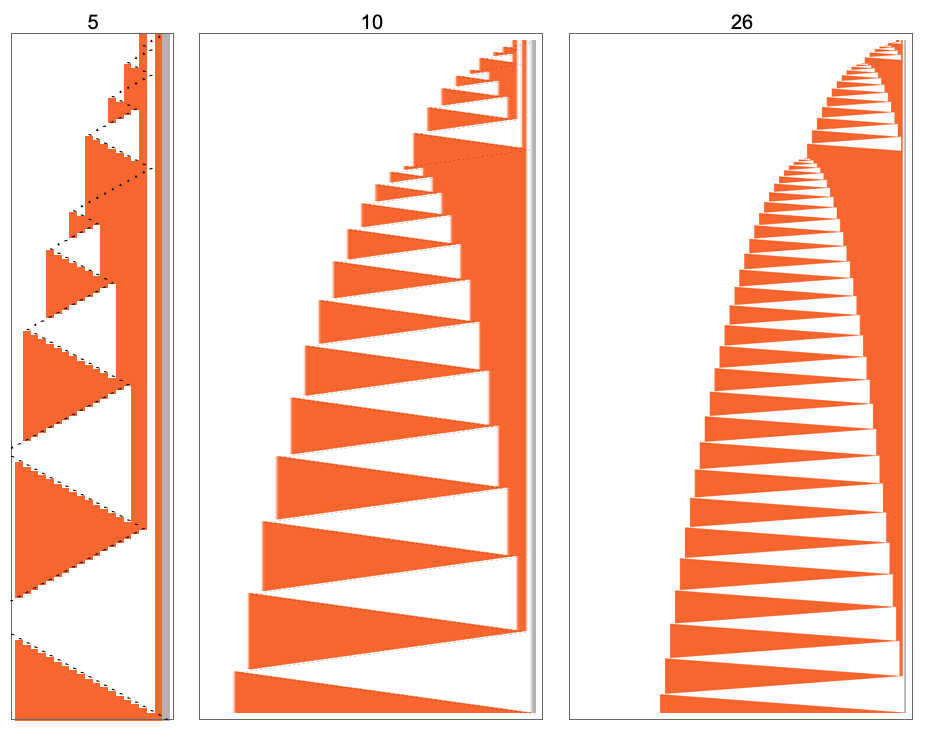
但基本的点是,机器似乎以一种非常“刻意”的方式行事,人们可能会想象这是可以分析的。
然而事实证明,分析出奇地复杂。这是一张最大(最坏情况)运行时间(以及相应的输入和输出)的表:

对于奇数 n > 3,最大运行时间发生在输入值 i 为:
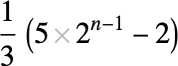
相应的图灵机初始状态形式为:
具有这种输入的输出值(对于奇数 n > 3)则是:
而运行时间——通过“数学化”图灵机对这些输入所做的事情得出的——由极其复杂的公式给出:
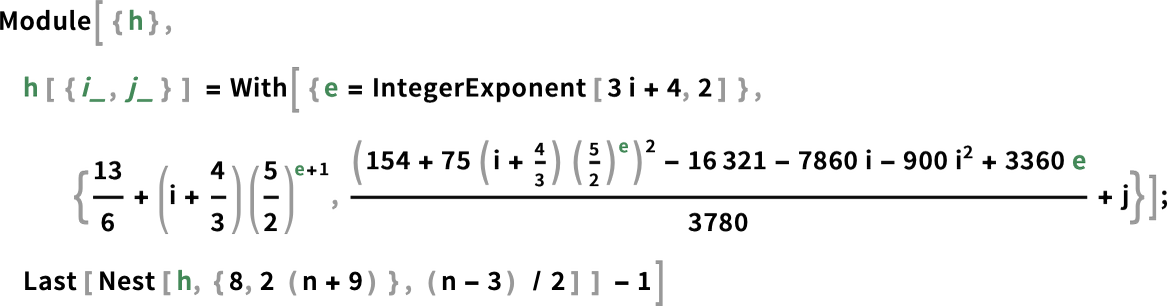
渐近行为是什么?它大约是 ,其中 随 n 变化如下:

所以这就是图灵机计算其输出可能需要多长时间。但是我们能更快地找到那个输出吗,比如说通过找到一个“数学公式”?对于某些特定形式的输入 i(比如上面的那个),确实可以找到这样的公式:
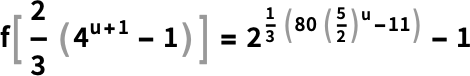
但在绝大多数情况下,似乎没有任何简单的数学式公式。实际上,我们可以预期这台图灵机是一个典型的计算不可约系统:你总是可以通过明确运行机器来找到它的输出(这里是值 f[i]),但是没有一般的方法可以捷径,并通过某种缩减的、更短的计算得到答案。
s = 3, k = 2 图灵机的运行时间
我们在上面讨论过,在 299 万种可能的 s = 3, k = 2 图灵机中,大约有 145 万种总是停机,从而对任何给定的输入产生确定的输出。但是它们的运行时间是多少,这些时间如何随着输入的大小而增加?就像我们对 s = 2, k = 2 机器所看到的那样,事实证明只有有限数量的不同的运行时间“概况”——这里大约有 7000 个。如果我们询问渐近行为,不同可能性的数量最多只有这个数字的一半。
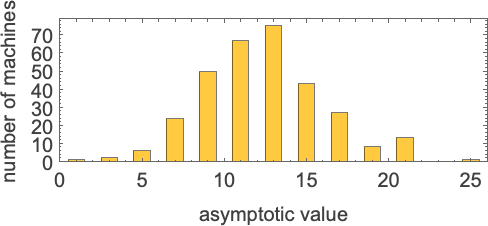
有些机器给出渐近常数的运行时间:

所有高达 21(以及 25)的奇数渐近运行时间值都是可能的:
然后有些机器给出渐近线性的运行时间,偶系数从 2 到 20(以及 24)——例如:

顺便说一句,请注意(正如我们之前提到的)有些机器对于许多特定输入实现了它们的最坏情况运行时间,而在其他机器中这种运行时间是罕见的(这里以渐近运行时间 24 n 的机器为例):

有时有些机器的最坏情况运行时间线性增加,但实际上具有分数斜率:

有许多机器的最坏情况运行时间以最终线性的方式增加——但带有“振荡”:

平均振荡给出了 形式的整体增长率,其中 是分母为 2 或 3 的整数或有理数; 的可能值为:

还有些机器的最坏情况运行时间增长如 ,其中 是从 1 到 10 的整数(虽然缺少 7):

然后有少数几台机器(如 129559 和 1166261)具有三次增长率。
下一组——实际上是单一最大的——机器的最坏情况运行时间渐近呈指数增长,遵循线性递推关系。可能的渐近增长率似乎是( 是黄金比例):
具有这些增长率的一些特定机器示例包括(我们将在下一节中看到 和 的例子):
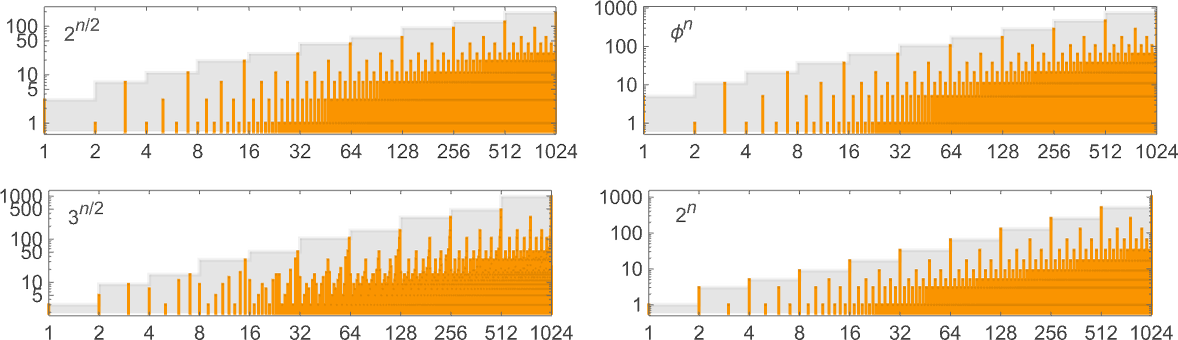
其中第一个是机器 1020827,对于输入大小 n 的确切最坏情况运行时间是:
显示的第二种情况(机器 117245)的确切最坏情况运行时间满足线性递推:
第三种情况(机器 1007039)的确切最坏情况运行时间:
值得注意的是,在所有这些情况下,输入大小 n 的最大运行时间发生在输入 时。以下是基础机器的实际行为(最终都证明只是计算恒等函数):
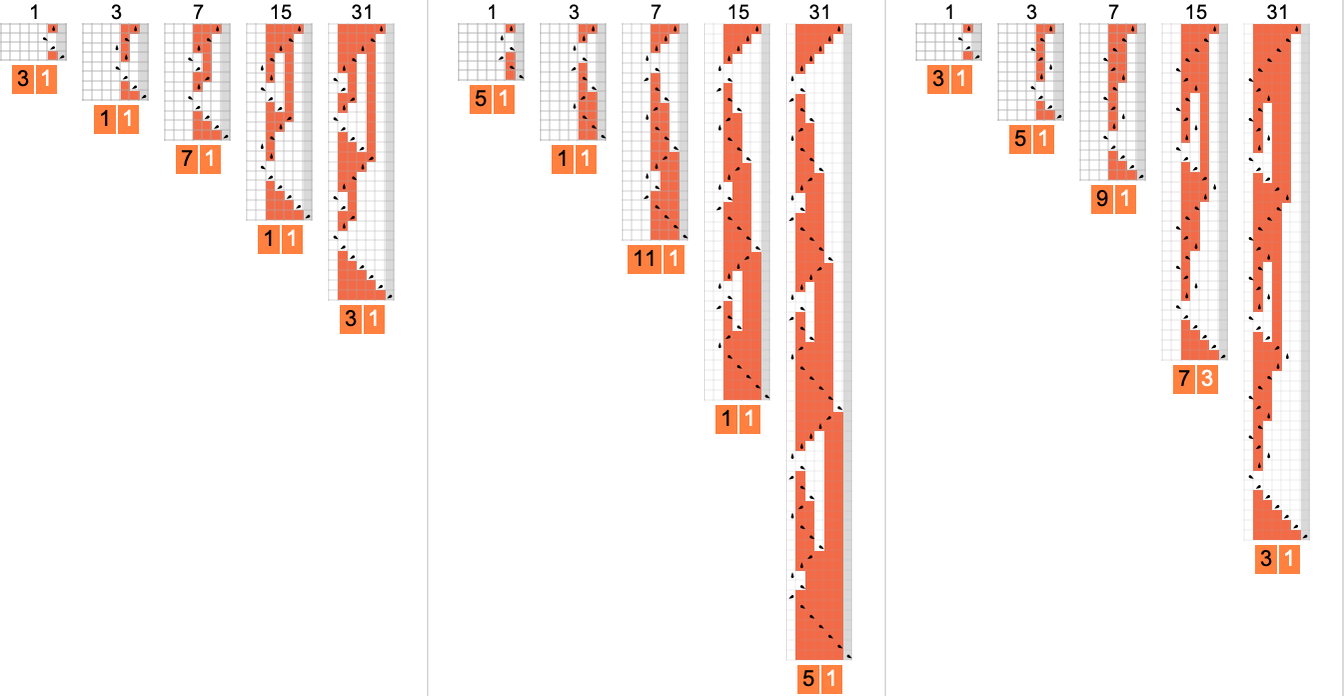
继续并压缩结果,很明显这些模式具有嵌套结构:

顺便说一句,最坏情况运行时间必须出现在给定大小的最大输入处并不是必然的。这里有一个例子(机器 888388),情况并非如此:
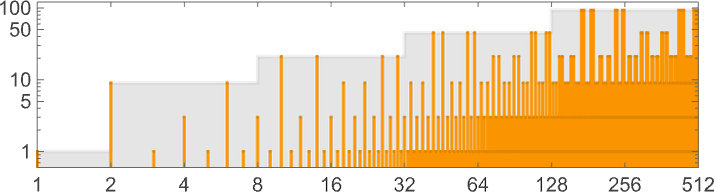
并且最终通过对所有偶数 n 的输入大小 n 和 n + 1 具有相同的最坏情况运行时间来实现 的增长:
我们在这里看到的所有内容的一个特点是,我们推导出的运行时间要么是渐近幂,要么是渐近指数。没有介于两者之间的——例如没有像 或 这样的东西:
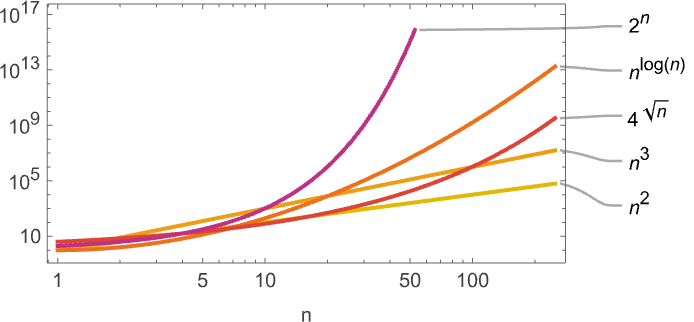
毫无疑问,存在具有这种中间增长的图灵机,但显然没有 s = 3, k = 2 的。
s = 3, k = 2 图灵机中的函数及其运行时间
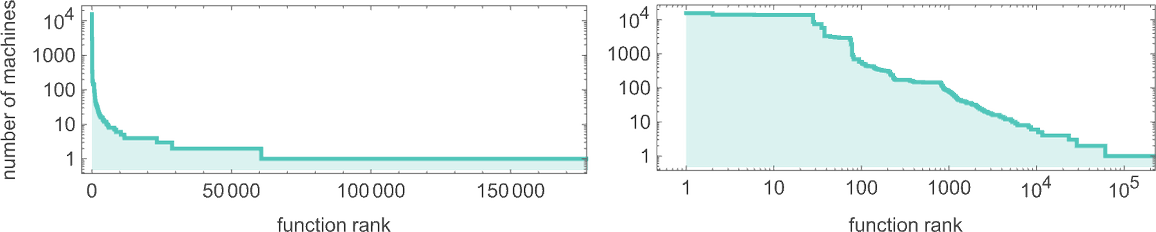
正如我们上面讨论的,在 299 万种可能的 s = 3, k = 2 图灵机中,大约有 145 万种总是停机,从而计算全函数。但这些函数是什么?一般来说,许多机器可以计算相同的函数。最终似乎大约有 18,000 个不同的函数可由 s = 3, k = 2 机器计算。按计算它们的机器数量对这些函数进行排名,我们得到以下分布:
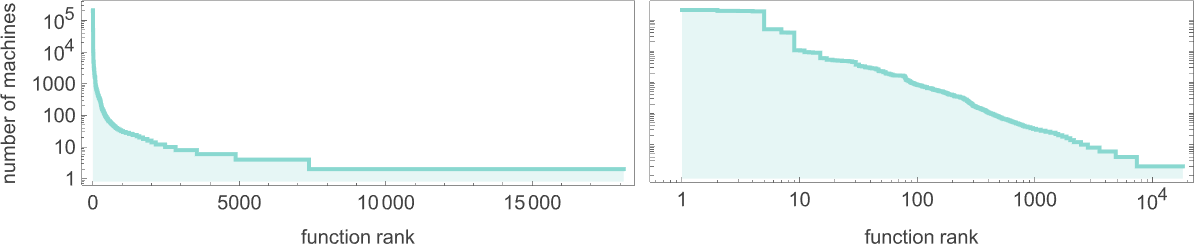
由最多机器计算的函数是(毫不奇怪,恒等函数 是总体赢家):
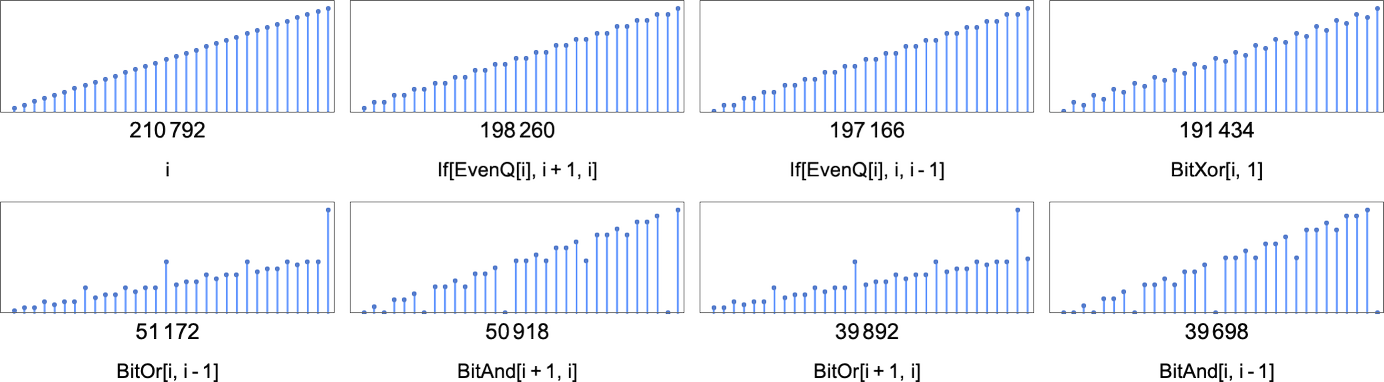
计算给定函数的最小机器数量总是 2——因为总是有一台带有 转换的机器,另一台带有 转换的机器,如下所示:
但是总共有大约 13,000 台这样的“孤立(isolate)”机器,没有其他 s = 3, k = 2 机器可以计算它们所做的相同函数。这些函数可以被认为代表了计算不可约的计算——至少对于 s = 3, k = 2 图灵机而言。
那么这些函数是什么——它们需要多长时间来计算?记住,这些是由孤立机器计算的函数——所以无论那些机器的运行时间是多少,这都可以被认为是计算该函数运行时间的下界,至少由任何 s = 3, k = 2 机器计算时。
那么由孤立机器计算的运行时间最长的函数是什么?总冠军似乎是我们上面讨论过的机器 600720 计算的函数。
接下来似乎是机器 589111:
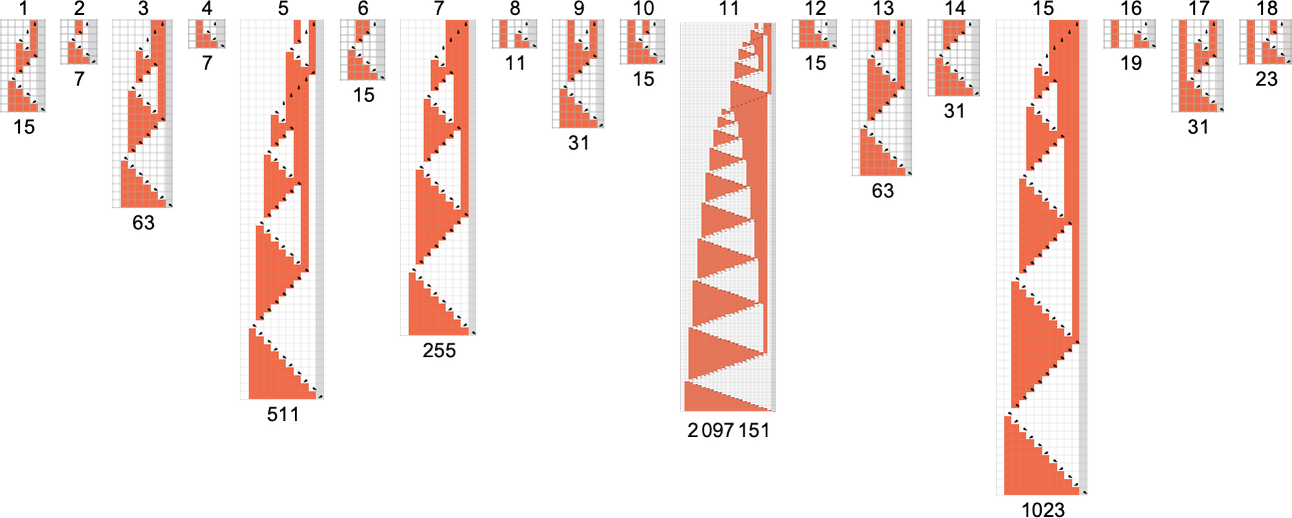
其渐近 运行时间:

尽管这里的值,比如对于 i = 95 和 i = 191,是巨大的( 和 ),但生成这些值的相应绝对下界分别仅为 377 和 761,这仍然显著小于这些情况下的实际运行时间:23,471 和 96,053。
接下来似乎是像 599063 这样的机器:
具有渐近 的运行时间:

尽管这个函数的值看起来有某种规则的模式,但计算它的机器是一个孤立机器,所以我们知道至少在 s = 3, k = 2 图灵机中,该函数不能计算得更快。
我们在上一节中看到的其他具有渐近指数运行时间的机器呢?好吧,我们在那里作为例子使用的特定机器甚至都不接近孤立。但是还有其他机器具有相同的指数增长运行时间,并且是孤立的。而且,就这一次,有一个惊喜。
对于渐近运行时间 ,事实证明只有一个孤立机器:1342057:

但看看这台机器计算的函数有多简单。实际上, 只是周期性的,以周期 16 重复块:
但尽管这很简单,图灵机仍然需要最坏情况运行时间 来计算它。“最困难”的输入形式为 ,这是机器在前几个这种情况下的表现:
是的,在开始的瞬态之后,机器最终所做的所有事情就是计算 。但重点是,如果观察机器计算的整个函数值序列,根本没有其他 s = 3, k = 2 图灵机可以进行该计算(好吧,除了直接等效的机器 2415947)。所以——尽管它很简单——我们必须得出结论,这个函数实际上对于 s = 3, k = 2 图灵机是不可约的,并且被迫具有渐近为 的最坏情况运行时间。
继续到 形式的渐近运行时间,事实证明只有一个函数有一台机器(1007039)具有这种渐近运行时间——而这个函数可以由一百多台机器计算,其中许多具有更快的运行时间,尽管有些具有更慢的 () 运行时间(例如 879123)。
关于 阶的渐近运行时间呢?这或多或少与 的故事相同。有 48 个函数可以由具有这种最坏情况运行时间的机器计算。但在所有情况下,也有许多其他机器,具有许多其他运行时间,计算相同的函数。
但现在还有另一个惊喜。对于渐近运行时间 ,有两个函数仅由孤立机器(889249 和 1073017)计算:


所以,再一次,这些函数的特征是它们不能被任何其他 s = 3, k = 2 图灵机计算得更快。
当我们查看 s = 2, k = 2 图灵机时,我们看到了一台机器——378——具有渐近最坏情况运行时间 。但与我们现在在 s = 3, k = 2 机器中看到的最大区别是,s = 2, k = 2 机器 378 不是一个孤立机器。恰巧,它计算的只是恒等函数 。虽然机器 378 花费指数时间来计算这个函数,但有许多其他 s = 2, k = 2 机器计算相同的函数要快得多,实际上是在常数时间内。
在 s = 2, k = 2 机器中,我们发现没有函数的最快运行时间随大小增长超过二次。但现在,对于 s = 3, k = 2 机器,有一些函数的最快运行时间不是多项式增长而是指数增长的例子。
当然,s = 3, k = 2 机器比 s = 2, k = 2 机器多得多。但可能即使有了所有这些机器,也会有足够多的机器,使得其中至少有一台能快速计算任何给定的函数。然而,实际上我们看到的是,不同函数的数量足够大,以至于最终有许多“孤立”机器是唯一(至少在 s = 3, k = 2 中)计算给定函数的机器。当这些机器具有渐近指数运行时间时,它们实际上为它们计算的函数的运行时间定义了一个(指数)下界(在 s = 3, k = 2 机器中)。
孤立机器立即定义了它们计算的函数的运行时间下界。但一般来说(如我们上面所见),可能有许多机器计算给定的函数。例如,如上所述,有 210,792 台 s = 3, k = 2 机器计算恒等函数。这些机器有 102 个不同的运行时间概况:

渐近运行时间范围从常数到线性、二次和指数。(增长最快的运行时间是 。)
对于每个可以计算的函数,都有一个略微不同的运行时间概况集合;这是由次多数量的机器计算的函数的运行时间概况:
更大的机器能计算得更快吗?
我们在上面看到,有些函数不能被例如任何 s = 2, k = 2 图灵机以渐近快于特定界限的速度计算。但是如果我们考虑更大的图灵机(比如 s = 3, k = 2)呢?会有更大的图灵机能更快地计算给定的函数吗?
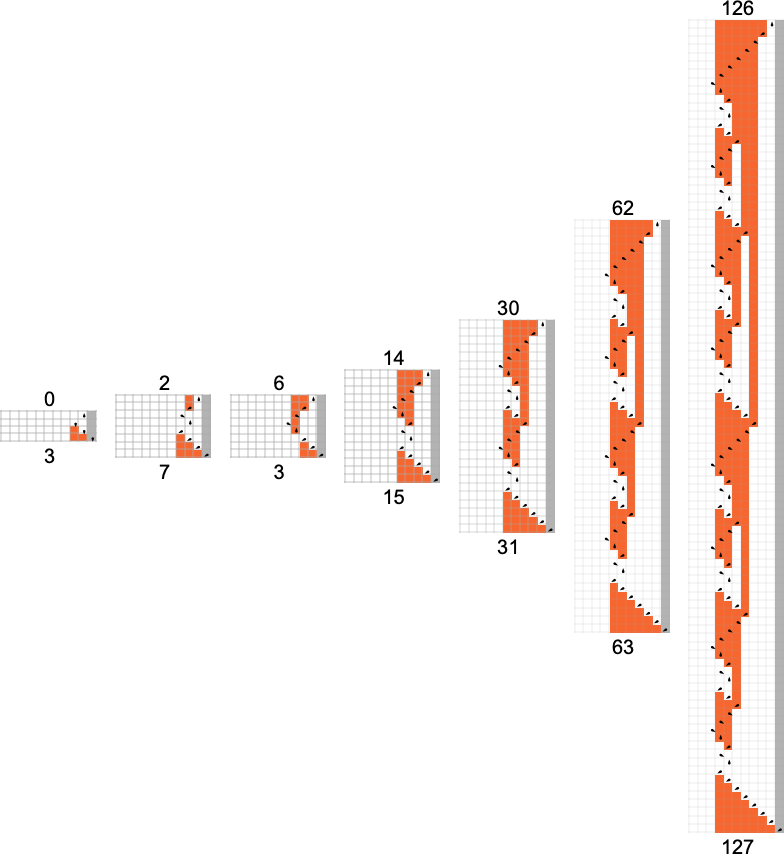
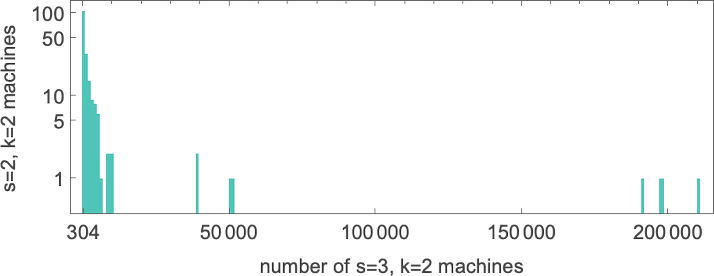
首先要说的是(正如我们之前讨论过的 s = 2, k = 2 vs. s = 1, k = 2 机器),如果某种大小的图灵机(比如 s = 2, k = 2)计算一个给定的函数,那么总是必须有更大的图灵机(比如 s = 3, k = 2)计算相同的函数。确实,通常有许多这样的机器。例如,在 s = 3, k = 2 机器中,这是计算 s = 2, k = 2 机器计算的每个函数的机器数量分布(最小值为 304,是针对由 s = 2, k = 2 机器 2439 计算的函数):
在 s = 2, k = 2 机器中,我们发现有些函数不能被任何此类机器以渐近快于二次的速度计算。一个例子是机器 1511 计算的函数:

其中确切的最坏情况运行时间是:
但现在我们可以问这个函数是否可以被任何 s = 3, k = 2 机器更快地计算。事实证明,有 352 台这样的机器计算这个函数。其中,342 台具有完全相同的最坏情况运行时间,并且没有机器以渐近快于二次的速度计算该函数。尽管如此,还是有 10 台机器设法稍微快一点地计算该函数,运行时间为:
一个例子是机器 1069163:
我们可以认为发生的事情是,我们从 s = 2, k = 2 图灵机规则开始:
实际上通过使用稍微复杂一点的“指令集”来优化它:

在观察 s = 3, k = 2 图灵机时,我们发现了只能通过运行时间随输入大小渐近指数增加的机器计算的函数示例。所以现在我们可以问,通过使用 s = 4, k = 2 图灵机,是否可能更快地计算这些函数。
作为一个例子,考虑由孤立机器 1342057 计算的函数:

这具有渐近运行时间 。但现在如果我们看看 s = 4, k = 2 机器,那么在 台这样的机器中,人们发现 2220 台计算这个函数。其中,1583 台具有与原始 s = 3, k = 2 机器完全相同的最坏情况运行时间。许多其他机器也有渐近指数运行时间。但事实证明,还有其他机器具有快得多的运行时间。例如,机器 1517414255 渐近具有仅为 7 的常数最坏情况运行时间:

还有运行时间呈线性和二次增加的机器——尽管令人困惑的是,对于前几个输入大小,它们的增加速度似乎与我们的原始 s = 3, k = 2 机器一样快:

这是这些特定图灵机的基础规则:
这是 s = 4, k = 2 机器为我们的函数实现的完整运行时间概况谱:

有些运行时间很容易识别为指数——尽管底数像 这样,小于 4。然后有我们刚刚看到的线性和多项式运行时间。还有一些稍微奇特的“振荡”行为,就像机器 1418699063 一样:
它似乎稳定在比率的周期性序列,渐近增长如 。
其他很难用 s = 3, k = 2 机器计算的函数呢?这通常证明是一个稍微不同的故事。例如,对于由 s = 3, k = 2 机器 600720 计算的函数,有 1602 台 s = 4, k = 2 机器也计算它。但与我们刚刚看到的情况不同,没有一整套运行时间概况:相反,只有两个:

其中之一完全遵循 600720 的运行时间;另一个不相同,但非常接近,大约一半的运行时间相同,另一半的最大差异随 n 线性增长。
这意味着——不像 s = 3, k = 2 机器 1342057 计算的函数那样——由 s = 3, k = 2 机器 600720 计算的函数不能被任何 s = 4, k = 2 机器比 s = 3, k = 2 机器计算得更快。换句话说,使用更大的机器(至少 s = 4)对该函数的计算没有帮助。
查看其他用 s = 3, k = 2 机器“难计算”的函数,人们有时会发现如果使用 s = 4, k = 2 机器,它们变得更容易计算,但通常并非如此。
有了足够大的图灵机……
到目前为止,我们一直在讨论非常小的图灵机——在其规则中最多只有少数几个不同的情况。但是如果我们考虑大得多的图灵机呢?这些能让我们系统地更快地进行计算吗?
给定从输入到输出值的特定(有限)映射,例如:

构建一个图灵机是非常直接的:

其状态转换实际上只是“立即查找”这些值:
(如果我们试图计算一个尚未定义的值,图灵机根本不会停机。)
如果我们保持固定的 k 值,那么对于大小为 v 的“函数查找表”,我们需要用于“直接表示”查找表的状态数与 v 直接成正比。同时,运行时间仅等于我们上面讨论的绝对下界,它与输入和输出的大小线性成正比。
当然,按照这种设置,随着我们增加 v,我们也增加了图灵机的大小。而且我们无法保证用任何小于无限图灵机的东西来编码定义为例如所有整数的函数。
但是当我们处理无限图灵机时,我们并不真的需要计算任何东西;我们可以只是查找一切。实际上,计算理论总是假设我们限制了机器的大小。一旦我们这样做,就会开始出现关于哪些函数是可计算的,以及计算它们需要多少运行时间等各种丰富的问题。
在过去,我们可能只是假设对图灵机的大小有一些任意的界限,或者实际上是对它们的“算法信息内容”或“程序大小”的界限。但我们在这里所做的重点是探索不是用任意界限,而是用小到足以让我们进行穷尽性经验调查的界限时会发生什么。
换句话说,我们将自己限制在低算法(或程序)复杂性中,并询问随之而来的时间复杂性、空间复杂性等会发生什么。我们发现,即使在该领域,我们能看到的行为也有着显著的丰富性。从计算等价性原理,我们可以预期这种丰富性已经是我们在更大的图灵机甚至更大的算法复杂性中会看到的特征。
超越二进制图灵机
在目前为止我们所做的一切中,我们一直在观察“二进制”(即 k = 2)图灵机,其纸带上只有值 0 和 1。但是如果我们考虑更多可能的值——比如“三进制”(即 k = 3)图灵机,纸带上有值 0、1 和 2 呢?
我们一直使用的设定可以立即转换:

最简单的情况是 s = 1, k = 3——产生 种可能的机器:
在这些机器中,88 台总是停机——并计算 77 个不同的函数。可能的运行时间是:

而且不同于我们在 s = 2, k = 2 中看到的,现在有了“孤立”机器,其最坏情况运行时间呈二次增长——最大运行时间由机器 29 实现:

对于 s = 2, k = 3,我们有 种可能的机器——与 s = 3, k = 2 的数量相同。实际上我们看到的行为与我们在 s = 3, k = 2 中看到的相似。对于输入 1,在这两种情况下停机步骤为 1 和 3 的机器数量实际上是相同的(分别为 1492992 和 373248)。曾经停机的机器比例相似,但不完全相同:s = 3, k = 2 为 68.2%,s = 2, k = 3 为 67.6%。对于输入 1 的最长“有限寿命”,s = 3, k = 2 为 53,s = 2, k = 3 为 83:
在这两种情况下,对于不停机的机器,绝大多数变为周期性。对于 s = 3, k = 2,最大周期(从输入 1 开始)是 35;对于 s = 2, k = 3,它是 50:
就像 s = 3, k = 2 一样,有些 s = 2, k = 3 机器不会变为周期性,尽管(至少对于输入 1)所有都产生嵌套模式,例如:

或压缩形式:

如果我们观察除输入 1 以外的情况,我们发现大约 112 万台 s = 2, k = 3 机器总是停机(相比之下 s = 3, k = 2 为 145 万台)。但是如果我们问这些机器计算了多少个不同的函数,结果大约是 173,000——几乎是 s = 3, k = 2 机器的十倍。为什么会这样?这显示了计算给定函数的 s = 2, k = 3 机器数量的分布:
一个显著的特点是尾部由仅由一台机器计算的函数组成。在 s = 2, k = 3 的情况下, 和 转换之间的对称性意味着总是至少有两台机器计算给定的函数。但是对于 s = 2, k = 3,这种“简并性”被打破,导致不同函数的数量更多。
关于运行时间?s = 2, k = 3 的结果似乎与 s = 3, k = 2 大致相似,尽管有点更狂野。增长最快的运行时间似乎渐近增长如 ,一个例子是机器 840971,其连续输入大小的最坏情况运行时间是:
在某种意义上,s = 3, k = 2 图灵机和 s = 2, k = 3 图灵机的行为之间有如此多的相似之处并不令人惊讶。毕竟,每种可能的机器总数是相同的,其规则中的基础情况数量也是相同的。
然而,如果我们观察的不是我们这里考虑的那种“单向”(或“如果向右移动则停机”)图灵机,而是读写头可以向任一方向自由移动的图灵机,那么就会出现一个差异。从空白纸带开始,所有 s = 3, k = 2 机器最终都以容易预测的方式行事。但是——正如我在 A New Kind of Science 中发现的那样——s = 2, k = 3 机器 596440 并非如此:
这一事实提供了一个线索,即这样的机器(或者实际上是作为该示例的 14 台基本等效机器)可能能够进行通用计算。实际上已经证明——至少在适当的(无限)初始条件下,该机器可以成功地“编程”以模拟已知为通用的系统,从而证明其本身是通用的。
这台机器在我们单向设置下的表现如何?这是它对前几个输入的处理:

我们发现对于任何输入,机器的读写头最终都会向右移动,所以在我们的单向设置中我们认为机器停机:

事实证明,大小为 n 的输入的最坏情况运行时间增长根据:
但是如果我们查看这台机器计算的函数,我们可以问是否有更快的方法来计算它。事实证明还有 11 台其他 s = 2, k = 3 机器(尽管例如没有 s = 3, k = 2 机器)计算完全相同的函数。如果我们从空白纸带观察它们的行为:

人们可能会认为它们足够简单以至于运行时间更短。但实际上在单向设置中,它们的行为基本上与我们的原始机器相同。
好的,但是 s = 3, k = 2 机器呢?可能它们更高的对称性使得如果从空白纸带开始,它们不会“显露其计算能力”。但是可以预期,有了更复杂的初始条件,它们可能会做更复杂的事情。尽管如此,至少对于“输入 1”(即在其他空白的纸带上的单个 1),有像这样的嵌套行为,但没有更多:

可识别的函数
我们一直在讨论图灵机计算函数能有多快。但是关于它们计算什么函数,我们可以说些什么呢?通过适当的输入编码和输出解码,我们知道(本质上根据定义)任何可计算函数都可以由某个图灵机计算。但是我们这里一直在使用的简单图灵机呢?以及关于“没有编码”的情况呢?
按照我们的设定方式,我们将图灵机纸带上的值序列既作为输入也作为输出——并将这些值解释为整数的数字。所以这意味着我们可以将图灵机视为定义从整数到整数的函数。但它们是什么函数?
这是两台 s = 2, k = 2 图灵机,它们计算函数 ——完成了适当的长程进位,比如对于输入 7:
总共有 17 台 s = 2, k = 2 机器进行此计算。(没有 s = 1, k = 2 机器,有 8934 台 s = 3, k = 2 机器。)没有 s = 2, k = 2 机器计算 (其中 )——但有 14 台 s = 3, k = 2 机器计算 ,例如:
尽管如此,对于 ,再次没有 s = 3, k = 2 机器计算 。
如果我们限制自己只输入偶数,那么我们甚至可以用 s = 2, k = 2 机器计算 :

类似地,有 s = 3, k = 2 机器对于偶数输入计算 ,直到 :
其他“数学上简单”的函数呢,比如 或 ?至少直到 s = 4, k = 2,没有机器计算这些特定函数。一般来说,在数学上简单的东西和在图灵机中简单的东西之间似乎存在某种脱节。这有点像数学运算和数字序列发生的情况:除了极少数情况外,简单的数学运算不会导致数字序列中的简单模式。
我们已经看到了各种例子,其中我们的图灵机可以被解释为评估其输入的位运算函数。一个更微小的情况是像单个位翻转这样的事情——确实有一台 s = 2, k = 2 机器可以计算其纸带上“最后一位”的翻转:

为了能够翻转更高位的数字,需要一台状态更多的图灵机。有两台 s = 3, k = 2 机器翻转倒数第二位数字:

一般来说——正如这些图片所暗示的——翻转第 m 位可以用读写头至少有 m + 1 种可能状态的图灵机来完成。
计算周期函数的图灵机呢?严格(非平凡)的周期性似乎很难实现。但这里有一个 s = 2, k = 2 机器(实际上是唯一的一个),它计算 :

对于 s = 2, k = 2 和 s = 3, k = 2,都没有计算 的机器。但对于 s = 3, k = 2,有 4 台机器计算 :

人们可能问的另一件事是一台图灵机是否可以模拟另一台。确实,这就是我们看到的——非常直接——每当一台图灵机计算与另一台相同的函数时。
(我们也知道存在通用图灵机——最简单的具有 s = 2, k = 3——最终可以模拟任何其他图灵机。但一般来说,这种模拟不会像我们这里研究的那样直接;相反,它将涉及输入和输出的潜在非常复杂的编码。)
经验性的计算不可约性
在过去的四十多年里,计算不可约性一直是我所做的大部分科学的核心。确实,它指导了我们在本文探索的大部分内容的直觉。但我们现在讨论的事情也让我们能够对计算不可约性这一核心现象本身进行经验性的审视。
计算不可约性归根结底是关于这样一个观点:可能存在这样的计算,实际上没有捷径:除了运行其每一个步骤之外,没有办法系统地找到它们的结果。换句话说,给定一个不可约的计算,基本上没有办法想出另一个计算能给出相同的结果,但步骤更少。不用说,如果想要收紧这个直观的想法,有很多详细的问题需要考虑。例如,只使用具有“更大原语”的计算系统怎么样?像理论科学中的许多其他基础概念一样,很难确切地确定应该如何设置事物——以便人们既不会隐含地假设试图解释的东西,也不会过度限制事物以至于一切都变得本质上微不足道。
但是利用我们在这里所做的,我们可以以一种非常明确的方式探索一种确定性的——如果受限的——计算不可约性版本。想象我们正在使用图灵机计算一个函数。说该函数——以及计算它的图灵机的潜在行为——是计算不可约的意味着什么?本质上就是没有其他更快的方法来计算该函数。
但是如果我们限制自己使用特定大小的图灵机进行计算,这正是我们在本文中详细研究的内容。而且,例如,每当我们拥有所谓的“孤立”图灵机时,我们知道没有其他相同大小的图灵机可以计算相同的函数。所以这意味着我们可以说该函数相对于给定大小的图灵机是计算不可约的。
这种概念有多稳健?我们在上面看到了例子,其中给定的函数可能只能由 s = 3, k = 2 图灵机以指数时间计算,但可以由 s = 4, k = 2 图灵机以线性时间计算。但期望是随着我们增加机器的大小——从而增加可能机器的数量——最终会有越来越多的函数,拥有更大的机器也无法实现显著的加速。这样的函数我们就可以认为实际上是“绝对计算不可约的”。
但这里的重点是,仅仅通过明确观察给定大小的图灵机,我们就已经可以看到计算不可约性的一个受限版本。这使我们能够获得关于计算不可约性的具体结果,或者至少是关于这个受限版本的结果。
多年来在观察各种系统时的一个显著发现就是计算不可约性现象似乎是多么普遍。但通常我们没有办法严格地说我们在任何特定情况下看到了计算不可约性。我们通常只知道我们无法“视觉解码”正在发生的事情,我们也尝试过的方法也无法做到。(是的,各种不同的方法几乎总是同意什么是“可压缩的”什么不是,这一事实鼓励了我们关于存在计算不可约性的结论。)
在观察这里的图灵机时,我们经常看到“视觉复杂性”,与其说是在具有特定初始条件的详细——通常是沉闷的——行为中,不如说是在我们通过绘制函数值与输入的关系图所得到的结果中。但现在我们有了一个更严格的——尽管受限的——计算不可约性测试:我们可以问正在计算的函数相对于这种大小的图灵机是否是不可约的,或者,通常等效地,我们正在观察的图灵机是否是一个孤立机器。
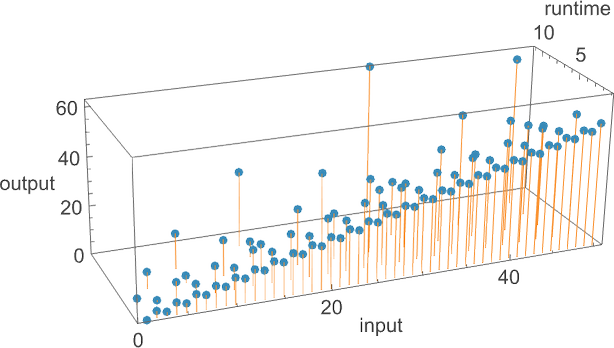
所以现在我们可以,例如,探索以这种方式定义的不可约性可能有多普遍。这是我们在上面研究的一些小图灵机类别的结果:

我们要看到的是——就像我们从细胞自动机等计算系统得到的印象一样——计算不可约性在小图灵机中确实非常普遍,现在我们使用的是我们严格的、如果受限的计算不可约性概念。
(值得评论的是,虽然图灵机的“全局”特征——如它们计算的函数——可能是计算不可约的,但在它们更详细的属性中仍然可能有大量的计算可约性。事实上,我们在这里看到的是,图灵机的行为有大量特征——如读写头的来回运动——看起来视觉上很简单,我们可以期望以比仅仅运行图灵机本身快得多的方式进行计算。)
非确定性(多路)图灵机
到目前为止,我们已经对普通的、确定性的(“单路”)图灵机进行了相当广泛的研究。但是 P vs. NP 问题是关于比较这种确定性图灵机的能力与非确定性——或多路(multiway)——图灵机的能力。
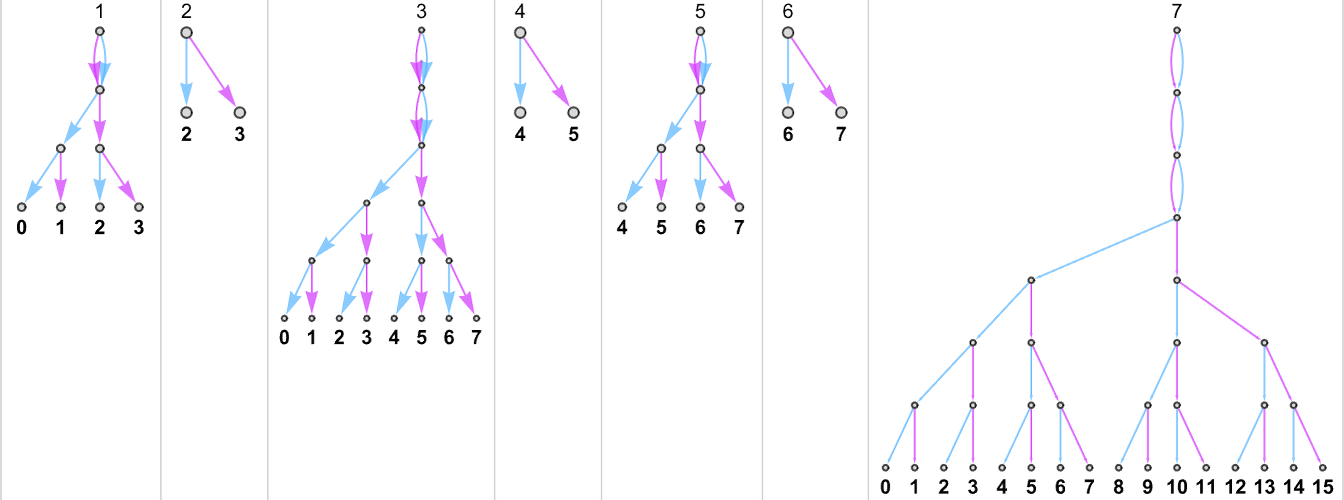
普通的(确定性)图灵机有一个规则,例如:
这指定了图灵机连续配置的唯一序列:
我们可以将其表示为:
另一方面,多路图灵机可以有多个规则,例如:
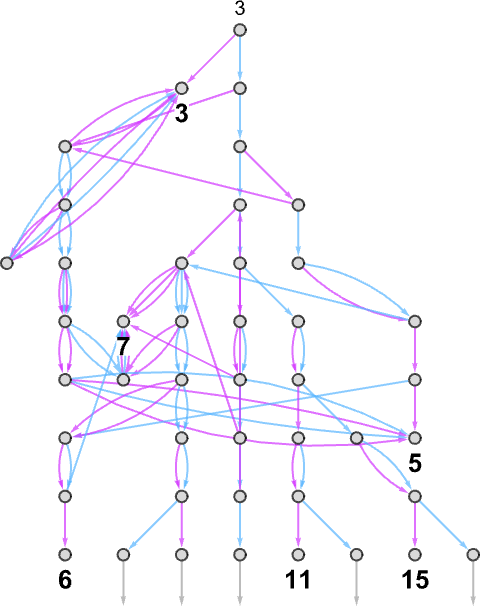
这些规则以所有可能的方式应用,生成图灵机连续配置的整个多路图(multiway graph):
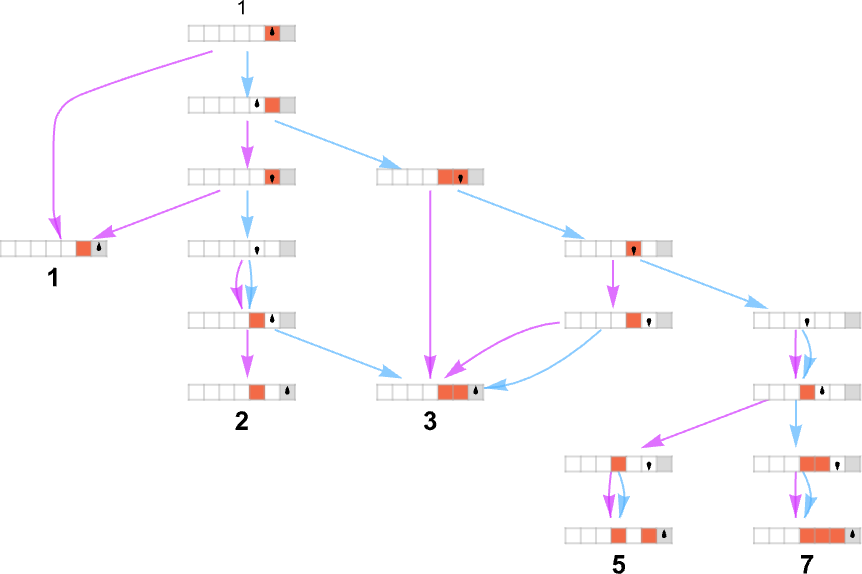
这里我们分别用蓝色和橙色指示与每个规则应用相关联的多路图中的边,并且合并了相同的图灵机配置。
正如我们对普通(确定性)图灵机所做的那样,我们认为多路图灵机在读写头移动到比起始位置更右侧时达到停机配置——虽然现在这可能发生在多个分支上——所以图灵机实际上可以生成多个输出。
按照我们设置的方式,我们可以将普通(确定性)图灵机视为接受输入 i 并给出某个值 f[i] 作为输出(如果图灵机对于给定的 i 不停机,该值可能未定义)。作为直接类比,我们可以将多路图灵机视为接受输入 i 并可能给出整个相应的输出集合:
直接的复杂情况之一是机器可能不会停机,至少在某些分支上——就像这里的输入 3,在上面的图中用红点表示:
(此外,我们看到可能有通过多条路径到达给定输出的情况,实际上为该输出定义了多个运行时间。也可能有循环,但在定义“运行时间”时我们忽略这些。)
当我们构建多路图时,我们实际上是在为(多路)系统演化中的所有可能路径建立表示。但是当我们谈论非确定性演化时,我们通常想象只会遵循一条路径,只是我们不知道是哪一条。
假设我们有一台多路图灵机,对于每个给定的输入生成一组特定的输出。如果我们从这些集合中只选择一个输出,我们实际上在每种情况下都是在多路图灵机中选择一条路径。或者,换句话说,我们将“进行非确定性计算”,或者实际上从非确定性图灵机获得输出。
作为一个例子,让我们采用上面的多路图灵机。这是一个例子,说明这台机器——被视为非确定性图灵机——如何生成特定的输出值序列:
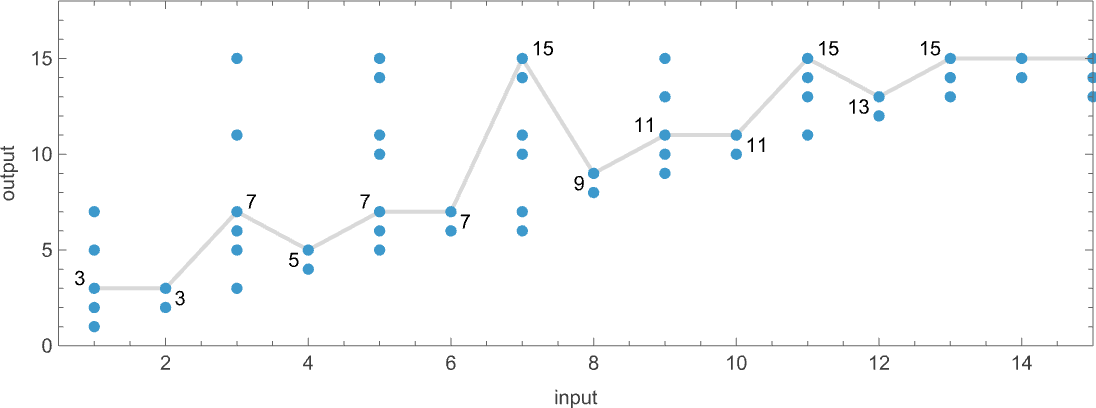
这些输出值中的每一个都是通过遵循每个输入获得的多路图中的某条路径来实现的:
仅保留所走的路径(并包括底层的图灵机配置),这表示每个输出值是如何被“推导”出来的:
路径的长度可以被认为是到达输出值所需的非确定性图灵机的运行时间。(当有多条路径到达给定输出值时,我们通常将“运行时间”视为这些路径中最短的一条的长度。)所以现在我们可以总结我们示例中的运行时间如下:
P vs. NP 问题的核心是比较确定性和非确定性图灵机获得特定函数的运行时间。
因此,例如,给定一台计算特定函数的确定性图灵机,我们可以问是否有一台非确定性图灵机——如果你选择了正确的分支——可以计算相同的函数,但速度更快。
在上面的例子中,有两个可能的底层图灵机规则,分别用蓝色和橙色表示。对于每个输入,我们可以在每一步选择不同的规则来应用,以便到达输出:
在不同步骤使用不同规则的可能性实际上允许我们在如何完成计算方面有更多的自由。P vs. NP 问题关注的是这种自由是否允许我们从根本上加速给定函数的计算。
但在我们进一步探索这个问题之前,让我们看看多路(非确定性)图灵机通常做什么;换句话说,让我们研究它们的规则学。
多路(非确定性)s = 1, k = 2 图灵机
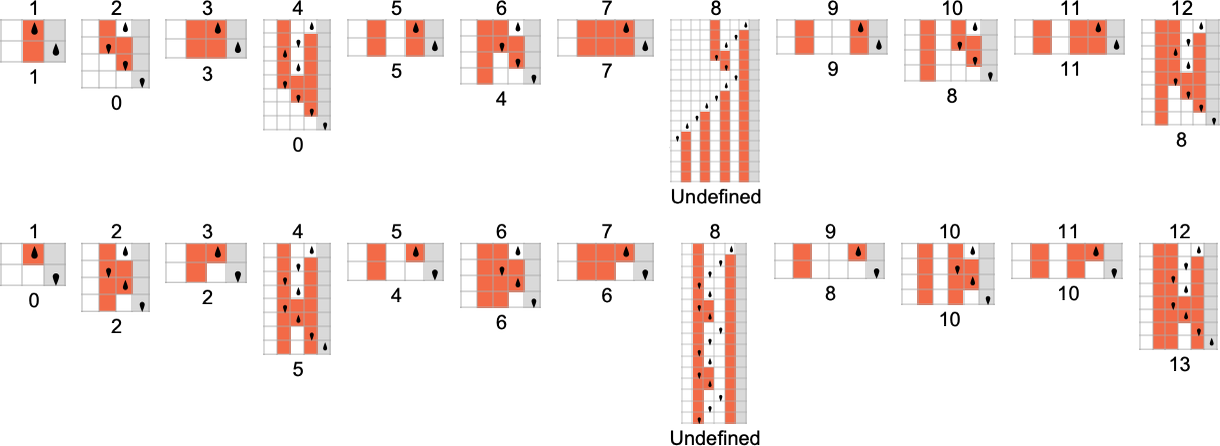
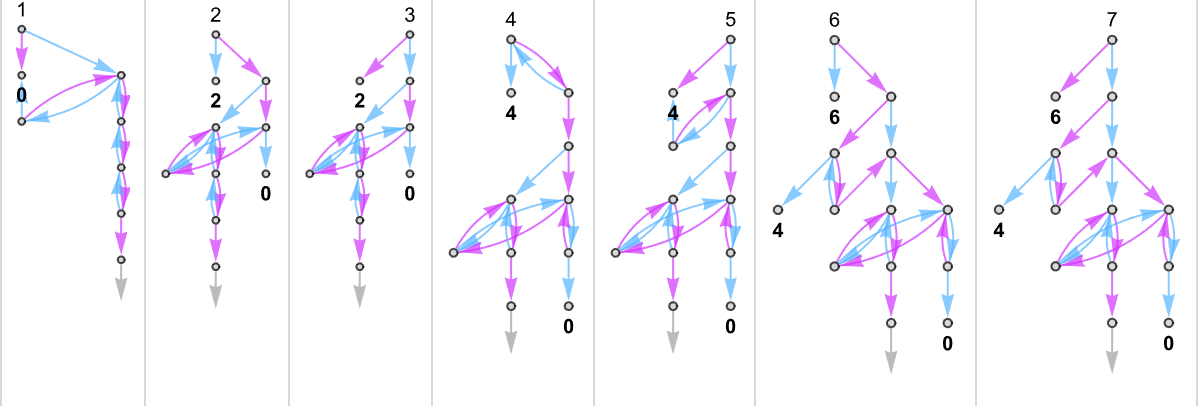
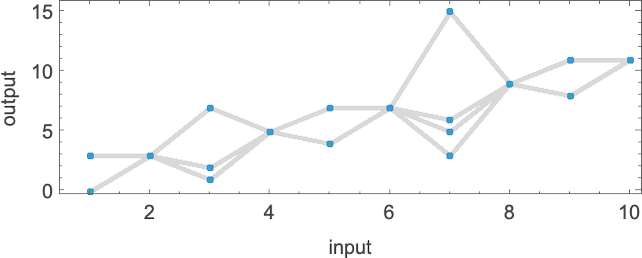
作为我们对多路图灵机进行规则学研究的第一个例子,让我们考虑 s = 1, k = 2 图灵机规则对的情况。有 16 个单独的此类规则,因此有 个(无序)对。以下是所有这些多路图灵机计算的函数:
有时,如机器 {1,9},事实证明对于每个输入都有唯一的输出值:
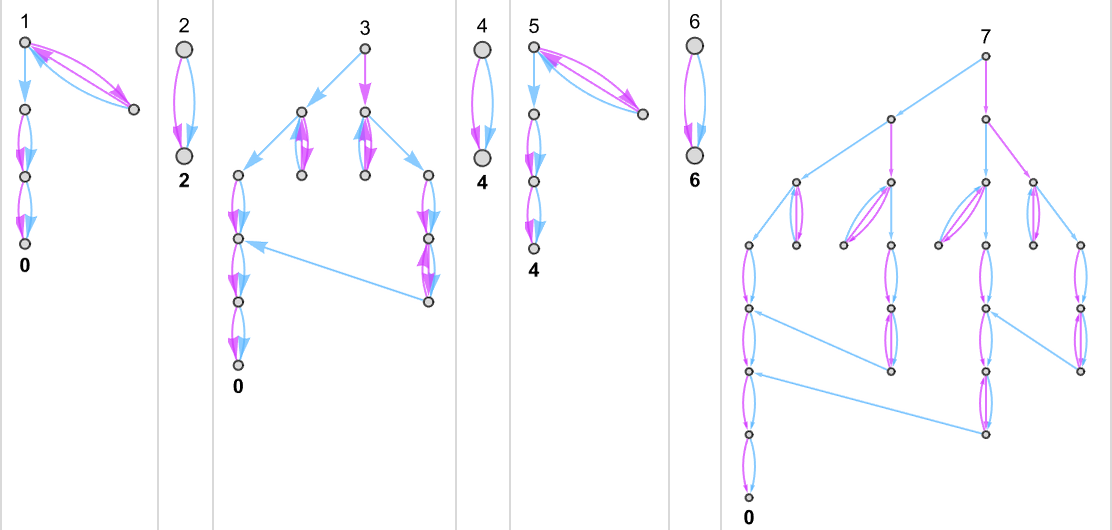
有时,如机器 {5,9},通常有一个唯一值,但有时没有:
{3,7} 也有类似的情况:
有些情况——如 {1,3}——对于某些输入会出现可能输出的“爆发”:
还有很多情况,对于某些输入:
或对于所有输入,都有不停机的分支:
运行时间呢?好吧,对于非确定性图灵机中的每个可能输出,我们可以查看在多路图的任何分支上达到该输出需要多少步,我们可以将该最小数视为计算该输出所需的“非确定性运行时间”。
这是 NP 计算的典型设置:如果你能成功猜到遵循哪个分支,你可能会很快得到答案。但是如果你必须依次检查每个分支,那可能是一个缓慢的过程。
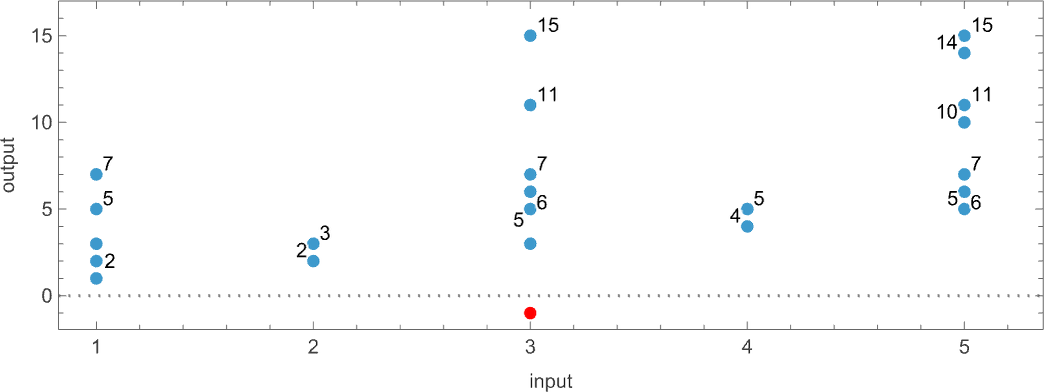
这是一个显示 {3,7} 非确定性机器的一系列输入的可能输出和可能运行时间的例子:

或者,在 3D 中组合:
那么像这样的非确定性机器可以“非确定性地”生成什么函数呢?对于每个输入,我们必须从可能的相应(“多路”)输出中选择一个。实际上,可能的函数对应于穿过这些值的可能“穿线(threadings)”:
或者:

对于每个函数,人们可以将每个输出关联一个“非确定性运行时间”,这里:

非确定性 vs. 确定性机器
我们已经看到非确定性机器通常如何生成多个函数,每个函数的输出都与最小(“非确定性”)运行时间相关联。但是,特定的非确定性机器可以生成的函数与确定性机器可以生成的函数相比如何?或者,换句话说,给定一个非确定性机器可以生成(或“计算”)的函数,需要什么样的确定性机器来计算相同的函数?
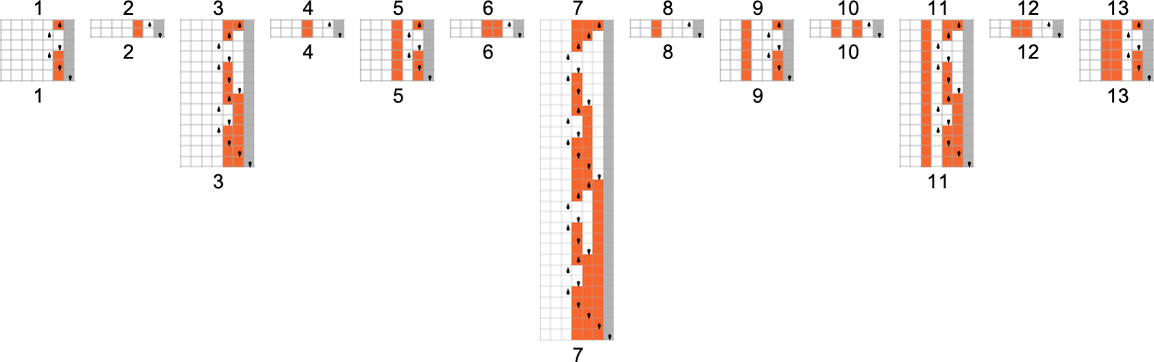
让我们看看我们在上面讨论的 s = 1, k = 2 {3,7} 机器。这是它可以生成的三个函数案例:

我们能找到一个确定性的 s = 1, k = 2 机器来重现其中任何一个函数吗?对于显示的第一个,答案相当简单,是的。因为这个函数是我们通过始终遵循多路系统中的“机器 3”(橙色)分支得到的:
所以它不可避免地给出与确定性机器 3 相同的结果。
但是(除了基于遵循“机器 7”分支的另一个微不足道的情况外),我们可以从这个非确定性机器生成的其他函数都不能被任何 s = 1, k = 2 确定性机器重现。
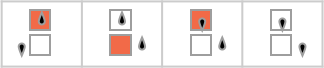
s = 2, k = 2 确定性机器呢?好吧,那里我们运气好一点。因为事实证明,在我们的 {3,7} 非确定性机器中有几个非平凡的选择会导致可以被确定性(s = 2, k = 2)图灵机重现的函数。这是一个可以由 {3,7} 非确定性机器生成的函数示例:
这是通过多路图到达这些值的路径:
“单独的路径”是:
产生“非确定性运行时间”:
这是确定性 s = 2, k = 2 机器 2253 如何重现该函数的数值序列:

这是非确定性机器的一对底层规则:

这是重现它可以生成的特定函数的确定性机器:
这个例子相当简单,并且具有即使是确定性机器也总是具有非常小的运行时间的特征。但现在我们可以问的问题是,一个需要特定类别的确定性机器一定时间来计算的函数,如果其结果是从非确定性机器中“挑选出来”的,是否可以在更短的时间内计算出来。
我们在上面看到 s = 2, k = 2 机器 1511 计算其输出的运行时间随输入大小呈二次增加——我们也看到没有其他(确定性) s = 2, k = 2 机器能更快地计算相同的输出。对于 s = 3, k = 2 机器基本上也是如此(尽管有 6 台机器,其中 1069163 是一个例子,确实设法不是在 步中计算输出,而是在稍微快一点的 步中)。
但是非确定性机器呢?这能有多快?
事实证明,有 15 台基于 s = 1, k = 2 规则对的非确定性机器可以成功重现 s = 2, k = 2 机器 1511 计算的函数。这是一个来自 {0,3} 非确定性机器的例子:
这是在非确定性机器的多路图中被采样以生成确定性图灵机结果的路径:
这是这些“单独的路径”:
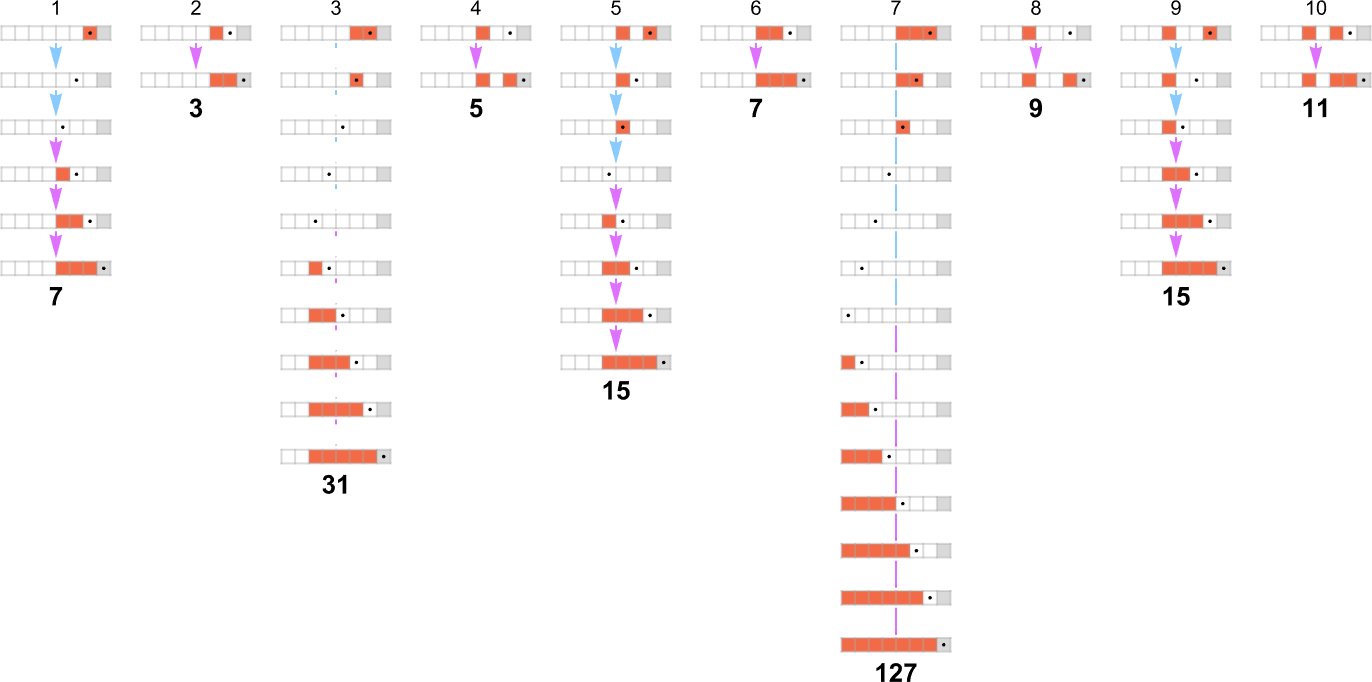
我们可以将这些与确定性机器所需的计算进行比较:
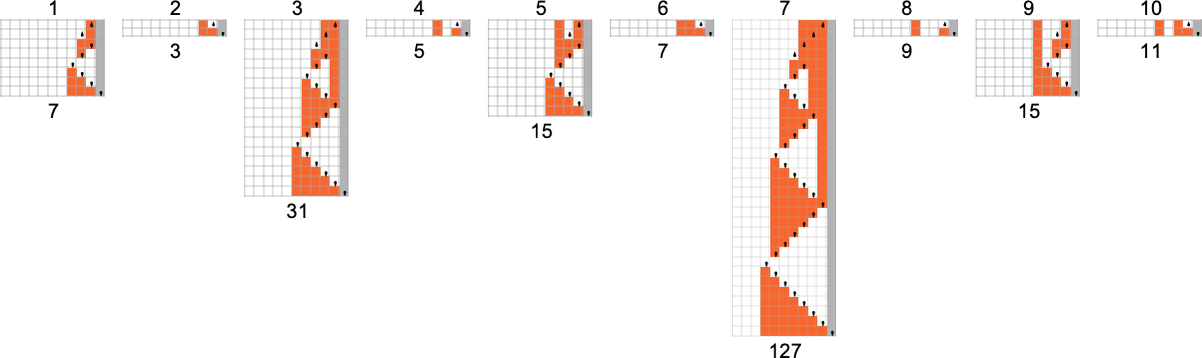
按照我们的渲染,非确定性路径的长度看起来可能更长。但实际上它们要短得多,正如我们将它们(橙色)与确定性运行时间(灰色)一起绘制所看到的那样:
现在查看输入大小 n 的最坏情况运行时间,我们得到:
对于我们在上面找到的大小为 n 的输入的确定性机器,这个最坏情况运行时间由下式给出:
但现在非确定性机器中的运行时间证明是:
换句话说,我们看到非确定性使得计算这个特定函数基本上更快——至少对于小图灵机而言。
在确定性机器中,每一步总是应用相同的底层规则。但在我们使用的设定的非确定性机器中,我们在每一步独立选择两个不同的可能规则之一来应用。结果是对于我们计算的每个函数值,我们都在做一系列选择:
像 P vs. NP 问题这样的核心问题是做出这些选择的自由传递了多少优势——以及例如它是否允许我们“非确定性地”以多项式时间计算那些确定性地需要超过多项式(比如指数)时间来计算的东西。
作为第一个例子,让我们看看由 s = 3, k = 2 确定性机器 1342057 计算的函数。我们上面发现这台机器是一个孤立机器,它需要 的最坏情况运行时间来计算它计算的(诚然相当简单的)函数。那么非确定性机器会发生什么?
嗯,事实证明 s = 1, k = 2 非确定性机器 {0,7} 可以(非确定性地)计算相同的函数:
实际上,虽然确定性机器需要指数增加的运行时间,但非确定性机器的运行时间迅速接近固定常数值 5:
但这是否在某种程度上是微不足道的?如上图所示,非确定性机器(至少最终)生成所有可能的奇数输出值(对于偶数输入 i,也生成 )。但是如果我们查看整个多路图,我们会发现非确定性机器可能需要一段时间才能生成任何特定的输出值:
然而,使运行时间最终为常数的是,在这个特定情况下,输出 总是接近 i(实际上,)。
实际上有不少于 9 台 s = 1, k = 2 非确定性机器可以非确定性地计算相同的函数。它们所有的工作原理本质上都是一样的,生成(至少对于奇数 i)所有可能的输出——运行时间最多为 9。
虽然它们的操作在某种意义上都很简单,但它们说明了这一点:即使一个函数对于确定性图灵机需要指数时间,对于非确定性机器来说可能需要的时间要少得多——甚至对于具有小得多的规则的非确定性机器也是如此。
关于确定性机器需要指数时间的其他函数案例呢?由具有最快运行时间增长的 s = 3, k = 2 确定性机器——600720 和 589111——计算的函数不能由任何基于 s = 1, k = 2 机器对的非确定性机器计算。但由其他运行时间 的确定性机器计算的函数也可以由非确定性机器在常数时间内计算。
对于 s = 3, k = 2 机器 889249 发生了一些略微不同的事情。这台机器具有渐近运行时间 。它计算的函数也可以由 s = 1, k = 2 非确定性机器计算,但现在该机器不是在常数时间内计算函数,而是以 的渐近运行时间计算(是的,对于 i = 1,非确定性机器实际上更慢,需要 5 步而不是 1 步):
非确定性的极限与 Ruliad(规则全集)
确定性图灵机有一个单一的、明确的规则,每一步都应用它。在前面的部分中,我们探索了图灵机中某种意义上最小的非确定性情况——我们允许每一步应用不仅仅是一个,而是两个不同的可能规则。但是如果我们增加非确定性——比如允许每一步有更多可能的规则呢?
我们已经看到确定性——有一个规则——和即使是我们有两个规则的最小非确定性情况之间有很大的区别。但是如果我们加入,比如说,第三个规则,它似乎通常不会产生任何定性的差异。那么关于加入所有可想到的规则的极限情况呢?
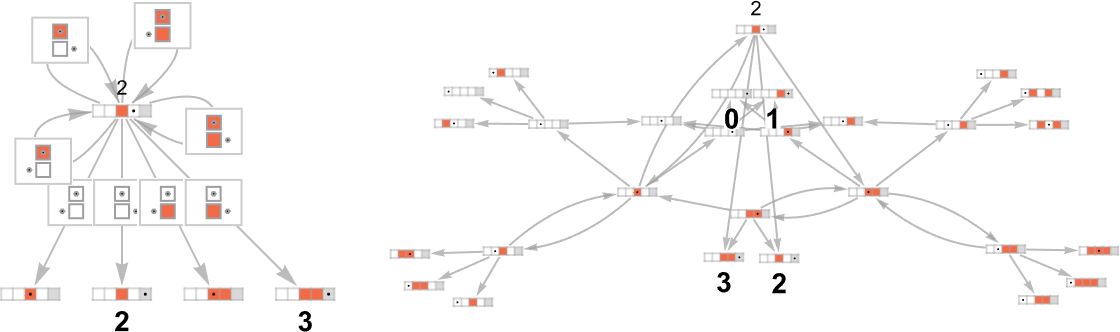
我们可以认为我们得到的是一台“万有机器(everything machine)”——一台拥有任何可能的图灵机的每一个可能的规则情况的机器,比如对于 s = 1, k = 2:
从输入 1 开始运行这台“万有机器”一步,我们得到:
四个规则情况只是导致回到初始状态。然后在其他四个中,两个导致停机状态,两个没有。去掉自环,再走几步,并使用不同的图形渲染,我们看到现在出现了输出 2 和 3:
这是输入 2 的结果:
那么“万有机器”能到达哪里,需要多长时间?答案是,从任何输入 i 它最终可以到达绝对任何输出值 j。所需的最小步数(即多路图中的最小路径长度)只是我们在上面确定的确定性机器运行时间的绝对下界:
从输入 1 开始,到达输出 j 的非确定性运行时间是:
它随输出值对数增长,或随输出大小线性增长。
所以这意味着“万有机器”让人可以非确定性地从给定的输入到给定的输出,且步数为结构上可能的绝对最小值。换句话说,有了足够的非确定性,每个函数都变得非确定性地“容易计算”。
“万有机器”的一个重要特征是我们可以将其视为 Ruliad(规则全集/规则之网)的一个片段。完整的 Ruliad——出现在物理学、数学等的基础中——是所有可能计算的纠缠极限。Ruliad 有许多可能的基;图灵机就是其中之一。在完整的 Ruliad 中,我们必须考虑所有可能的图灵机,所有可能的大小。我们在这里讨论的“万有机器”只给了我们其中的一部分,对应于具有特定数量状态和颜色的所有可能的图灵机规则。
在表示所有可能的计算时,Ruliad——像“万有机器”一样——是最大非确定性的,因此实际上它包括所有可能的计算路径。但是当我们在科学(甚至数学)中应用 Ruliad 时,我们并不那么关心它的整体形式,而是关心它被像我们一样计算受限的观察者采样的特定切片。事实上,在过去几年里,很明显通过这种方式思考可以对许多领域的基础有很多说法。
计算受限观察者的一个特征是它们不是最大非确定性的。它们不遵循多路系统中的所有可能路径,而是倾向于遵循特定的路径或路径束——例如反映了表征我们人类对事物的感知的单一体验线索。所以——当涉及到观察者时——“万有机器”有点太非确定性了。实际(计算受限)的观察者将关注一个或仅几个“历史线索”。换句话说,如果我们对观察者将采样的 Ruliad 切片感兴趣,相关的不是“万有机器”,而是确定性机器,或者至多是我们过去几节研究的那种有限非确定性的机器。
但是“万有机器”能做的事情与所有可能的确定性机器能做的事情相比到底如何?在某种程度上,这是确定性和非确定性之间比较的核心问题。开始经验性地研究它是很直接的。
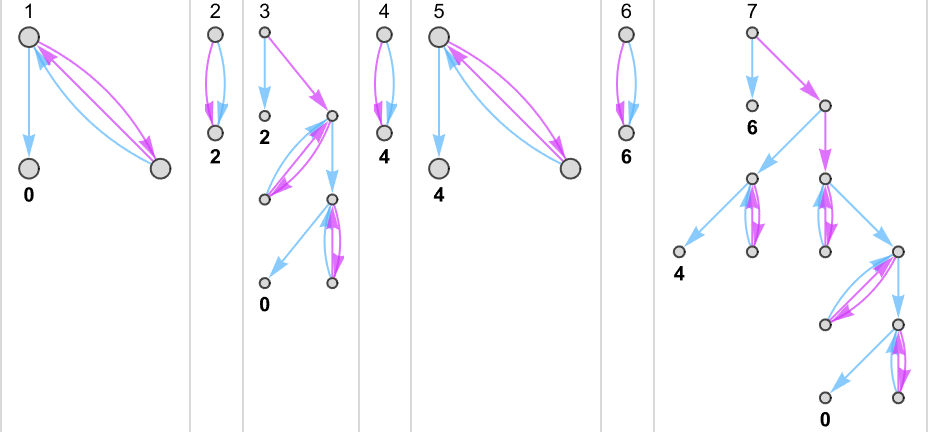
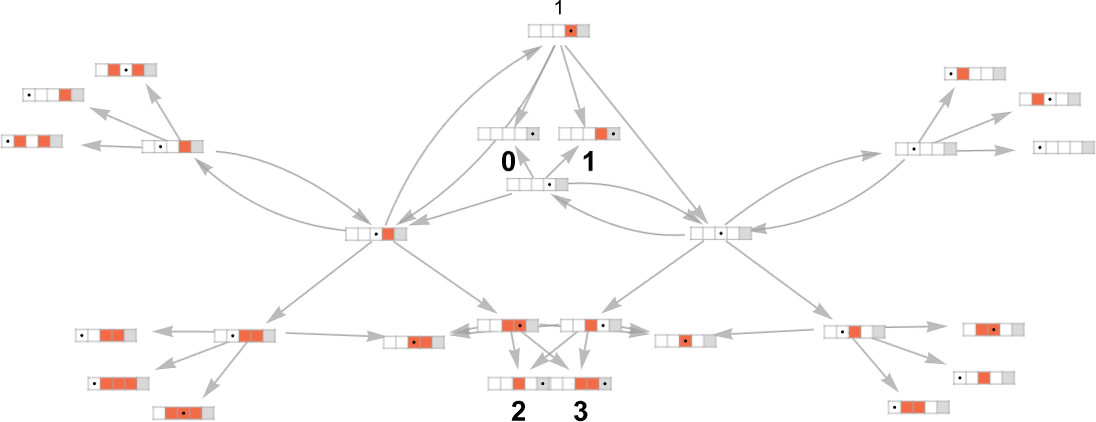
例如,这是 (s = 1, k = 2) “万有机器”多路图中的连续步骤,其中突出显示了与每个可能的确定性 (s = 1, k = 2) 机器相关的路径:
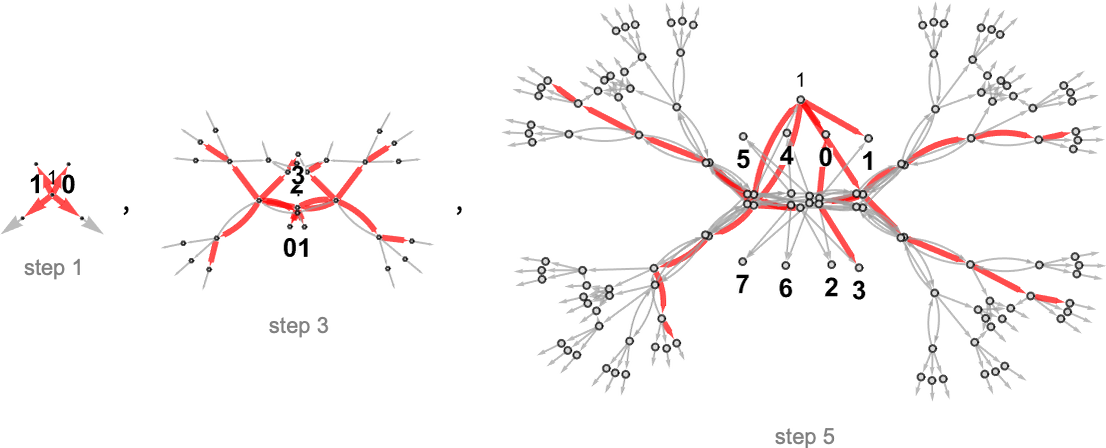
在某种意义上,这些图片说明了确定性与非确定性计算的“覆盖范围(reach)”。在这个特定情况下,对于 s = 1, k = 2,确定性机器从输入 1 唯一能到达的值是 0、1 和 3——尽管非确定性地“万有机器”可以到达每个可能的整数。
对于 s = 2, k = 2,我们得到:
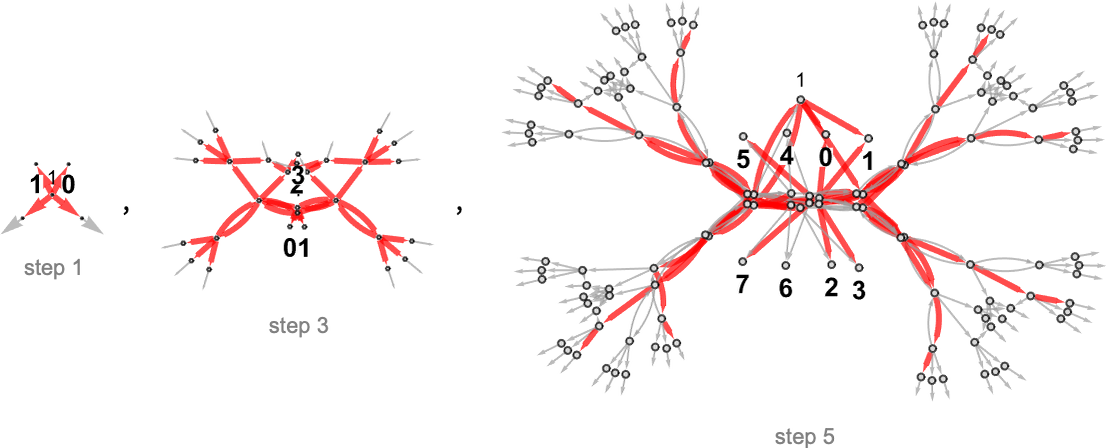
确定性机器可以到达的值是:
但是到达这些值需要多长时间?这用点显示了可能的(确定性)运行时间;填充代表“万有机器”的最小(非确定性)运行时间:
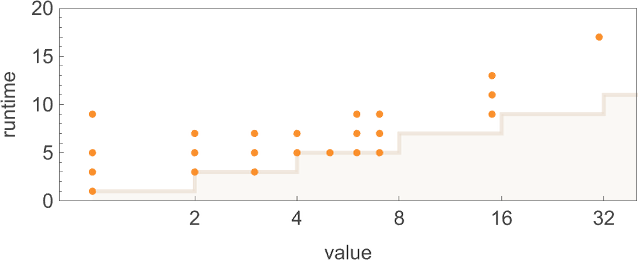
最戏剧性的离群值出现在值 31,它仅由机器 1447 在 15 步中确定性地到达,但可以由“万有机器”在 9 个(非确定性)步中到达:
对于 s = 3, k = 2,确定性和非确定性情况之间的差异增加:

这一切对 P vs. NP 意味着什么?
P vs. NP 问题询问是否每个可以由非确定性图灵机以随输入大小至多呈多项式增加的运行时间完成的计算,也可以由某个确定性图灵机以同样至多呈多项式增加的运行时间完成。或者,更通俗地说,它询问引入非确定性是否可以从根本上加速计算。
在其完整形式中,这是一个无限问题,讨论所有可能的图灵机中所有可能的输入的极限行为。但在那个无限问题中,我们可以问确定的、有限的子问题。我们在这里所做的其中一件事实际上是以明确的、规则学的方式探索这些问题中的一些。查看这些有限子问题无法直接解决完整的 P vs. NP 问题。
但这可以给我们关于 P vs. NP 问题及其涉及的一些困难和微妙之处的重要直觉。当人们分析特定的、构建的算法时,通常会看到它们的运行时间随输入大小变化得相当平滑。但我们在这里看到的一件事是,对于“野外”的任意图灵机,运行时间以复杂的方式跳跃是非常典型的。看到仅针对非常特定的输入出现的剧烈离群值也并不罕见。
如果只有一个离群值,那么在任意大输入大小的极限下,它最终会变得无关紧要。但是如果有一系列不可预测大小、在不可预测位置的离群值呢?最终我们预期各种计算不可约性,这在极限下可能使得在任何特定情况下确定运行时间的极限行为变得无限困难——例如,找出它是否像多项式一样增长。
不过,人们可能会想象,如果观察足够多的输入、足够多的图灵机等,那么某种程度上任何狂野性都会以某种方式被平均掉。但我们的规则学结果并不鼓励这种想法。实际上它们倾向于显示“总有更多的狂野性”,而且它在某种程度上是无处不在的。人们可能曾想象计算不可约性——或不可判定性——会足够罕见,以至于不会影响对像 P vs. NP 这样“全局”问题的调查。但我们的结果表明,相反,有各种各样的复杂细节和“例外”似乎阻碍了一般性结论。
确实,似乎处处都有问题。有些与运行时间中的意外行为和离群值有关。有些与特定机器对于某些输入是否甚至会停机的问题有关。还有一些与取输入大小与图灵机大小的极限,或非确定性的量有关。我们的规则学探索表明,这些问题不是模糊的边缘情况;相反,它们是普遍和无处不在的。
不过,给人的印象是,它们在确定性机器中比在非确定性机器中更明显。非确定性机器在某种意义上“聚合”了路径,并在此过程中洗掉了似乎在确定确定性机器行为中普遍存在的“计算巧合”。
当然,我们对有限大小机器所做的具体实验似乎确实支持这一观点,即确实存在可以由非确定性机器快速完成的计算,但对于确定性机器来说,例如至少偶尔会出现大的运行时间离群值,这意味着更长的一般运行时间。
我一直怀疑 P vs. NP 问题最终会陷入计算不可约性和不可判定性的问题中。但从我们明确的规则学探索中,我们对这可能如何发生有了明确的感觉。最终是否可能基于例如标准数学公理的有限数学风格证明来解决 P vs. NP 问题?这里的结果让我对此表示怀疑。
是的,将有可能获得至少某些受限的全局结果——实际上通过“挖掘”计算可约性的口袋。而且,正如我们在这里反复看到的,对于例如特定的(最终有限的)图灵机类获得确定的结果也是可能的。
我在这里只触及了可以发现的规则学结果的皮毛。在某些情况下,要发现更多只需要消耗更多的计算机时间。但在其他情况下,我们可以预期需要新的方法论,特别是围绕“批量”自动定理证明的方法论。
但我们在这里已经看到的清楚地表明,关于理论计算机科学的问题——其中包括 P vs. NP——可以通过规则学方法学到很多东西。实际上,我们看到理论计算机科学不仅可以“纯理论地”进行——比如用传统数学的方法——而且可以“经验性地”进行,通过做明确的计算实验和枚举来发现结果并发展直觉。
一些个人笔记
我在现在称为规则学(ruliology)方面的努力始于 20 世纪 80 年代初,在早年我几乎完全研究细胞自动机。很大一部分原因只是因为这些是我调查的第一类简单程序,并且在其中我做了一系列发现。我当然知道图灵机,但在我研究自然界和其他地方的实际系统的目标方面,我认为它们与细胞自动机相比联系较少——尽管最终在理论上是等价的。
直到 1991 年,当我开始系统地研究不同类型的简单程序,开始撰写 A New Kind of Science 一书时,我才实际上开始做图灵机的模拟。(尽管它们在理论科学中被广泛使用了半个多世纪,但我认为几乎没有人——从艾伦·图灵开始——真正模拟过它们。)起初我并不特别迷恋图灵机。它们似乎比移动自动机(mobile automata)稍微不那么优雅,并且表现出有趣和复杂行为的倾向比细胞自动机小得多。
然而,到了 20 世纪 90 年代末,我正致力于将我在后来的 A New Kind of Science 中的发现与理论计算机科学的现有结果联系起来——图灵机作为一个有用的桥梁出现了。特别是,作为 A New Kind of Science 最后一章——“计算等价性原理”——的一部分,我有一节题为“不可判定性和难解性”。在那一节中,我使用图灵机作为探索我的结果与计算复杂性理论现有结果之间关系的一种方式。
正是在那个努力的过程中,我发明了我在这里使用的那种单向图灵机:

我专注于 s = 2, k = 2 机器(由于某种原因我从未看过 s = 1, k = 2),并发现了计算相同函数的机器类别——有时以不同的速度:

尽管我当时使用的计算机比我今天使用的慢得多,但我设法将我所做的扩展到 s = 3, k = 2。然而,在每一个转折点,我都面对着计算不可约性和不可判定性。我试图非常努力地做一些事情,比如解决 s = 3, k = 2 机器的确切不同函数数量,但最终没有成功,只是给出了一个“近似”数字:

近三十年后,我想我终于有了确切的数字。(注意,A New Kind of Science 中的一些细节也与我这里有的不同,因为在 A New Kind of Science 中我在枚举中包括了部分函数;这里我主要坚持全函数,即对所有输入都停机并给出确定结果。)
在 A New Kind of Science 于 2002 年发布后,我在 2007 年对图灵机进行了另一次探索,在该书五周年之际设立了一个奖项,用于证明(或反驳)我的怀疑:s = 2, k = 3 机器 596440 能够进行通用计算。该奖项很快被赢得,确立了这台机器作为最简单的通用图灵机:

许多年过去了。我偶尔会向我们在 2003 年开始的暑期研究项目的学生建议关于图灵机的项目(稍后会详细介绍……)。我参加了 2012 年艾伦·图灵百年诞辰的庆祝活动。然后在 2020 年我们宣布了 Wolfram 物理项目——我再次审视了图灵机,现在作为一个可以用超图重写编码的计算系统示例,并使用受物理学启发的因果图等进行研究:

在我们物理项目启动不到两个月后,我正在研究我现在称之为 Ruliad 的东西——并决定使用图灵机作为它的模型:

这其中一个至关重要的部分是多路图灵机的想法:

我在 A New Kind of Science 中介绍了多路系统,并在书中有接近多路图灵机的例子。但现在多路图灵机对我正在做的事情更加核心——事实上我开始研究本质上就是我在这里称之为“万有机器”的东西(尽管细节不同,因为我不考虑可以停机的图灵机):

我也开始研究可以确定性地到达和非确定性地到达的内容之间的比较——并讨论了这与 P vs. NP 问题的潜在关系:

到了第二年,我正在扩大我对多路系统的研究,并探索许多不同的例子——其中之一是多路图灵机:

很快我意识到我所采取的一般方法不仅可以应用于物理学的基础,还可以应用于其他领域的基础。我研究了数学的基础、热力学的基础、机器学习的基础和生物学的基础。但是理论计算机科学的基础呢?
多年来,我探索了理论计算机科学中研究的许多类型系统的规则学——在 2020 年为组合子百年诞辰进行了深入研究,以及(去年)对 Lambda 演算的研究。在所有这些调查中,我不断看到理论计算机科学中讨论的现象的具体版本——即使我的重点往往不同。但我总是好奇对于像 P vs. NP 这样的理论计算机科学核心问题,人们能说些什么。
我曾想象对像 P vs. NP 这样的东西进行经验性调查的主要问题只是枚举足够多的案例。但当我深入研究时,我意识到计算不可约性的阴影比我想象的还要大——即使在特定案例中,弄清楚你需要知道的关于它们行为的事情也可能是不可约地困难。
在项目的相当后期,我试图查找一些关于 NP 问题的“传统智慧”。大部分都是用相当传统的数学术语表述的,似乎不太可能对我正在做的事情有太多帮助。但后来我发现了一篇题为“程序大小与时间复杂性:小图灵机微观世界中的减速和加速现象”的论文——我很兴奋地看到它是对我 A New Kind of Science 中所做工作的跟进,并且正在做规则学。但后来我意识到:论文的主要作者 Joost Joosten 曾是我们 2009 年暑期项目的学生(当时已经是教授),我实际上曾建议过该项目的原始版本(尽管论文把它推进得更远,并且方向与我预期的略有不同)。
不用说,我现在在这里所做的提出了许多新问题,这些问题现在可以由我们在暑期项目及以后的未来项目中解决……
注:有关一般历史背景,请参阅我 2002 年和 2021 年的相关著作。
致谢
感谢 Wolfram Institute 的 Willem Nielsen、Nik Murzin 和 Brian Mboya 提供的广泛帮助。还要感谢 Wolfram Institute 的附属人员 Anneline Daggelinckx,以及 Wolfram Institute 的 Richard Assar 和 Pavel Hajek 提供的额外帮助。Wolfram Institute 在该项目上的工作部分得到了约翰·坦普尔顿基金会的支持。
Lenore & Manuel Blum、Christopher Gilbert、Josh Grochow、Don Knuth 和 Michael Sun 为该项目提供了额外的意见。Matthew Szudzik 也在 1999 年 A New Kind of Science 的开发期间 贡献了相关工作。
引用信息:
Stephen Wolfram (2026), "P vs. NP and the Difficulty of Computation: A Ruliological Approach," Stephen Wolfram Writings. writings.internal.stephenwolfram.com/2026/01/p-vs-np-and-the-difficulty-of-computation-a-ruliological-approach.