我被“人工智能助力科学”的炒作给骗了——这是它给我的教训「Rosetta」
原文链接:I got fooled by AI-for-science hype—here's what it taught me
我在等离子体物理研究中使用了人工智能,结果却出乎我的意料。
我很高兴能发表这篇由尼克·麦克格雷维(Nick McGreivy)撰写的客座文章,他是一位物理学家,去年在普林斯顿大学获得了博士学位。尼克曾经对人工智能能够加速物理研究持乐观态度。但当他尝试将人工智能技术应用于实际物理问题时,结果却令人失望。
我之前写过关于普林斯顿人工智能安全学派的文章,该学派认为人工智能的影响可能与过去的通用技术(如电力、集成电路和互联网)相似。我认为尼克的这篇文章与该学派的思想一脉相承。
——蒂莫西·B·李(Timothy B. Lee)
2018年,作为普林斯顿大学一名研究等离子体物理的二年级博士生,我决定将研究重点转向机器学习。我当时还没有具体的科研项目想法,但我认为利用人工智能加速物理研究可以产生更大的影响。(坦白说,人工智能领域的高薪也是我的动机之一。)
我最终选择研究人工智能先驱杨立昆(Yann LeCun)后来描述为“确实是一个相当热门的话题”的领域:利用人工智能求解偏微分方程(PDE)。但当我试图在我认为是令人印象深刻的成果基础上进行研究时,我发现人工智能方法的表现远不如宣传的那样好。

作者,尼克·麦克格雷维。
起初,我尝试将一种被广泛引用的人工智能方法——物理信息神经网络(PINN)——应用于一些相当简单的偏微分方程,但我发现它出乎意料地脆弱。后来,尽管有数十篇论文声称人工智能方法比标准数值方法更快地求解偏微分方程——在某些情况下甚至快一百万倍——我发现这些比较中的绝大多数都是不公平的。当我在同等条件下将这些人工智能方法与最先进的数值方法进行比较时,人工智能所具有的任何狭隘优势通常都会消失。
这段经历让我开始质疑人工智能即将“加速”甚至“彻底改变”科学的观点。我们真的即将进入DeepMind所称的“人工智能赋能科学发现的新黄金时代”吗?还是说人工智能在科学领域的整体潜力被夸大了——就像在我的子领域一样?
许多其他人也发现了类似的问题。例如,2023年DeepMind声称发现了220万种晶体结构,代表着“人类已知稳定材料数量级上的扩展”。但当材料科学家分析这些化合物时,他们发现这“大部分是垃圾”并且“恭敬地”建议该论文“并未报告任何新材料”。
另外,普林斯顿大学的计算机科学家阿尔温德·纳拉亚南(Arvind Narayanan)和萨亚什·卡普尔(Sayash Kapoor)整理了一份清单,其中包含30个领域的648篇论文,这些论文都犯了一种名为数据泄露的方法论错误。在每种情况下,数据泄露都会导致过于乐观的结果。他们认为,基于人工智能的科学正面临一场“可重复性危机”。
然而,在过去十年中,人工智能在科学研究中的应用一直在急剧上升。计算机科学当然是影响最大的领域,但其他学科——物理学、化学、生物学、医学和社会科学——的人工智能应用也在迅速增加。在所有科学出版物中,人工智能的使用率从2015年的2%增长到2022年的近8%。近几年的数据更难找到,但我们有充分的理由相信这种曲棍球棒式的增长仍在继续。
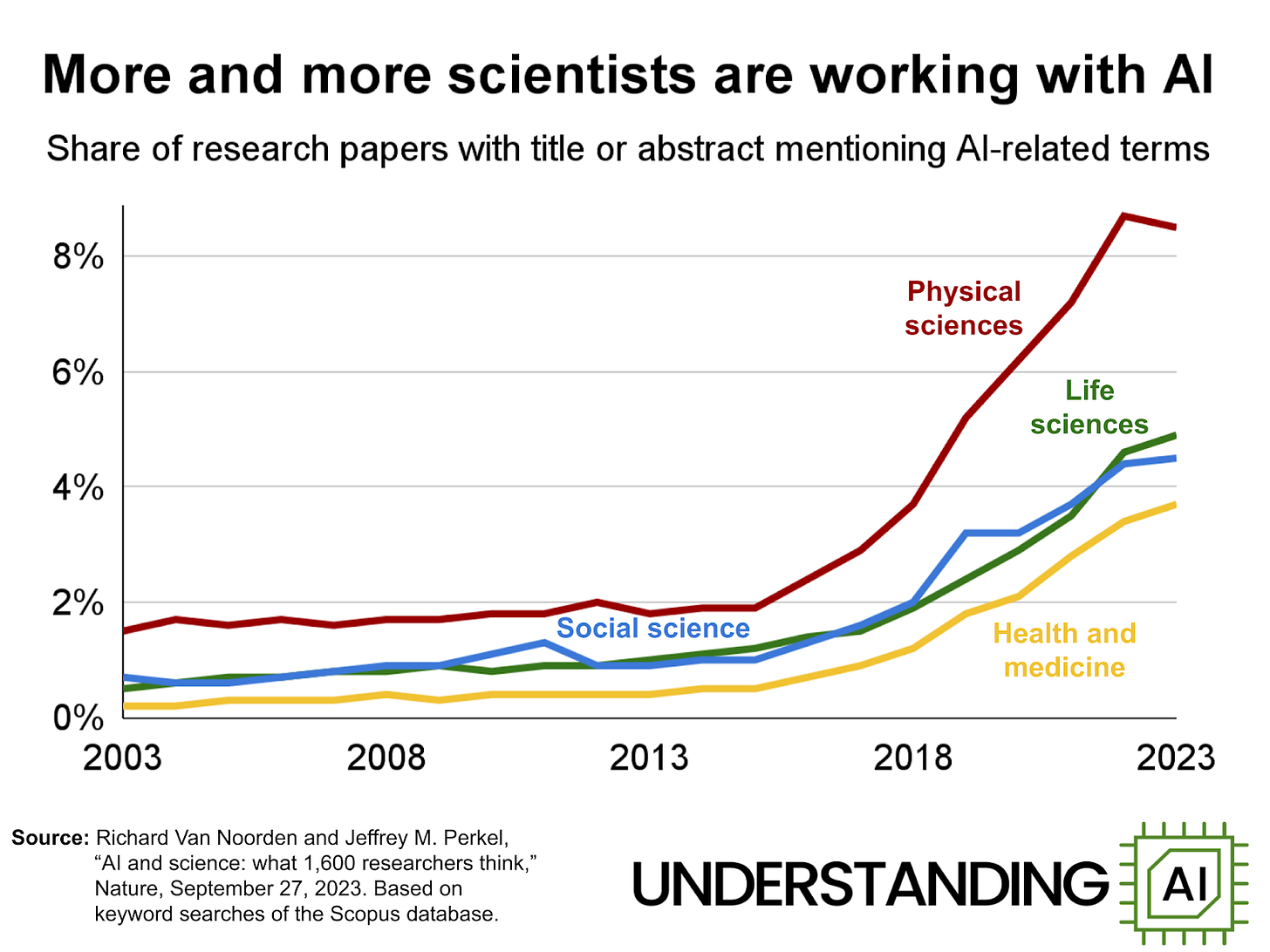
需要明确的是,人工智能可以推动科学突破。我担心的是它们的规模和频率。人工智能真的展现出足够的潜力,值得我们将如此大量的人才、培训、时间和资金从现有的研究方向转移到一个单一的范式上吗?
每个科学领域对人工智能的体验都不同,因此我们应该对一概而论持谨慎态度。然而,我相信我经验中的一些教训在整个科学领域具有广泛的适用性:
- 人工智能在科学家中的应用正在爆炸式增长,这与其说是因为它有益于科学,不如说是因为它有益于科学家自身。
- 由于人工智能研究人员几乎从不发表负面结果,“人工智能助力科学”领域正在经历幸存者偏差。
- 发表的正面结果往往对人工智能的潜力过于乐观。
因此,我开始相信,人工智能在科学领域的成功和革命性通常不如表面上看起来那么大。
最终,我不知道人工智能是否会扭转数十年来科学产出下降和科学进步速度停滞(甚至减速)的趋势。我想没有人知道。但是,除非在先进人工智能方面取得重大(在我看来不太可能)的突破,否则我预计人工智能更像是一个用于渐进式、不均衡科学进步的普通工具,而非革命性的工具。
我在PINN上的失望经历
2019年夏天,我第一次接触到后来成为我博士论文主题的领域:用人工智能求解偏微分方程。偏微分方程是用于模拟各种物理系统的数学方程,求解(即模拟)它们是计算物理和工程领域一项极其重要的任务。我的实验室使用偏微分方程来模拟等离子体的行为,例如聚变反应堆内部和外太空星际介质中的等离子体。
用于求解偏微分方程的人工智能模型是定制的深度学习模型,更类似于AlphaFold而不是ChatGPT。
我尝试的第一个方法叫做物理信息神经网络(PINN)。PINN最近在一篇有影响力的论文中被提出,该论文已经获得了数百次引用。
与标准数值方法相比,PINN是一种截然不同的求解偏微分方程的方法。标准方法将偏微分方程的解表示为一组像素(就像图像或视频中的像素一样),并为每个像素值推导出方程。相比之下,PINN将偏微分方程的解表示为一个神经网络,并将方程放入损失函数中。
作为一个甚至还没有导师的幼稚研究生,PINN对我来说具有不可思议的吸引力。它们看起来如此简单、优雅和通用。
它们似乎也取得了不错的结果。介绍PINN的论文发现,它们的“有效性”已经“通过一系列流体力学、量子力学、反应扩散系统和非线性浅水波传播等经典问题得到了证明”。我想,如果PINN已经解决了所有这些偏微分方程,那么它们肯定也能解决我的实验室关心的一些等离子体物理偏微分方程。
但是,当我用一个不同的、但仍然极其简单的偏微分方程(一维弗拉索夫方程)替换那篇有影响力的第一篇论文中的一个例子(一维伯格斯方程)时,结果与精确解完全不同。最终,经过大量的调整,我才得到了一些看起来正确的结果。然而,当我尝试更复杂的偏微分方程(例如一维弗拉索夫-泊松方程)时,无论如何调整都无法得到一个像样的解。
经过几周的失败后,我联系了另一所大学的一位朋友,他告诉我他也尝试过使用PINN,但未能获得好的结果。
我从PINN实验中学到的
最终,我意识到问题出在哪里。最初PINN论文的作者和我一样,“观察到对于一个方程产生令人印象深刻结果的特定设置,对于另一个方程可能会失败。”但由于他们想让读者相信PINN有多么令人兴奋,他们并没有展示任何PINN失败的例子。
这段经历教会了我一些事情。首先,要谨慎对待人工智能研究的表面价值。大多数科学家并非有意误导任何人,但由于他们面临着展示有利结果的强大激励,你仍然有被误导的风险。展望未来,我必须更加怀疑,即使(或者说尤其是)是那些结果令人印象深刻的高影响力论文。
其次,人们很少发表关于人工智能方法失败的论文,只发表它们成功时的论文。最初PINN论文的作者并没有发表关于他们的方法未能解决的偏微分方程的论文。我也没有发表我失败的实验,只在一个不知名的会议上展示了一张海报。所以很少有研究人员听说过它们。事实上,尽管PINN非常受欢迎,但过了四年才有人发表一篇关于其失败模式的论文。那篇论文现在有近千次引用,这表明许多其他科学家也尝试了PINN并发现了类似的问题。
第三,我得出结论,PINN不是我想使用的方法。它们确实简单而优雅,但它们也太不可靠、太挑剔和太慢。
截至今天,六年后,最初的PINN论文已经获得了惊人的14000次引用,使其成为21世纪被引用次数最多的数值方法论文(而且,据我计算,再过一两年将成为有史以来被引用次数第二多的数值方法论文)。
尽管现在人们普遍认为PINN在求解偏微分方程方面通常不如标准数值方法具有竞争力,但对于另一类称为反问题的问题,PINN的表现如何仍存在争议。支持者声称PINN对于反问题“特别有效”,但一些研究人员强烈质疑这一观点。
我不知道争论的哪一方是正确的。我愿意相信所有这些PINN研究已经产生了一些有用的东西,但如果有一天我们回顾PINN,发现它仅仅是一个巨大的引用泡沫,我也不会感到惊讶。
薄弱的基线导致过度乐观
在我的博士论文中,我专注于使用深度学习模型求解偏微分方程,这些模型像传统求解器一样,将偏微分方程的解视为网格或图形上的一组像素。
与PINN不同,这种方法在我实验室关心的复杂、瞬态偏微分方程上显示出很大的潜力。最令人印象深刻的是,一篇又一篇论文都证明了其求解偏微分方程的速度比标准数值方法更快——通常快几个数量级。
最让我的导师和我兴奋的例子是流体力学中的偏微分方程,例如纳维-斯托克斯方程。我们认为我们可能会看到类似的加速,因为我们关心的偏微分方程——例如描述聚变反应堆中等离子体的方程——具有相似的数学结构。理论上,这可以让我们这样的科学家和工程师模拟更大的系统,更快地优化现有设计,并最终加快研究步伐。
到这个时候,我已经有足够的经验知道,在人工智能研究中,事情并不总是像看起来那么美好。我知道可靠性和鲁棒性可能是严重的问题。如果人工智能模型能提供更快的模拟,但这些模拟的可靠性较低,这是否值得权衡?我不知道答案,并着手去寻找。
但是,当我尝试——并且大多失败了——使这些模型更可靠时,我开始质疑人工智能模型在加速偏微分方程求解方面到底展现了多少潜力。
根据一些备受瞩目的论文,人工智能已经比标准数值方法快几个数量级地解决了纳维-斯托克斯方程。然而,我最终发现,这些论文中使用的基线方法并非可用的最快数值方法。当我将人工智能与更先进的数值方法进行比较时,我发现人工智能并不比更强的基线更快(或者最多只快一点点)。
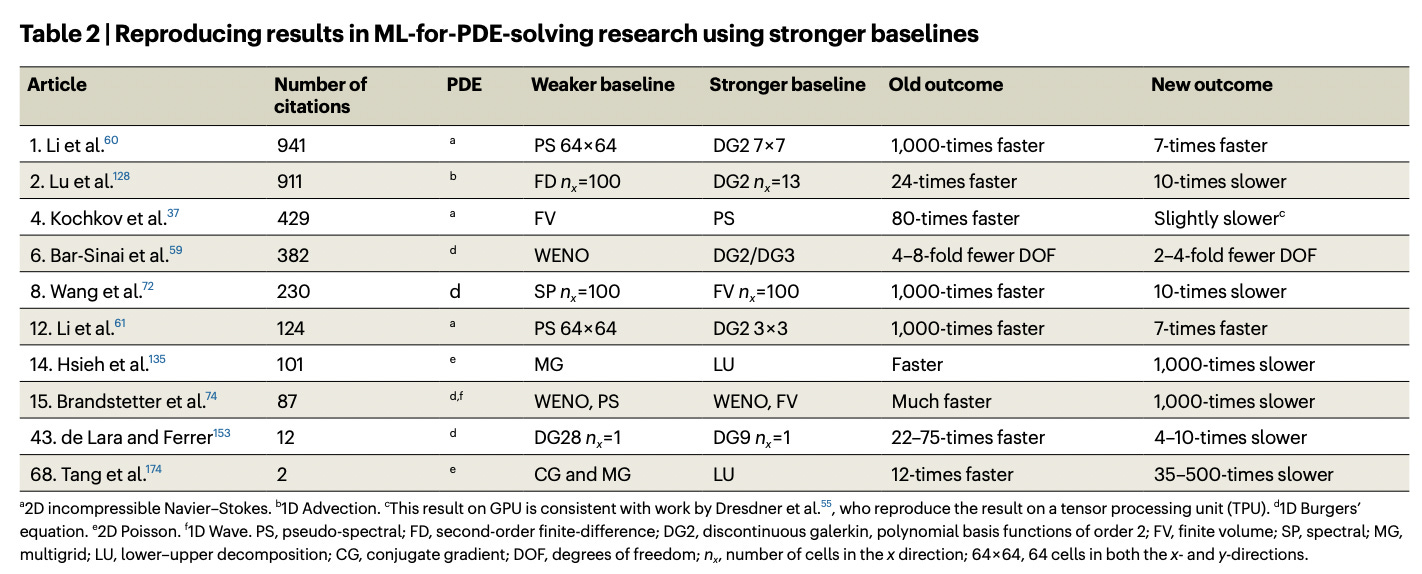
当用于求解偏微分方程的人工智能方法与强基线进行比较时,人工智能所具有的任何狭隘优势通常都会消失。
我和我的导师最终发表了一篇关于使用人工智能求解流体力学偏微分方程研究的系统综述。我们发现,在声称优于标准数值方法的76篇论文中,有60篇(79%)使用了薄弱的基线,要么是因为它们没有与更先进的数值方法进行比较,要么是因为它们没有在同等条件下进行比较。具有大幅加速效果的论文都与薄弱的基线进行了比较,这表明结果越令人印象深刻,论文进行不公平比较的可能性就越大。
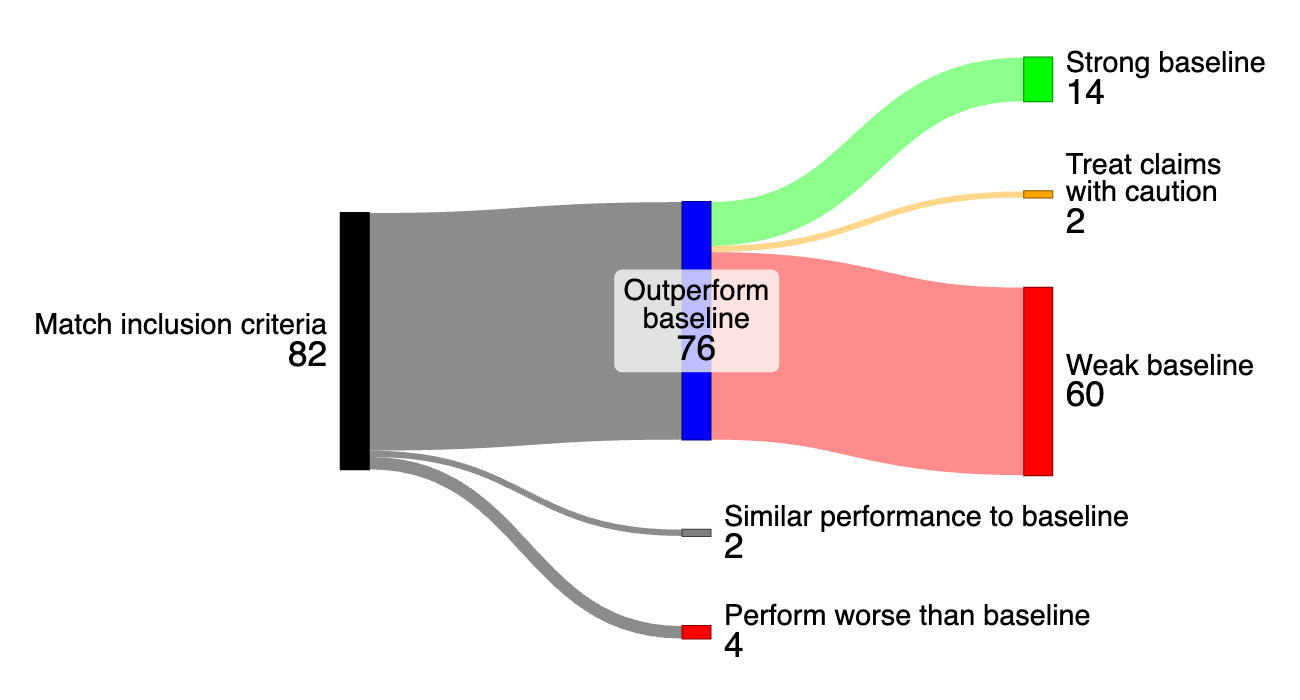
一项关于比较用于求解流体力学偏微分方程的人工智能方法与标准数值方法的研究的系统综述结果。很少有论文报告负面结果,而报告正面结果的论文大多与薄弱的基线进行比较。
我们还再次发现证据表明,研究人员倾向于不报告负面结果,这种效应被称为报告偏差。我们最终得出结论,人工智能用于偏微分方程求解的研究过于乐观:“薄弱的基线导致过于积极的结果,而报告偏差导致负面结果报告不足。”
这些发现引发了一场关于人工智能在计算科学与工程领域应用的辩论:
- 乔治华盛顿大学教授洛雷娜·巴巴(Lorena Barba)此前曾讨论过她称之为“愚弄大众的科学机器学习”中不良的研究实践,她认为我们的结果是“支持我们在计算科学界对人工智能的炒作和不科学乐观主义担忧的坚实证据”。
- 谷歌研究院一个独立得出类似结论的团队负责人斯蒂芬·霍耶(Stephan Hoyer),将我们的论文描述为“很好地总结了我为何从[人工智能]用于偏微分方程转向天气预报和气候建模的原因”,这些人工智能应用似乎更有前景。
- JKU林茨大学教授、一家提供“人工智能驱动的物理模拟”的初创公司联合创始人约翰内斯·布兰德施泰特(Johannes Brandstetter)认为,人工智能可能会在更复杂的工业应用中取得更好的结果,并且“该领域的未来无疑仍然充满希望,并具有巨大的潜在影响。”
在我看来,人工智能最终可能对某些与求解偏微分方程相关的应用有用,但我目前没有太多理由感到乐观。我希望看到更多地关注于努力匹配数值方法的可靠性,以及对人工智能方法进行红队测试;目前,它们既没有标准数值方法的理论保证,也没有经过经验验证的鲁棒性。
我还希望看到资助机构激励科学家为偏微分方程创建挑战性问题。一个好的模型可以是CASP,这是一个每两年举办一次的蛋白质折叠竞赛,在过去30年中帮助激励和集中了该领域的研究。
人工智能会加速科学发展吗?
除了作为人工智能科学突破的典型例子的蛋白质折叠之外,人工智能在科学进步方面的一些例子包括:1
- 天气预报,其中人工智能预报的准确率比传统的基于物理的预报高出20%(尽管分辨率仍然较低)。
- 药物发现,其中初步数据表明,人工智能发现的药物在I期(但不是II期)临床试验中更成功。如果这一趋势持续下去,这将意味着端到端药物批准率几乎翻倍。
但是人工智能公司、学术和政府组织以及媒体越来越将人工智能不仅视为一种有用的科学工具,而且是一种“将对科学产生变革性影响”的工具。
我认为我们不一定应该摒弃这些说法。根据DeepMind的说法,虽然目前的LLM“在人类科学家所依赖的更深层次的创造力和推理方面仍然存在困难”,但假设的先进人工智能系统有朝一日可能能够完全自动化科学过程。我不认为这会很快发生——如果会发生的话。但如果这样的系统被创造出来,毫无疑问它们会改变和加速科学。
然而,根据我研究经验中的一些教训,我认为我们应该对更传统的人工智能技术正以显著速度加速科学进步的观点持相当怀疑的态度。
关于人工智能在科学领域的教训
关于人工智能加速科学的大多数叙事都来自人工智能公司或从事人工智能工作的科学家,他们直接或间接地从这些叙事中受益。例如,NVIDIA首席执行官黄仁勋谈到“人工智能将推动科学突破”以及“将科学加速一百万倍”。NVIDIA因其财务利益冲突而成为一个特别不可靠的叙述者,它经常对人工智能在科学领域的应用发表夸张的言论。
你可能会认为,科学家对人工智能日益增长的应用是人工智能在科学领域有用性的证据。毕竟,如果人工智能在科学研究中的使用呈指数级增长,那一定是因为科学家发现它有用,对吧?
我不太确定。事实上,我怀疑科学家转向人工智能与其说是因为它有益于科学,不如说是因为它有益于他们自己。2
想想我2018年转向人工智能的动机。虽然我真心认为人工智能可能对等离子体物理有用,但我主要还是被更高的薪水、更好的工作前景和学术声望所驱动。我还注意到,我实验室的高层通常似乎更关心人工智能的筹款潜力而不是技术因素。
后来的研究发现,使用人工智能的科学家更有可能发表高被引论文,并且平均获得的引用次数是其他人的三倍。在如此强大的激励下使用人工智能,这么多科学家这样做也就不足为奇了。
因此,即使人工智能在科学领域取得了真正令人印象深刻的成果,这并不意味着人工智能为科学做出了有用的贡献。更多时候,它只反映了人工智能未来可能发挥作用的潜力。
这是因为从事人工智能工作的科学家(包括我自己)通常是反向工作的。我们不是先确定一个问题,然后再尝试找到解决方案,而是首先假设人工智能将是解决方案,然后寻找需要解决的问题。但是,由于很难确定可以用人工智能解决的开放性科学挑战,这种“拿着锤子找钉子”式的科学意味着研究人员通常会处理那些适合使用人工智能但要么已经被解决,要么不会产生新科学知识的问题。
为了准确评估人工智能在科学领域的影响,我们需要真正审视科学本身。但不幸的是,科学文献并非评估人工智能在科学领域成功与否的可靠来源。
一个问题是幸存者偏差。正如一位研究人员所说,人工智能研究“几乎完全不发表负面结果”,因此我们通常只看到人工智能在科学领域的成功案例,而看不到失败案例。但是,如果没有负面结果,我们评估人工智能在科学领域影响的尝试通常会失真。
任何研究过可重复性危机的人都知道,幸存者偏差是科学领域的一个主要问题。通常,罪魁祸首是一个选择过程,在这个过程中,统计上不显著的结果会被从科学文献中过滤掉。
例如,下面显示了医学研究中z值的分布。z值在-1.96和1.96之间表示结果不具有统计显著性。这些值附近的急剧不连续性表明,许多科学家要么没有发表这些值之间的结果,要么修改了他们的数据,直到它们达到统计显著性的门槛。
问题在于,如果研究人员未能发表负面结果,可能会导致医疗从业者和公众高估医疗治疗的有效性。
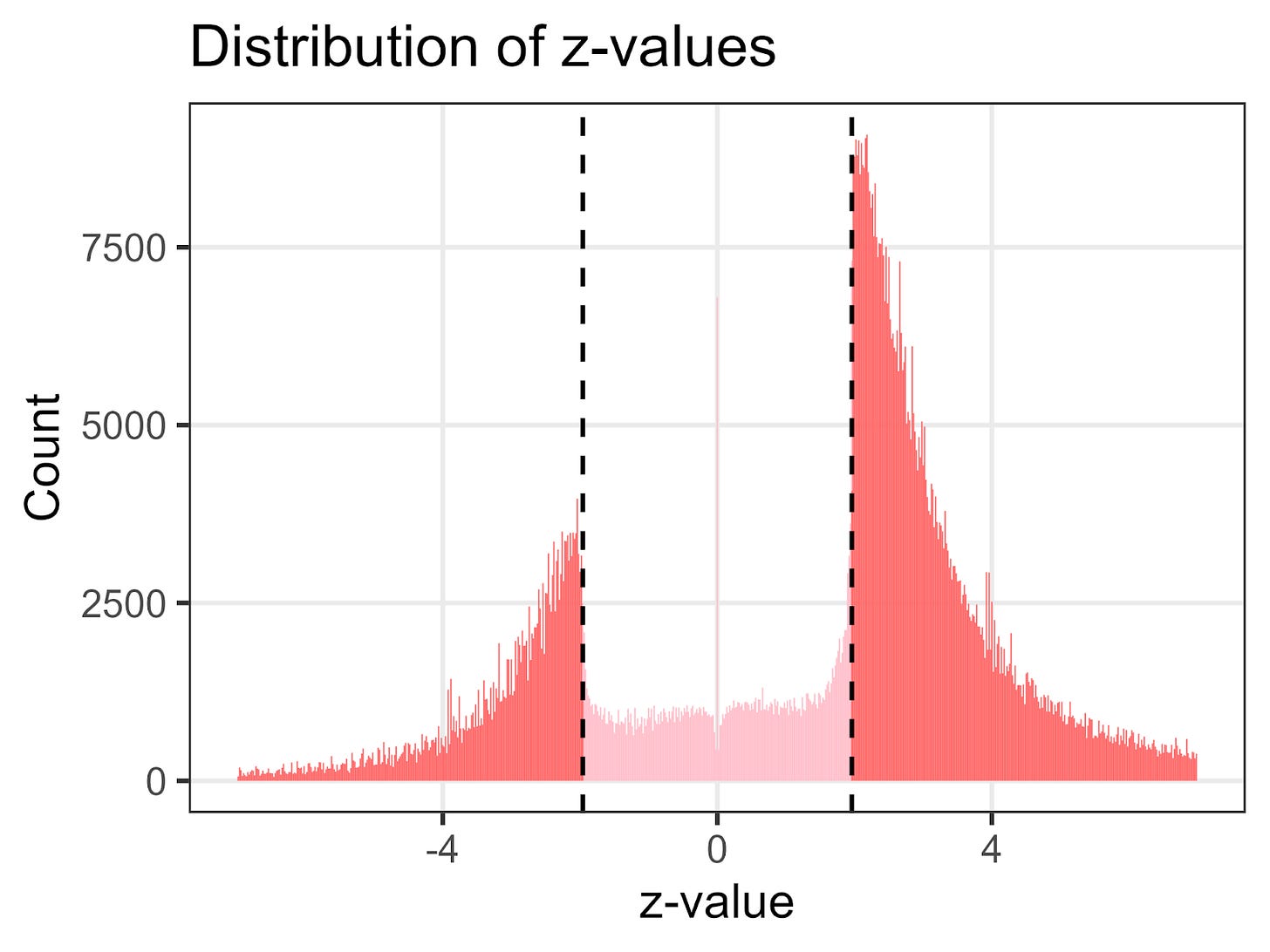
来自医学研究的超过100万个z值的分布。负面结果——z值在-1.96和1.96之间——大部分缺失。(图表由Adrian Barnett和David Borg制作,基于Erik W. van Zwet和Eric A. Cator的数据。)
类似的情况也发生在“人工智能助力科学”领域,尽管其选择过程并非基于统计显著性,而是基于所提出的方法是否优于其他方法或成功执行了某些新颖的任务。这意味着“人工智能助力科学”的研究人员几乎总是报告人工智能的成功案例,而很少发表人工智能不成功时的结果。
第二个问题是,各种陷阱常常导致那些确实发表的成功结果对人工智能在科学领域的应用得出过于乐观的结论。细节和严重程度似乎因领域而异,但这些陷阱大多可归为四类:数据泄露、薄弱的基线、挑选数据和错误报告。

评估人工智能模型的人同时也是从这些评估中受益的人。
虽然这种过度乐观倾向的原因很复杂,但核心问题似乎是利益冲突,即评估人工智能模型的人同时也是从这些评估中受益的人。
这些问题似乎足够严重,以至于我鼓励人们像对待营养科学中令人惊讶的结果一样,对待“人工智能助力科学”领域中令人印象深刻的结果:抱持本能的怀疑态度。
- 1:本文的早期草稿在此处列举了三个例子,其中包括麻省理工学院研究生艾丹·托纳-罗杰斯(Aidan Toner-Rodgers)的一篇关于利用人工智能发现新材料的论文。该论文曾被描述为“迄今为止关于人工智能对科学发现影响的最佳论文”。但随后麻省理工学院宣布由于担心“研究的完整性”,正在寻求撤回该论文。当然,直接欺诈的指控与我在文章中关注的更微妙的方法论问题是不同的。但这篇论文在媒体上引起如此大的关注,突显了我的更广泛观点,即研究人员有各种各样的动机来夸大人工智能技术的有效性。
- 2:当我谈论科学家使用人工智能时,我指的是训练或使用专用的人工智能模型,例如PINN或AlphaFold。我不是指使用LLM来帮助撰写研究经费申请或进行基础背景研究。