Claude Opus 4.5,以及为什么评估新的大语言模型越来越困难「Simon Willison」
- 来源:Claude Opus 4.5, and why evaluating new LLMs is increasingly difficult
- 作者:Simon Willison
- 日期:2025年11月24日
Anthropic 今早发布了 Claude Opus 4.5,称其为“世界上最适合编码、智能体(Agents)和计算机操作的模型”。这是他们在经历了来自 OpenAI 的 GPT-5.1-Codex-Max 和 Google 的 Gemini 3(均在过去一周内发布!)的巨大挑战后,试图夺回最佳编码模型桂冠的一次尝试。
Opus 4.5 的核心特征包括 200,000 token 的上下文窗口(与 Sonnet 相同),64,000 token 的输出限制(也与 Sonnet 相同),以及 2025 年 3 月的“可靠知识截止日期”(Sonnet 4.5 是 1 月,Haiku 4.5 是 2 月)。
定价让人松了一口气:输入每百万 token 5 美元,输出每百万 token 25 美元。这比之前定价为 15/75 美元的 Opus 便宜得多,也使其与 GPT-5.1 系列(1.25/10 美元)和 Gemini 3 Pro(2/12 美元,超过 200,000 token 时为 4/18 美元)相比稍微更有竞争力。作为对比,Sonnet 4.5 是 3/15 美元,Haiku 4.5 是 1/5 美元。
Opus 4.5 相比 Opus 4.1 的关键改进文档中还有一些更有趣的细节:
- Opus 4.5 有一个新的努力(effort)参数,默认为高(high),但可以设置为中(medium)或低(low)以获得更快的响应。
- 该模型支持增强的计算机操作,具体来说是一个
zoom(缩放)工具,你可以将其提供给 Opus 4.5,允许它请求放大屏幕的某个区域进行检查。 - “前几轮助手对话中的思考块(Thinking blocks)默认保留在模型上下文中”——显然之前的 Anthropic 模型会丢弃这些内容。
周末我获得了 Anthropic 新模型的预览权限。我花了很多时间在 Claude Code 中使用它,最终发布了 sqlite-utils 的一个新的 alpha 版本,其中包括几次大规模的重构——在两天的20 次提交、39 个文件变动、2,022 行增加和 1,173 行删除中,Opus 4.5 完成了大部分工作。这是Claude Code 的文字记录,记录了我让它帮助实现其中一个较复杂新功能的过程。
这显然是一个极其出色的新模型,但我遇到了一个问题。我的预览权限在周日晚上 8 点过期了,当时alpha 版的里程碑中还有几个遗留问题。我切换回 Claude Sonnet 4.5,然后……继续以使用新模型时相同的速度工作。
事后看来,这种生产环境下的编码工作,在评估新模型优势方面,并不像我预期的那样有效。
我并不是说新模型没有比 Sonnet 4.5 进步——但我无法自信地说,我提出的挑战能够识别出两者在能力上的显著差异。
这对来说代表着一个日益严重的问题。我最喜欢的 AI 时刻是当一个新模型赋予我做以前根本无法做到的事情的能力时。过去这些时刻感觉非常明显,但今天通常很难找到具体的例子来区分新一代模型和它们的前辈。
Google 的 Nano Banana Pro 图像生成模型值得注意,因为它渲染可用信息图表的能力确实代表了一项之前的模型处理得极其糟糕的任务。
前沿的大语言模型(LLMs)彼此之间更难区分。像 SWE-bench Verified 这样的基准测试显示模型之间的差距仅为个位数的百分点,但这对于我每天需要解决的现实世界问题实际上意味着什么呢?
老实说,这主要怪我。我在维护自己那套超出前沿模型能力的任务集方面落后了。我以前有一大堆这样的任务,但它们被逐一攻破,现在我在有助于评估新模型的合适挑战方面显得尴尬地匮乏。
我经常建议人们把模型失败的任务存到笔记里,以便以后在更新的模型上尝试——这是我从 Ethan Mollick 那里学到的技巧。我自己需要加倍重视这个建议!
我很希望看到像 Anthropic 这样的 AI 实验室直接应对这一挑战。我希望看到新模型发布时附带具体的任务示例,这些任务是该模型能解决而同一提供商的上一代模型无法处理的。
“这是一个在 Sonnet 4.5 上失败但在 Opus 4.5 上成功的提示词示例”,这会比在 MMLU 或 GPQA Diamond 等名字的基准测试上提高个位数百分比更让我兴奋得多。
与此同时,我只能继续让它们画 SVG 了。这是 Opus 4.5(在其默认的“高”努力级别下):

它在新的更详细的提示词下表现得好多了:

这里是同一个复杂提示词对抗 Gemini 3 Pro 和对抗 GPT-5.1-Codex-Max-xhigh 的结果。
仍然容易受到提示词注入攻击
摘自 Anthropic 公告文章的安全部分:
随着 Opus 4.5 的发布,我们在抵御提示词注入攻击的鲁棒性方面取得了实质性进展,这种攻击通过偷运欺骗性指令来愚弄模型表现出有害行为。Opus 4.5 比业内任何其他前沿模型都更难被提示词注入欺骗:
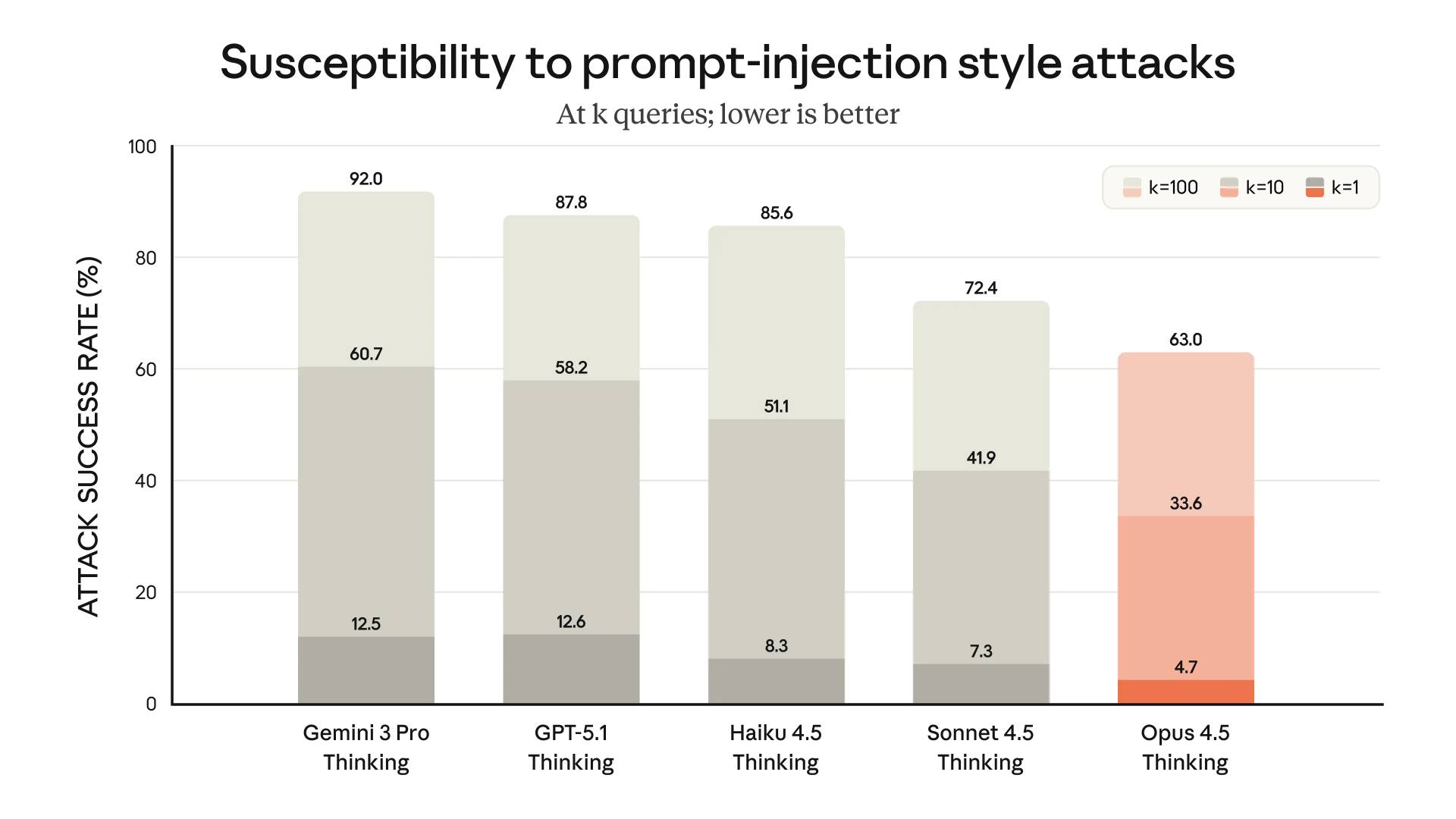
一方面这看起来很棒,相比之前的模型和竞争对手有了明显的改进。
但这张图表实际上告诉了我们什么呢?它告诉我们单次尝试提示词注入仍然有 1/20 的成功率,如果攻击者可以尝试十种不同的攻击,成功率会上升到 1/3!
我仍然认为训练模型不陷入提示词注入陷阱并不是解决之道。我们需要继续在设计应用程序时假设:一个有足够动力的攻击者将能够找到欺骗模型的方法。